In this post, I will talk about Improving Cache Performance.

There are many conditions to imporve our cache memory performance.
In the previous post, I take a MIPS architecture and the blocks in the MIPS architecture can accept one word address. However, if the blocks can accpet many word, what happens?
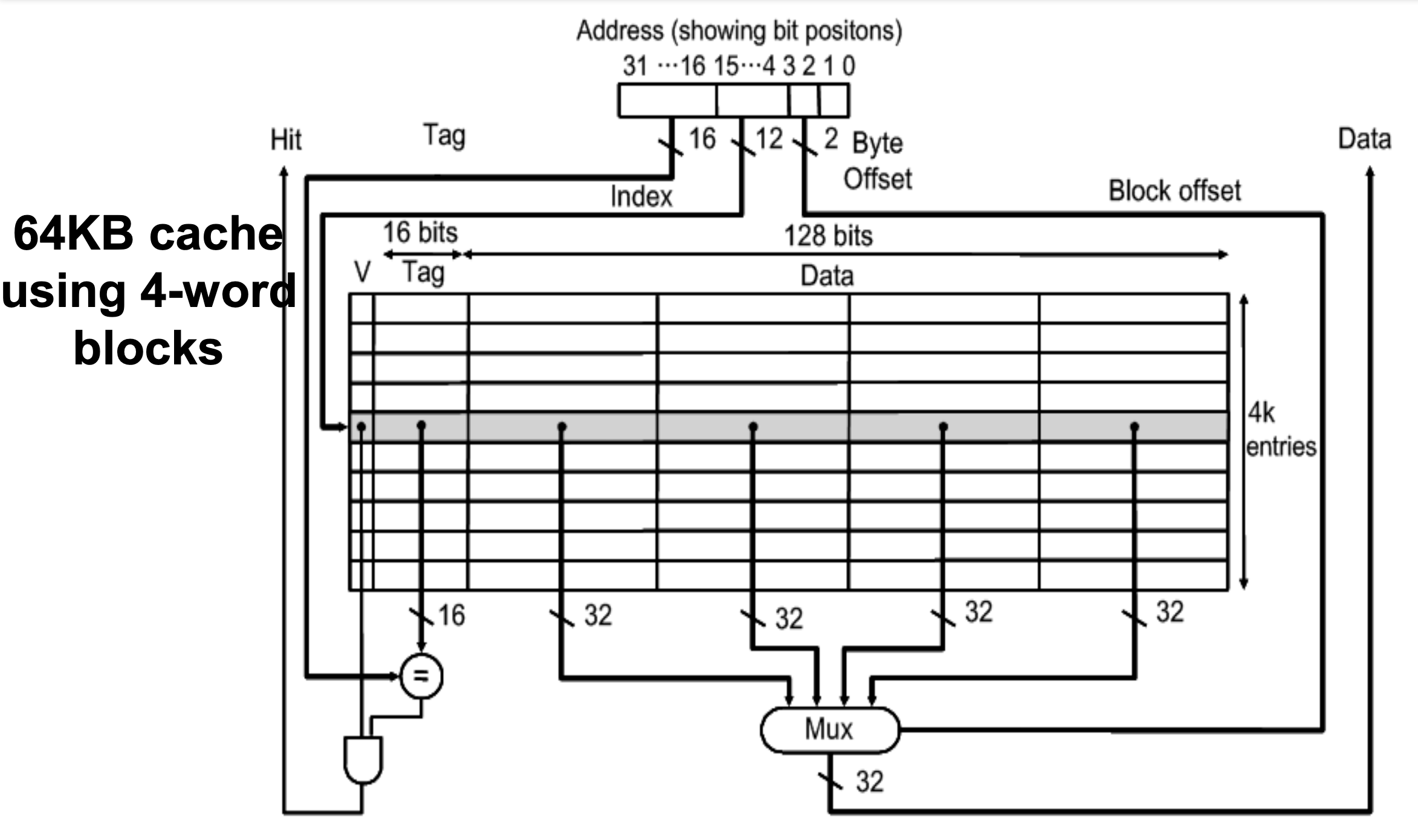
This picture shows the multiple word direct mapped cache. There is a address and it can be divided 4 sections. First is Byte Offset. However, we don't use the Byte address because we just use word address. So, we don't think about it.
In this architecture, we use 4-word blocks in cache. For that reason, we should use Block Offset in our architecture. We can choose one of the word in the block by using Block Offset.
