오늘의 목표
- EDA
- 데이터 전처리
2. Exploratory Data Analysis(EDA)
2-1. 데이터 살펴보기
# 데이터 정보 요약
df.info()- 결과:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 65280 entries, 0 to 65279 Data columns (total 20 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Custkey 65280 non-null int64 1 DateKey 65280 non-null datetime64[ns] 2 Discount Amount 65278 non-null float64 3 Invoice Date 65280 non-null datetime64[ns] 4 Invoice Number 65280 non-null int64 5 Item Class 56995 non-null object 6 Item Number 65240 non-null object 7 Item 65280 non-null object 8 Line Number 65280 non-null int64 9 List Price 65280 non-null float64 10 Order Number 65280 non-null int64 11 Promised Delivery Date 65280 non-null datetime64[ns] 12 Sales Amount 65280 non-null float64 13 Sales Amount Based on List Price 65280 non-null float64 14 Sales Cost Amount 65280 non-null float64 15 Sales Margin Amount 65280 non-null float64 16 Sales Price 65279 non-null float64 17 Sales Quantity 65280 non-null int64 18 Sales Rep 65280 non-null int64 19 U/M 65280 non-null object dtypes: datetime64[ns](3), float64(7), int64(6), object(4) memory usage: 10.0+ MB
# 결측치 확인
df.isna().sum()- 결과:
Custkey 0 DateKey 0 Discount Amount 2 Invoice Date 0 Invoice Number 0 Item Class 8285 Item Number 40 Item 0 Line Number 0 List Price 0 Order Number 0 Promised Delivery Date 0 Sales Amount 0 Sales Amount Based on List Price 0 Sales Cost Amount 0 Sales Margin Amount 0 Sales Price 1 Sales Quantity 0 Sales Rep 0 U/M 0 dtype: int64
# 컬럼별 고유값 및 누적합 확인
for col in df.columns:
print('')
print(df[col].value_counts().to_frame().join(df[col].value_counts(normalize=True).to_frame().cumsum()))
print('='*50)- 결과:
count proportion Custkey 10025919 2760 0.042279 10019194 2752 0.084436 10012715 1431 0.106357 10012226 1389 0.127635 10025025 1143 0.145144 ... ... ... 10024930 1 0.999939 10024880 1 0.999954 10020227 1 0.999969 10014059 1 0.999985 10002140 1 1.000000 [615 rows x 2 columns] ================================================== count proportion DateKey 2017-06-23 460 0.007047 2019-07-05 447 0.013894 2017-06-27 314 0.018704 2017-11-18 313 0.023499 2017-01-11 310 0.028248 ... ... ... 2017-06-21 7 0.999740 2019-07-03 7 0.999847 2017-06-28 4 0.999908 2019-06-19 3 0.999954 2017-06-07 3 1.000000 [559 rows x 2 columns] ================================================== count proportion Discount Amount 0.0000 1551 0.023760 24.8800 103 0.025338 606.8400 100 0.026870 639.8200 97 0.028356 402.7000 93 0.029780 ... ... ... -26.5352 1 0.999939 -31.7332 1 0.999954 -259.1455 1 0.999969 -25.2820 1 0.999985 185.9800 1 1.000000 [17745 rows x 2 columns] ================================================== count proportion Invoice Date 2017-06-23 460 0.007047 2019-07-05 447 0.013894 2017-06-27 314 0.018704 2017-11-18 313 0.023499 2017-01-11 310 0.028248 ... ... ... 2017-06-21 7 0.999740 2019-07-03 7 0.999847 2017-06-28 4 0.999908 2019-06-19 3 0.999954 2017-06-07 3 1.000000 [559 rows x 2 columns] ================================================== count proportion Invoice Number 225396 103 0.001578 125396 101 0.003125 113089 101 0.004672 126657 101 0.006219 313089 100 0.007751 ... ... ... 321629 1 0.999939 321628 1 0.999954 321620 1 0.999969 321619 1 0.999985 119202 1 1.000000 [24679 rows x 2 columns] ================================================== count proportion Item Class P01 56965 0.999474 PO1 16 0.999754 P02 1 0.999772 P12 1 0.999789 P13 1 0.999807 P06 1 0.999825 P15 1 0.999842 P11 1 0.999860 P08 1 0.999877 P07 1 0.999895 P10 1 0.999912 P09 1 0.999930 P14 1 0.999947 P03 1 0.999965 P05 1 0.999982 P04 1 1.000000 ================================================== count proportion Item Number 17801 1610 0.024678 28401 1344 0.045279 27550 1182 0.063397 67550 1126 0.080656 20910 1050 0.096750 ... ... ... 4881515 - DANZAS / AIR ( 1 0.999939 5013301059 1 0.999954 5013301071 1 0.999969 FRT FOR SO#512928 1 0.999985 1Z9483440344767496 1 1.000000 [983 rows x 2 columns] ================================================== count proportion Item Better Fancy Canned Sardines 1648 0.025245 Ebony Prepared Salad 1471 0.047779 Moms Sliced Turkey 1192 0.066039 Imagine Popsicles 1191 0.084283 Discover Manicotti 1126 0.101532 ... ... ... BBB Best Corn Oil 1 0.999939 Choice Bubble Gum 1 0.999954 Atomic White Chocolate Bar 1 0.999969 Tell Tale Potatos 1 0.999985 Discover Rice Medly 1 1.000000 [657 rows x 2 columns] ================================================== count proportion Line Number 1000 11206 0.171661 2000 3701 0.228355 3000 2767 0.270741 4000 2290 0.305821 5000 1948 0.335662 ... ... ... 53001 2 0.999908 107001 2 0.999939 52002 2 0.999969 132002 1 0.999985 132001 1 1.000000 [397 rows x 2 columns] ================================================== count proportion List Price 298.00 1508 0.023100 1431.23 1426 0.044945 966.44 1192 0.063205 1275.10 1126 0.080453 192.34 1041 0.096400 ... ... ... 0.52 1 0.999939 317.46 1 0.999954 40.02 1 0.999969 53.36 1 0.999985 205.00 1 1.000000 [1062 rows x 2 columns] ================================================== count proportion Order Number 210770 126 0.001930 222244 126 0.003860 110770 124 0.005760 122244 124 0.007659 205051 121 0.009513 ... ... ... 116002 1 0.999939 116104 1 0.999954 116171 1 0.999969 116221 1 0.999985 216774 1 1.000000 [17796 rows x 2 columns] ================================================== count proportion Promised Delivery Date 2017-06-27 310 0.004749 2017-01-11 305 0.009421 2019-07-09 303 0.014062 2017-11-17 273 0.018244 2019-11-29 264 0.022289 ... ... ... 