There is a condition that 64KB cache using 4-word blocks, so we can make our index 12 bits.
64KB = 2^16 Byte = 2^14 words. However our cache block has 4 section to keep word address. So, we have to make 2^12 blocks to use this cache.
Finally, the Index bits are 12 bits, and the Tag bits are 16 bits.

We can take the advantage of spatial locality also. Because there are several words in the same block and each words in same block share Tag & Valid.
If there is a case of miss, we have to bring entire block. By doing so, we can take advantage of spatial locality.
Performance
We can take the performance in our architecture.
Execute Time = (Execution Clock Cycles + Stall Clock Cycles) * Cycle Time

The miss penaly is the time to replace a block in cache with corresponding block from the Memory + the time to deliver this block to the processor.
The miss penalty is big. So, we have to improve the performance of our computer architecture. There are two ways to improve the performance.
Decreasing the miss ratio
Decreasing the miss penalty
Increasing the Block size tends to decrease Miss Ratio. Because we can put many address of words into the our cache blocks. However, we have to create bigger cache. For that reason, it can cause the increasing of the miss penalty.
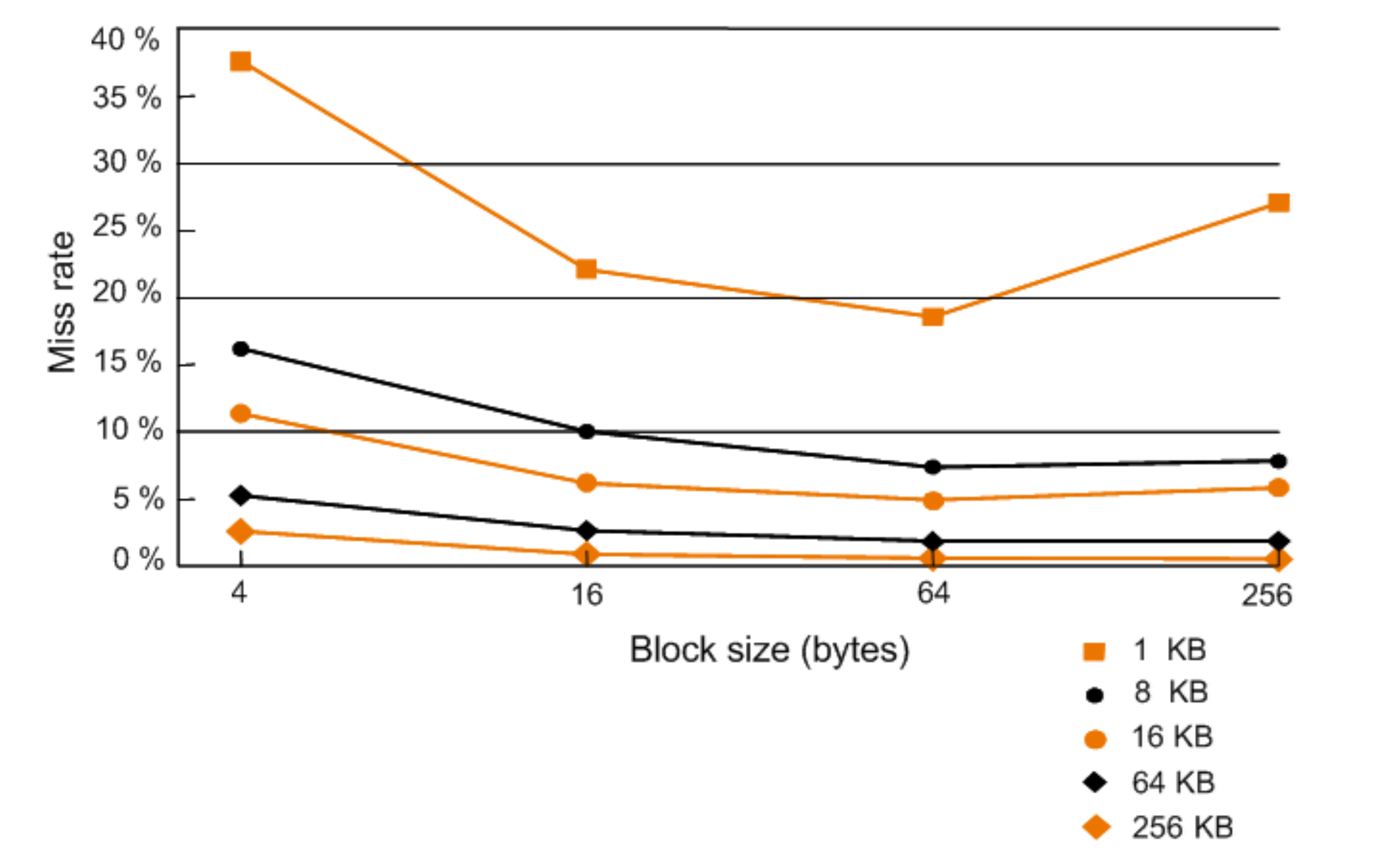
As you can see, there is a truning point in the graph.
We can solve this problem by using Bus. We can make multiple words easier by using banks of memory.
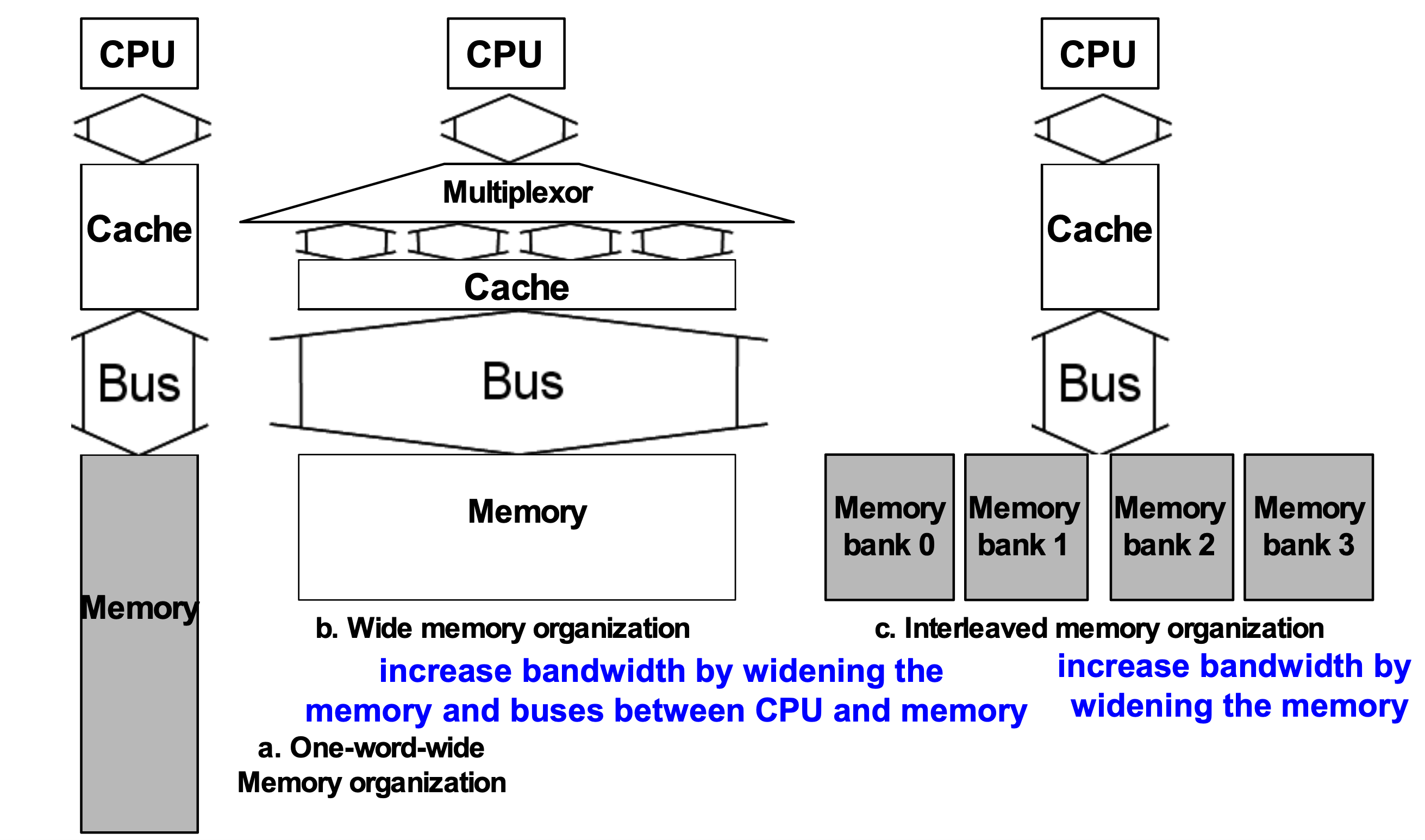
There are three types of the memory architecture.