2010-12-29 1 0.999939 2017-09-14 1 0.999954 2017-03-16 1 0.999969 2019-03-07 1 0.999985 2017-02-24 1 1.000000 [592 rows x 2 columns] ================================================== count proportion Sales Amount 817.68 115 0.001762 784.97 115 0.003523 294.72 110 0.005208 307.00 104 0.006801 597.14 102 0.008364 ... ... ... 679.54 1 0.999939 639.98 1 0.999954 463.05 1 0.999969 347.23 1 0.999985 624.60 1 1.000000 [17895 rows x 2 columns] ================================================== count proportion Sales Amount Based on List Price 1431.2300 590 0.009038 1627.8400 530 0.017157 803.8600 498 0.024786 596.0000 448 0.031648 1254.1899 418 0.038051 ... ... ... 369.0000 1 0.999939 385.5000 1 0.999954 1276.8000 1 0.999969 2675.0000 1 0.999985 205.0000 1 1.000000 [4060 rows x 2 columns] ================================================== count proportion Sales Cost Amount 449.69 534 0.008180 475.75 457 0.015181 0.00 347 0.020496 134.67 305 0.025169 162.89 289 0.029596 ... ... ... 126.68 1 0.999939 581.33 1 0.999954 1162.66 1 0.999969 111.86 1 0.999985 146.59 1 1.000000 [5513 rows x 2 columns] ================================================== count proportion Sales Margin Amount 374.70 93 0.001425 5317.17 88 0.002773 6235.31 87 0.004105 341.72 84 0.005392 15.32 69 0.006449 ... ... ... 787.68 1 0.999939 57.54 1 0.999954 85.47 1 0.999969 73.05 1 0.999985 144.25 1 1.000000 [21295 rows x 2 columns] ================================================== count proportion Sales Price 140.430000 191 0.002926 817.680000 189 0.005821 133.410000 181 0.008594 783.170000 138 0.010708 824.390000 138 0.012822 ... ... ... 197.365000 1 0.999939 107.621667 1 0.999954 135.768906 1 0.999969 23.112778 1 0.999985 159.770000 1 1.000000 [14788 rows x 2 columns] ================================================== count proportion Sales Quantity 1 15263 0.233808 2 13466 0.440089 3 7055 0.548162 4 4973 0.624341 5 3519 0.678248 ... ... ... 