-
One-word-wide Memory Organization
-> It can take many times to access the memory. -
Wide Memory Organization
-> It can take few times to access the memory because it can push main information by using big bus. However, big bus architecture may cause the increasing the money cost. -
Interleaved Memory Organization
-> It uses the small bus, but there are many memory banks. By using this architecture, we can save our money and time cost.
Where can a block be placed?
There are three placement policies.
1. Direct Mapped
2. Fully associative
3. Set associative
Direct Mapped
The address is modulo the number of blocks in the cache.
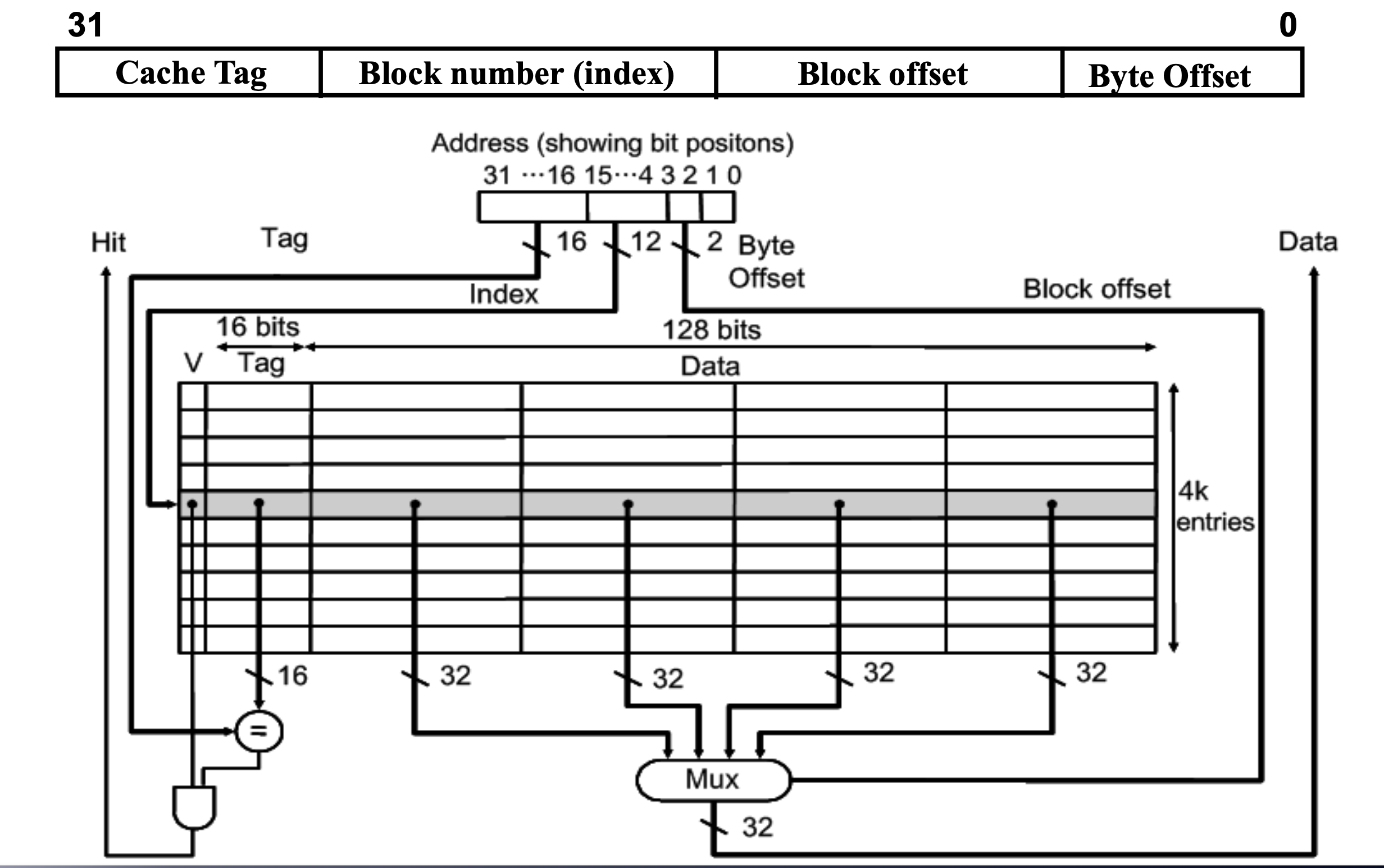
We have to create the place that address must be placed.
Fully Associative

We don't have to keep the Cache Index. Every block can be placed in any location in the cache.
However there are no order to place, so we have to compare all of the things in the cache.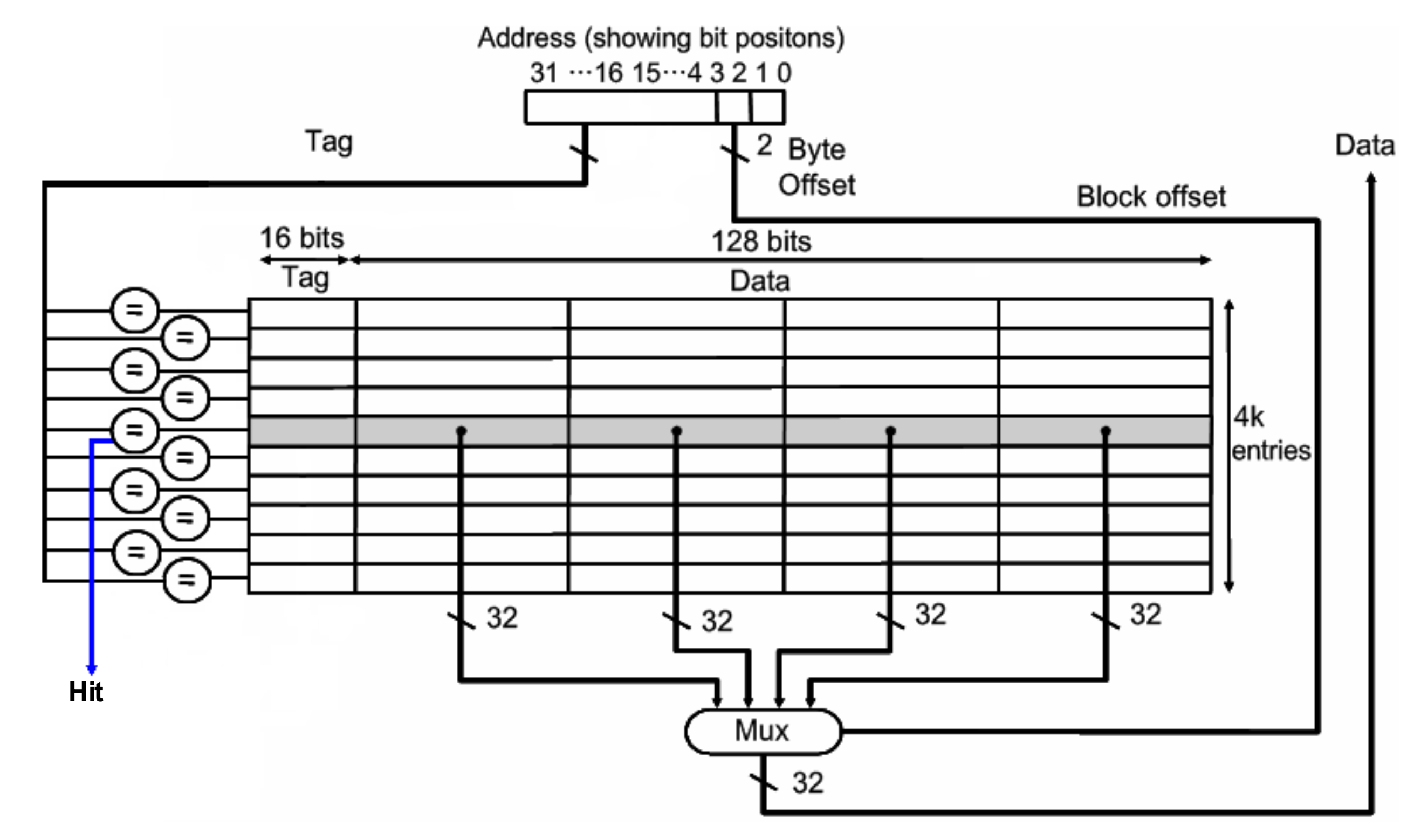
We have to compare all of things and we have to check hit or not.