103 2 0.999939 0 1 0.999954 -1 1 0.999969 624 1 0.999985 292 1 1.000000 [281 rows x 2 columns] ================================================== count proportion Sales Rep 108 6225 0.095358 180 4427 0.163174 143 2926 0.207996 117 2441 0.245389 103 2162 0.278508 ... ... ... 116 167 0.993919 151 127 0.995864 152 126 0.997794 169 101 0.999341 150 43 1.000000 [64 rows x 2 columns] ================================================== count proportion U/M EA 58991 0.903661 SE 5629 0.989890 PR 659 0.999985 - 1 1.000000 ==================================================
데이터의 유형 나누기
수치형 변수 (8):
Discount AmountList PriceSales AmountSales Amount Based on List PriceSales Cost AmountSales Margin AmountSales PriceeSales Quantity
범주형 변수 (5):
Item ClassItemLine NumberSales RepU/M
날짜 변수 (3):
DateKeyInvoice DatePromised Delivery Date
고유 식별자 (4):
CustKeyInvoice NumberItem NumberOrder Number
# 데이터 유형 나누기
numerical_cols = ['Discount Amount', 'List Price', 'Sales Amount', 'Sales Amount Based on List Price', 'Sales Cost Amount',
'Sales Margin Amount', 'Sales Price', 'Sales Quantity']
categorical_cols = ['Item Class', 'Item', 'Line Number', 'Sales Rep', 'U/M']
date_cols = ['DateKey', 'Invoice Date', 'Promised Delivery Date']
id_cols = ['CustKey', 'Invoice Number', 'Item Number', 'Order Number']2-2. 데이터 시각화
데이터 유형별 시각화 방법
수치형 시각화 방법:
- 히스토그램 : histplot()
- 커널밀도추정함수 그래프 : kdeplot()
- 박스플롯 : boxplot()
범주형 시각화 방법:
- 막대그래프 : barplot()
데이터 상관관계 시각화:
- 히트맵 : heatmpap()
수치형 변수 시각화
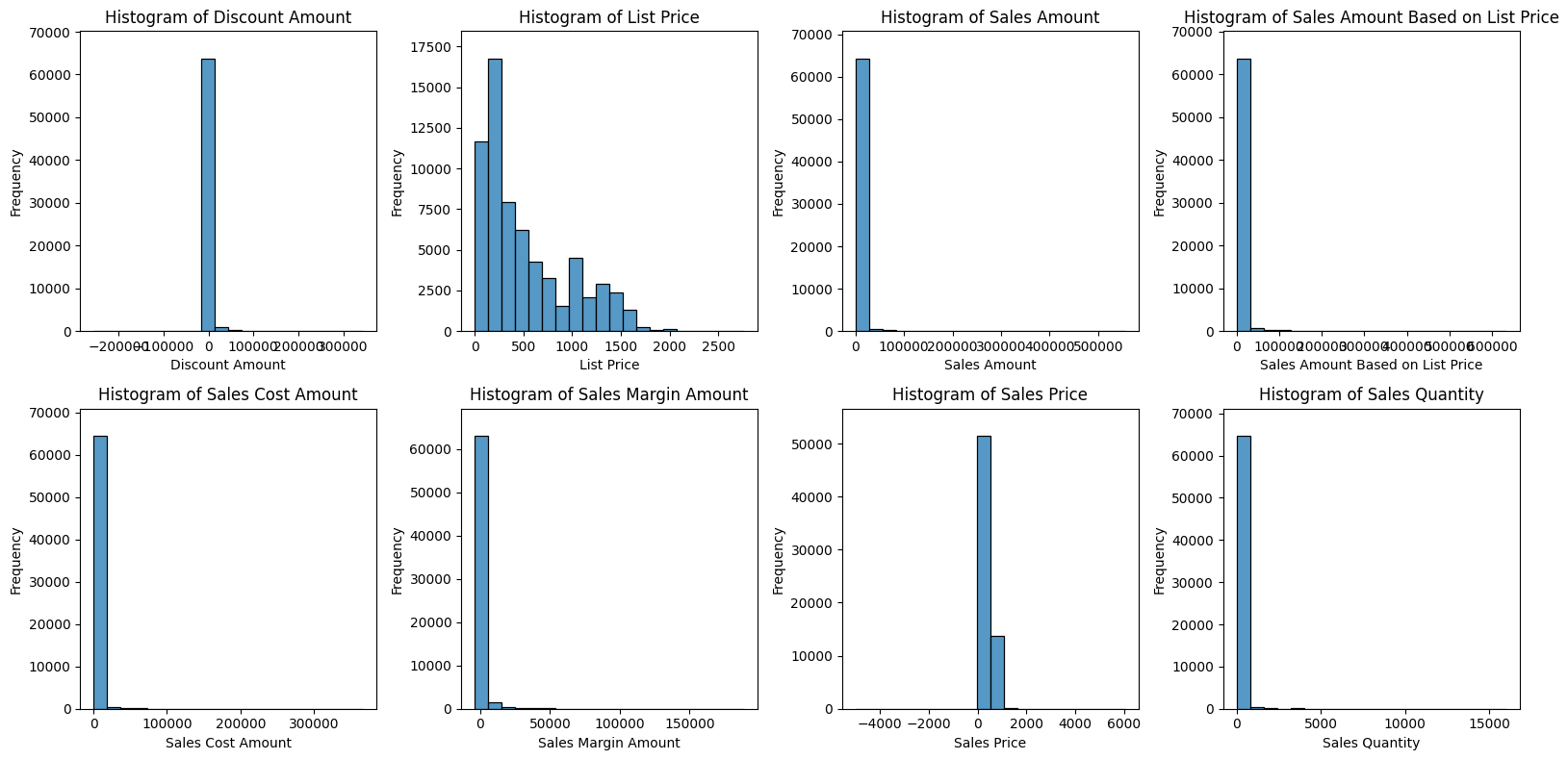
# 수치형 히스토그램
plt.figure(figsize=(16, 8))
for idx, col in enumerate(numerical_cols):
plt.subplot(2, 4, idx+1)
# 각 열의 히스토그램 빈도 계산
counts, _ = np.histogram(df[col].dropna(), bins=20)
sns.histplot(df[col], bins=20, kde=False)
plt.title(f'Histogram of {col}')
plt.ylabel('Frequency')
# 각 subplot의 y축 범위를 해당 컬럼에 맞게 설정
plt.ylim(0, counts.max() * 1.1)