Set Associative
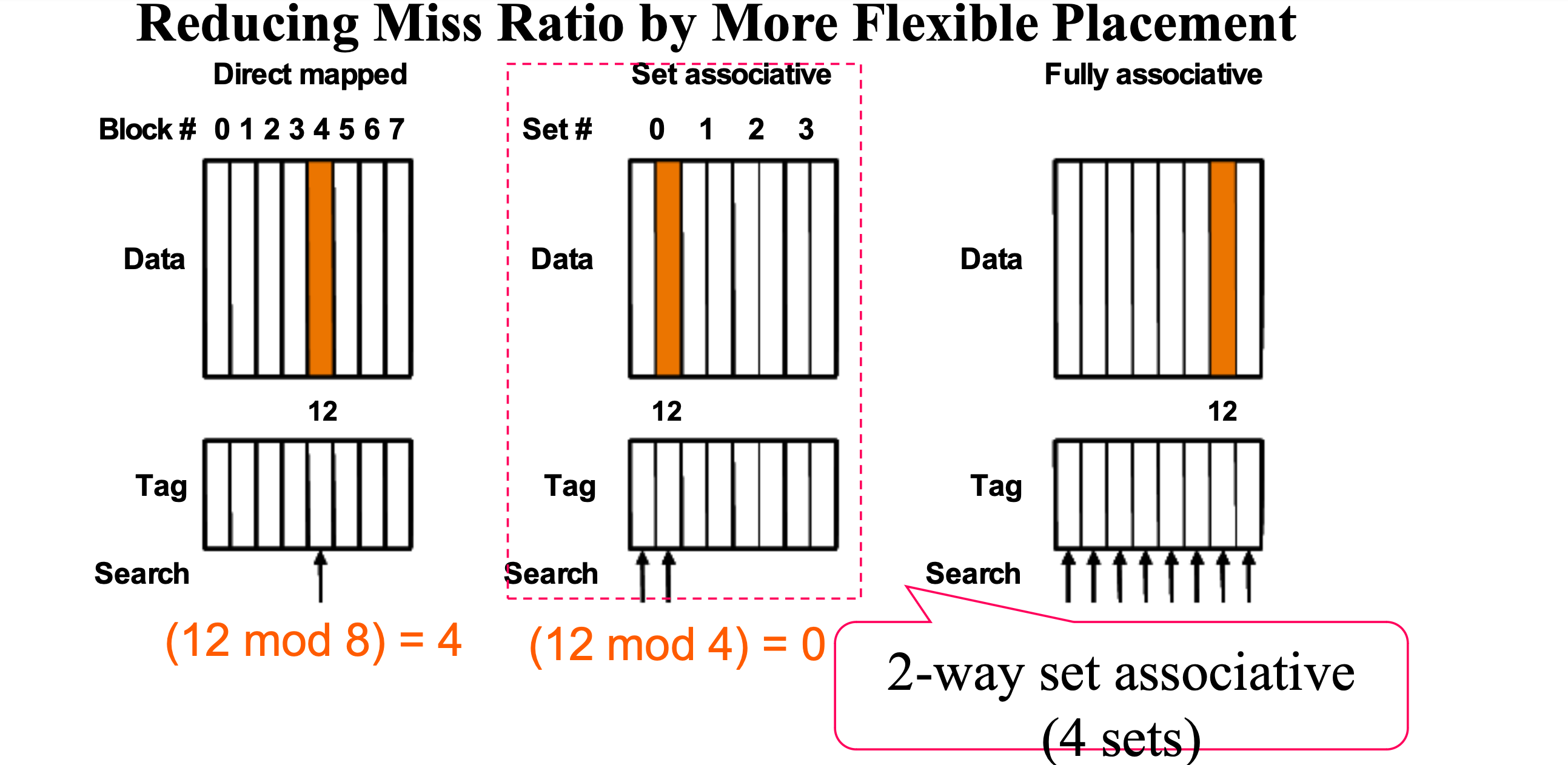
We can create set associative. In this picture, we have two section in the set. In addition, we have 4 slot and 2 blocks in the slot. So we have to mod 4.
This is an implementation of 4-way set associative cache.
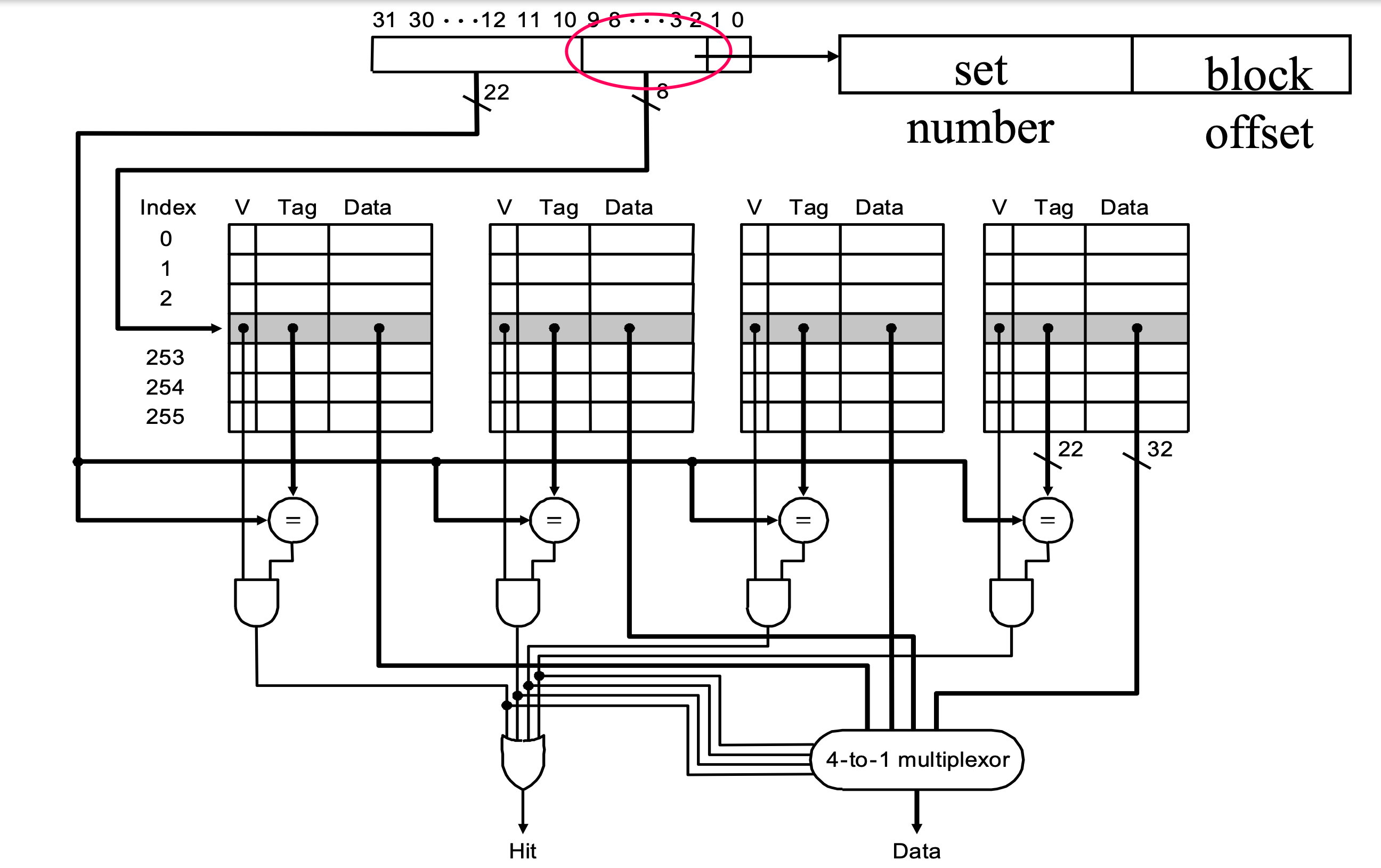
We must have set number because we have 4 way to store our address.