plt.tight_layout()
plt.show()- 결과:
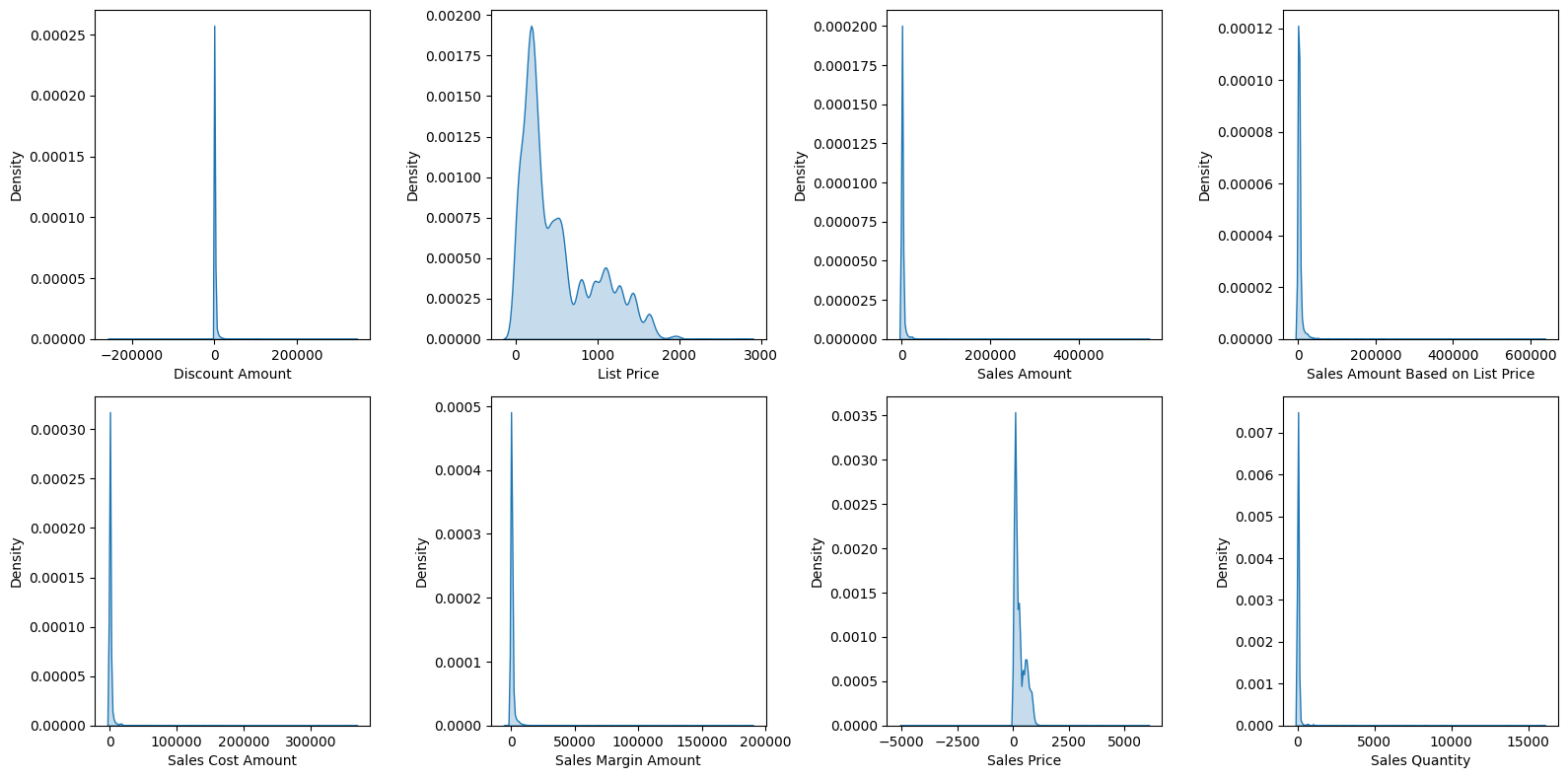
# 수치형 kdeplot
plt.figure(figsize=(16, 8))
for idx, col in enumerate(numerical_cols):
plt.subplot(2, 4, idx+1)
sns.kdeplot(df[col], shade=True)
plt.tight_layout()
plt.show()- 결과:
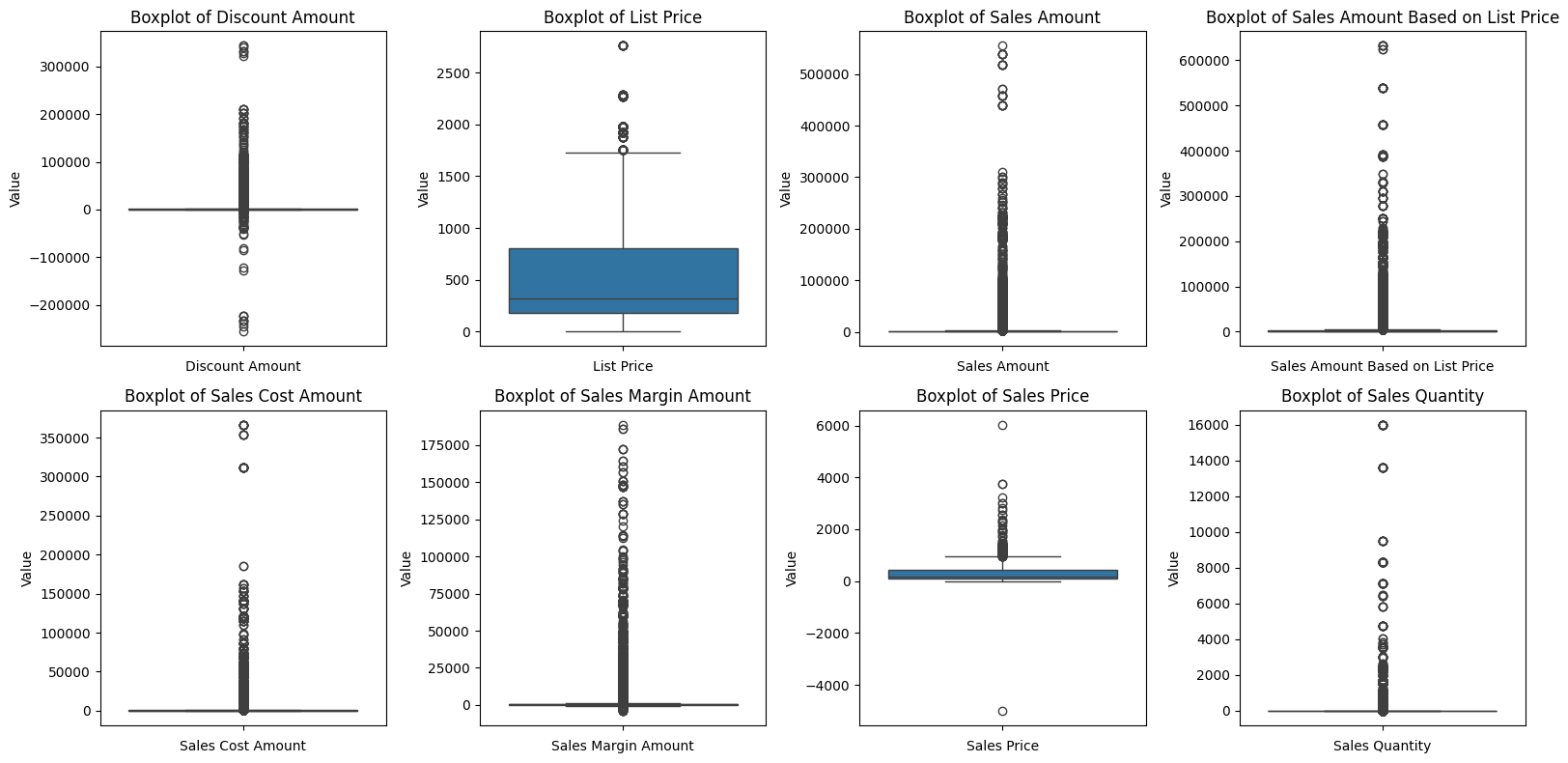
# 수치형 boxplot
plt.figure(figsize=(16, 8))
for idx, col in enumerate(numerical_cols):
plt.subplot(2, 4, idx+1)
sns.boxplot(y=df[col])
plt.title(f'Boxplot of {col}')
plt.xlabel(col)
plt.ylabel('Value')
plt.tight_layout()
plt.show()- 결과:
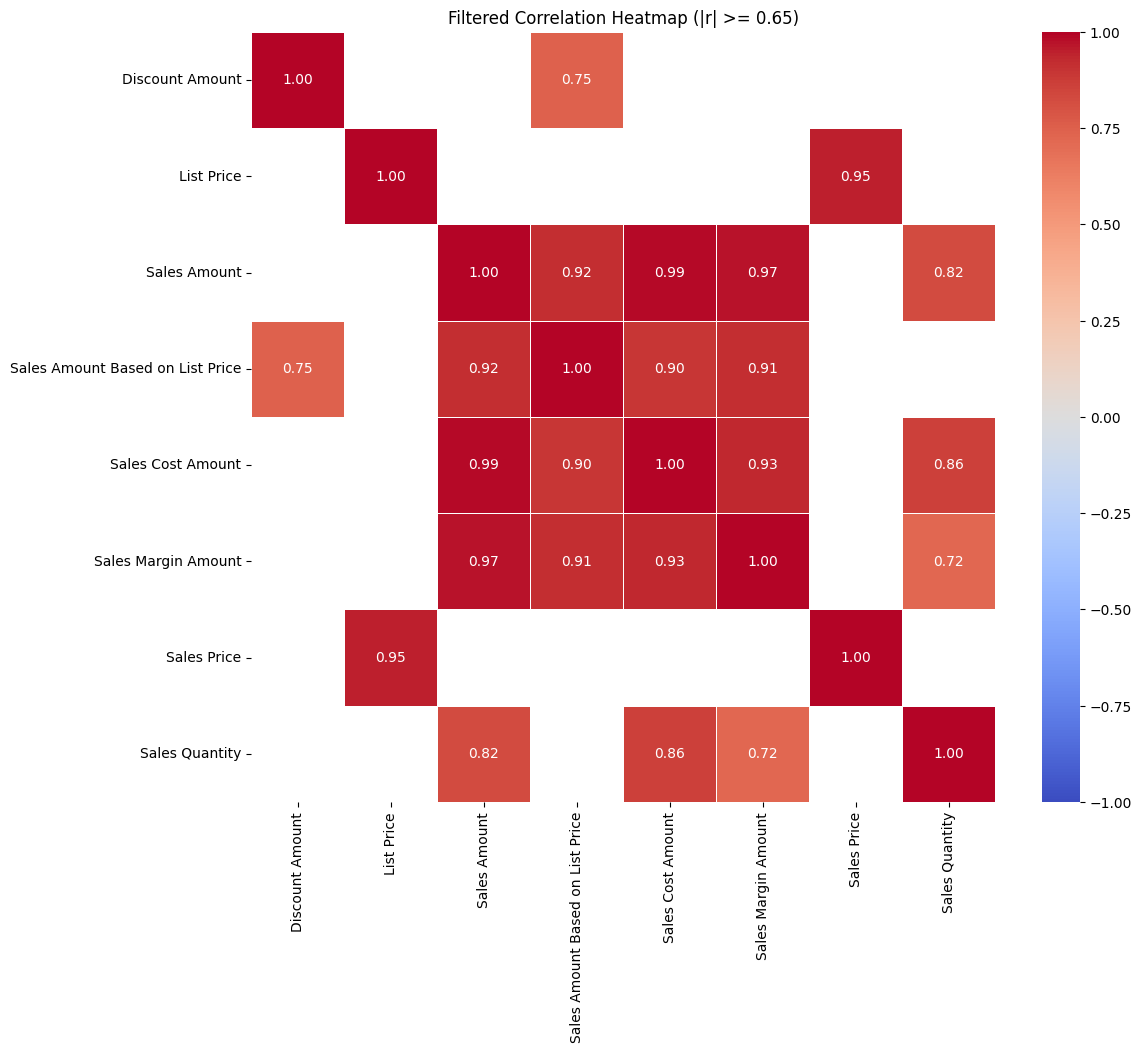
# 수치형 히트맵
corr_matrix = df[numerical_cols].corr()
# 0.65 이하의 상관계수는 필터링
filtered_corr_matrix = corr_matrix.where(abs(corr_matrix) >= 0.65, np.nan)
# 히트맵 그리기
plt.figure(figsize=(12, 10))
sns.heatmap(filtered_corr_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5, vmin=-1, vmax=1, mask=filtered_corr_matrix.isna())
plt.title('Filtered Correlation Heatmap (|r| >= 0.65)')
plt.show()- 결과:
범주형 변수 시각화
# 범주형 막대그래프
plt.figure(figsize=(18, 12))
for idx, col in enumerate(categorical_cols):
plt.subplot(2, 3, idx+1)
# 상위 10개 값만 추출
count_data = df[col].value_counts().head(10)
# 가로 방향 막대 그래프 그리기
sns.barplot(y=count_data.index, x=count_data.values, orient='h')
plt.title(f'Top 10 Count of {col}')
plt.xlabel('Count')
plt.ylabel(col)
plt.tight_layout()
plt.show()- 결과:
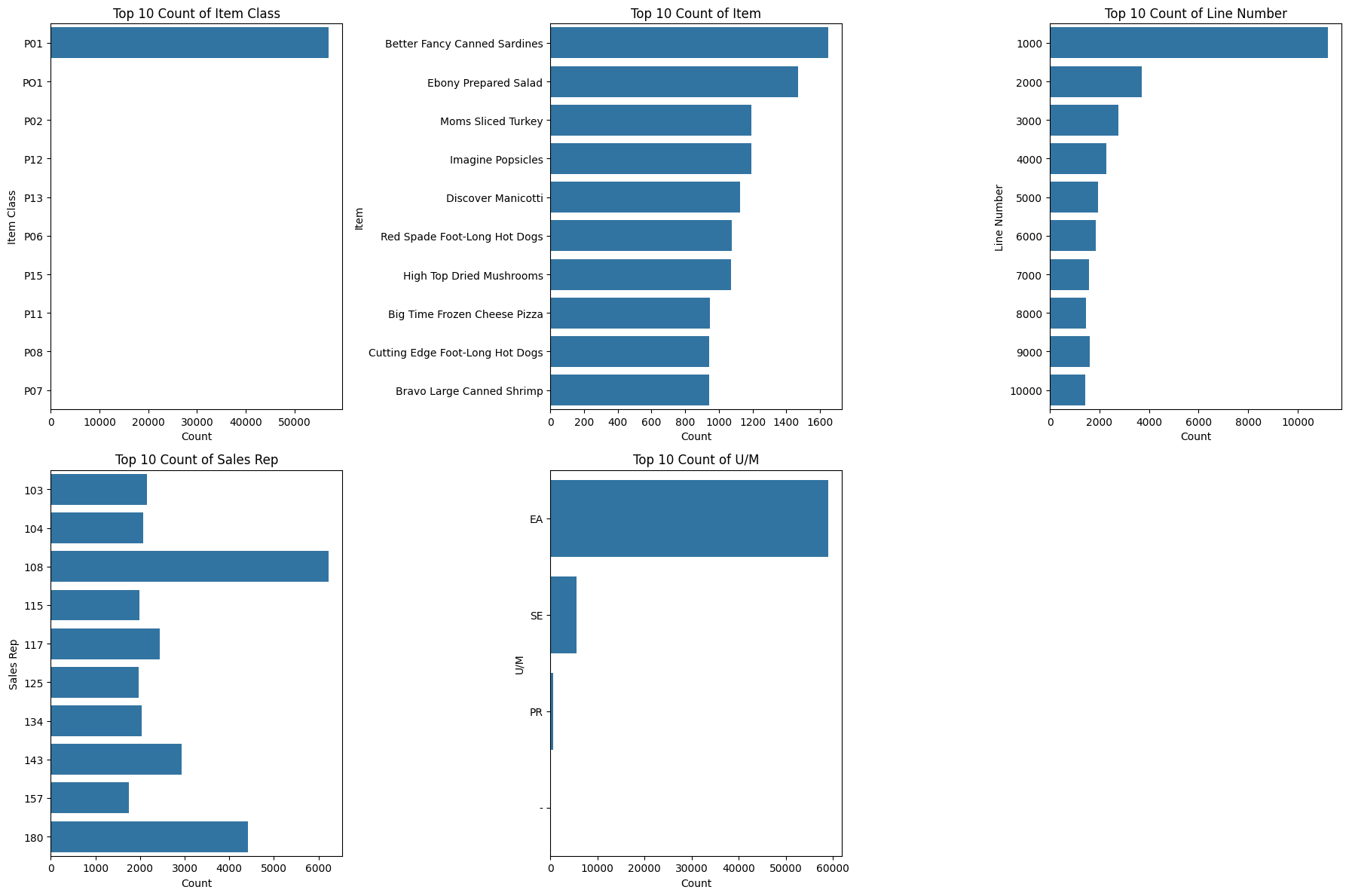
날짜 변수 시각화
monthly_sales = df.groupby(df['Invoice Date'].dt.to_period('M')).agg({'Sales Amount': 'sum'}).reset_index()
monthly_sales['Invoice Date'] = monthly_sales['Invoice Date'].dt.to_timestamp() # Period 객체를 Timestamp 객체로 변환
plt.figure(figsize=(14, 7))
# Line plot 그리기
sns.lineplot(data=monthly_sales, x='Invoice Date', y='Sales Amount', marker='o', color='coral')
# 그래프 제목과 레이블 설정
plt.title('Monthly Sales Amount')
plt.xlabel('Date')
plt.ylabel('Sales Amount')
plt.xticks(rotation=45) # x축 날짜 레이블 회전
plt.tight_layout()
plt.show()- 결과:
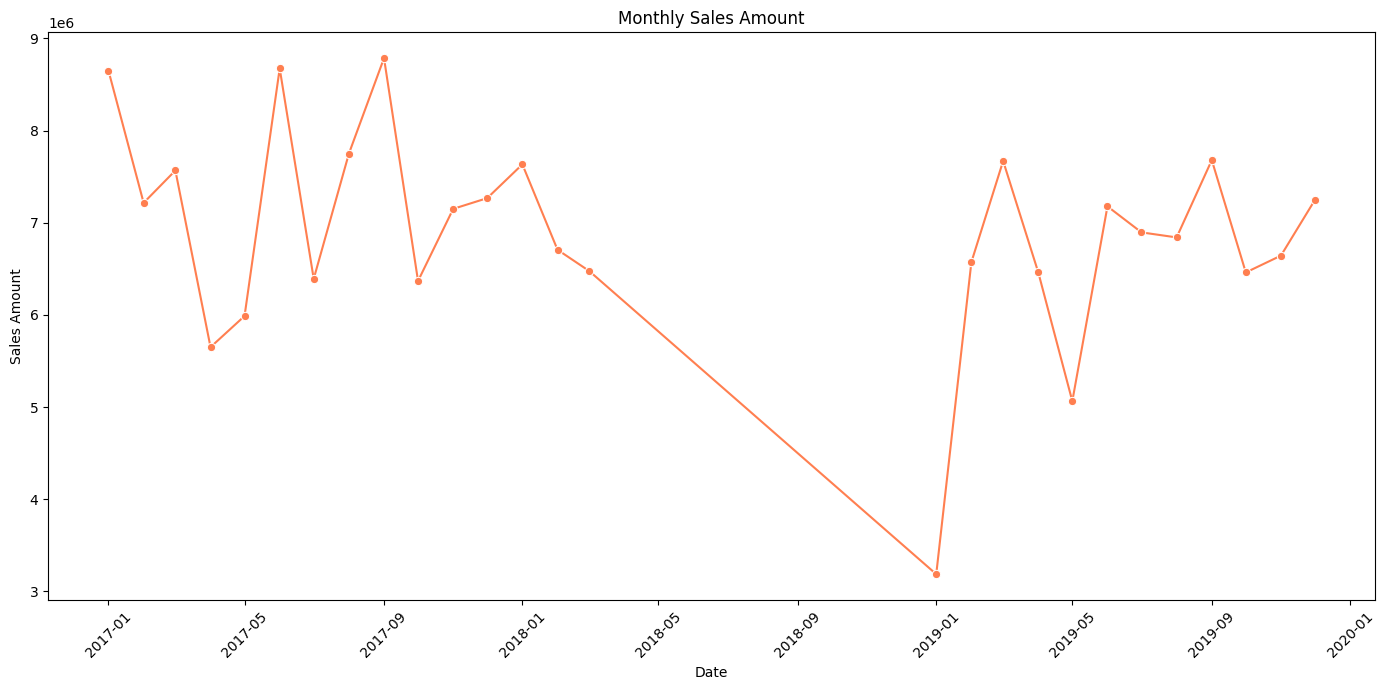
EDA 결과
수치형 변수:
- 수치형 변수 시각화 결과 특정 컬럼에서는 음수 값도 존재.
- 히스토그램을 살펴보면 거의 모든 컬럼에서 특정 구간에 몰려있는 현상을 볼 수 있었다.
- 또한, 값이 너무 동떨어진 값이 있어서 그래프가 제대로 그려지지 않는다.
- 박스플롯을 살펴보면 대다수의 컬럼에서 최대, 최소값을 넘어가는 이상점들이 많은 것을 확인할 수 있다.
범주형 변수
Item,Sales Rep을 제외한 나머지 컬럼들은 특정 카테고리에 몰려있다.
날짜 변수
- 2018년 3월부터 2019년 1월 사이에는 기록된 데이터가 없다.
결론:
- 수치형 변수에서 음수 값들 원인 분석.
- 이상치들 어떤 기준을 세워 해결할 것인가?
List Price가 0인 것은 뭘까?- 분포가 너무 몰려있는데 머신러닝을 사용하진 않으니 스케일링은 괜찮겠지?
- 범주형 변수에서
Item Class는 P01이 약 99.9%를 차지한다. 나머지 카테고리는 제외하고 분석하는 게 좋지 않을까?
2-3. 전처리 기준 세우기
수치형 변수
음수값 확인
: Discount Amount, Sales Price, Sales Quantity
# Discount Amount 음수값 확인 : 851개
df[df['Discount Amount'] < 0]- 결과: 851 rows × 20 columns
# Discount Amount의 음수값을 가진 행 필터링
negative_discount_df = df[df['Discount Amount'] < 0]
# CustKey와 Invoice Number를 기준으로 그룹화하고, 음수 할인 금액이 있는 경우의 개수 집계
grouped_negative_discounts = negative_discount_df.groupby('Custkey').size().reset_index(name='Negative Discount Count')
grouped_negative_discounts- 결과:
Custkey Negative Discount Count 0 10000466 1 1 10000472 4 2 10000601 1 3 10002154 22 4 10002240 4 ... ... ... 122 10026294 1 123 10026522 1 124 10027119 2 125 10027348 9 126 10027370 4 127 rows × 2 columns
결론:
보통 이런 Sales 데이터에서 음수는 환불처리를 뜻하는 것일 수 있다. 하지만 그렇다면 Quantity도 음수가 되는 게 맞다고 생각.그래서 Sales Quantity를 살펴봤으나 그렇지 않았다. 이러한 데이터의 개수는 851개로 전체 데이터 대비 1.3%정도밖에 되지 않기 때문에 제거하기로 결정.
# Sales Amount 음수값 확인 : 1개
df[df['Sales Price'] < 0]# Sales Quantity 음수값 확인 : 1개
df[df['Sales Quantity'] < 0]결론:
두 컬럼에 대해서는 완전히 동일한 데이터에 대해서 음수가 발생. 하지만, 1개뿐이고 우리의 분석 목적과 비교하면 크게 중요하지 않다고 판단해서 제거하기로 결정.
List Price 0원
# List Price가 0원인 값들.
df[df['List Price'] == 0]- 결과: 295 rows × 20 columns
# List Price가 0원이면서 Discount Amount가 음수가 아닌 값들
df[(df['List Price'] == 0) & (df['Discount Amount'] > 0)]- 결과: 없음.