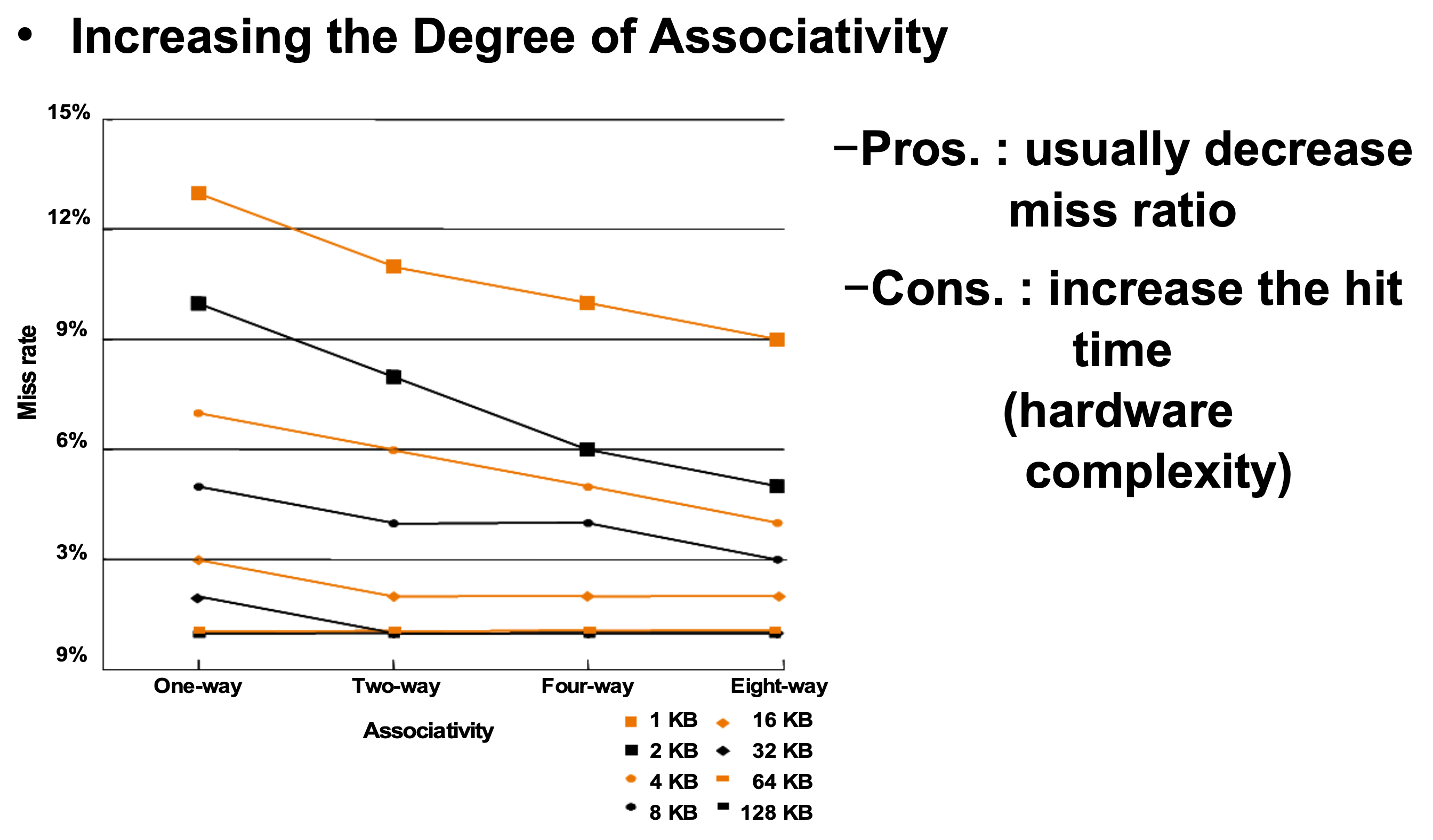
If we create fully associative model, the hit rate of the architecture will be increase. However, there are two cons. First, we must spend more time to find corresponding address. Second, we have to create more complexity hardware.
The Replacement Algorithm
In this architecture, many addresses are share the placement in the cache. It means that we should create some policy to manage of them.
There are many ways to manage the addresses.
1. Random
-> Replace the randomly selected block. It is not a good way.
2. FIFO
-> Replace the block that has been in the cache longest. We have to create time stamp to manage the time that data has been loaded.
3. Least Recently Used(LRU)
-> Replace the block that has been in the cache longest without reference. We have to create time stamp and it will be updated every referenced.
4. Least Frequently Used(LFU)
-> Replace the block with fewest reference. We have to create the counter. It is possible to replace the data that most recently loaded.
The most good way is to replace the block that will not be used again for the furthest time into the future.
In addition, we can make additional level of the cache. By doing so, we can use SRAM to add another cache above primary memory(DRAM).
Miss penalty goes down if data is in the second level cache.
The primary cache is smaller and faster and uses a smaller block size. However, the second cache uses larger block size compared to the single level cache.