결론:
List Price가 0원 인 값은 295개가 있다. 그리고 Discount Amount가 음수값이 많아서 혹시 List Price가 0원이면서 Discount Amount가 음수가 아닌 값들이 있을까해서 찾아봤지만 그런 데이터는 없었다. 따라서, 이 둘에 어떤 관계가 있을 것이라 판단하고, 위에서 Discount Amount를 제거하기로 했기 때문에 이 295개의 데이터도 제거하기로 결정.
수치형 변수 이상치들
# Sales Quantity가 16000개인 데이터들
df[df['Sales Quantity'] == 16000]결론:
위의 박스플롯에서 살펴봤던 것처럼 이상점들이 굉장히 많이 존재한다. 그래서 이를 분석하기 위해 여러 컬럼들과 함께 살펴봤다. 그러던 중 Sales Quantity의 평균이 약 45개이고, 최대 16,000개까지 존재한다는 것을 파악했다. 16000개는 상식적으로 말이 안 되는 숫자라고 생각해 16000개의 수량을 구매한 데이터를 살펴봤는데, 여러 건이 존재했고 주기적으로 구매하는 것도 파악했다. 이를 토대로 해당 데이터셋은 도매 및 소매를 같이 하는 업체라고 판단했고, 위에서 발견했던 이상치들은 업체의 특성으로 발생되는 자연스러운 현상으로 보고 따로 이상치 처리는 하지 않기로 결정했다.
이후에는 분석의 정확성을 위해 도매 및 소매를 나누는 기준을 정하고자 한다.
범주형 변수
Item Class
결론:
Item Class의 경우 P01이 누적합 약 99.9%를 차지하고 오타로 추정되는 PO1 16개를 제외한 나머지 Class는 1개씩 존재한다. 카테고리가 1개만 존재하는 것은 큰 의미가 없기 때문에 컬럼을 드랍하기로 결정
U/M
df['U/M'].value_counts().to_frame().join(df['U/M'].value_counts(normalize=True).to_frame().cumsum())- 결과:
count proportion U/M EA 58991 0.903661 SE 5629 0.989890 PR 659 0.999985 - 1 1.000000
결론:
U/M의 경우 대시로 기록된 이상한 값이 하나 존재한다. 그래서 이 값만 제거하고 나머지는 그대로 가져가기로 결정.
날짜변수
Datekey, Invoice Date, Promised Delivery Date
결론:
이 날짜변수 같은 경우에는 송장이 발행된 날짜를 기준으로 월별 실제 판매 금액을 집계해봤을 때 2018년 3월 21일과 2019년 1월 12일 사이의 기록이 누락된 것을 확인할 수 있었다. 따라서, 2018년 데이터는 제외하고 2017년과 2019년 데이터에 대해서만 시계열 분석에 활용할 예정이다.
그리고, 혹시 가능하다면 기록이 누락된 이유를 찾아보고자 한다.
결측치
Discount Amount, Item Class, Item Number, Sales Price
결론:
모든 결측치는 제거.
3. Data PreProcessing
3-1. 수치형 변수 전처리하는 코드
# 수치형 변수 전처리
# 1. Discount Amount가 음수인 행 제거
df = df.drop(df[df['Discount Amount'] < 0].index)
# 2. Sales Price가 음수인 행 제거
df = df.drop(df[df['Sales Price'] < 0].index)
# 3. Sales Quantity가 음수인 행 제거
df = df.drop(df[df['Sales Quantity'] < 0].index)
# 4. List Count가 0인 행 제거
df = df.drop(df[df['List Price'] == 0].index)3-2. 범주형 변수 전처리하는 코드
# 범주형 변수 전처리
# Item Class 컬럼을 제거
df = df.drop(columns=['Item Class'])
# 2. U/M에서 '-'로 기록된 행 제거
df = df.drop(df[df['U/M'] == '-'].index)3-3. 날짜형 변수 전처리하는 코드
# 날짜형 변수 전처리
# 1. Datekey에서 2018년에 해당하는 행 제거
df = df.drop(df[df['DateKey'].dt.year == 2018].index)
# 2. Invoice Date에서 2018년에 해당하는 행 제거
df = df.drop(df[df['Invoice Date'].dt.year == 2018].index)
# 3. Promised Delivery Date에서 2018년에 해당하는 행 제거
df = df.drop(df[df['Promised Delivery Date'].dt.year == 2018].index)
# 4. 'Promised Delivery Date'가 2017년 1월 1일 이전인 행 삭제
df = df[df['Promised Delivery Date'] >= '2017-01-01']3-4. 결측치 전처리하는 코드
# 결측치 전처리
# 1. Discount Amount에서 결측치가 있는 행 제거
df = df.drop(df[df['Discount Amount'].isnull()].index)
# 2. Item Number에서 결측치가 있는 행 제거
df = df.drop(df[df['Item Number'].isnull()].index)
# 3. Sales Price에서 결측치가 있는 행 제거
df = df.drop(df[df['Sales Price'].isnull()].index)# 전처리 후 결과 확인
df.isnull().sum()- 결과:
Custkey 0 DateKey 0 Discount Amount 0 Invoice Date 0 Invoice Number 0 Item Number 0 Item 0 Line Number 0 List Price 0 Order Number 0 Promised Delivery Date 0 Sales Amount 0 Sales Amount Based on List Price 0 Sales Cost Amount 0 Sales Margin Amount 0 Sales Price 0 Sales Quantity 0 Sales Rep 0 U/M 0 dtype: int64
df.info()- 결과:
<class 'pandas.core.frame.DataFrame'> Index: 58062 entries, 0 to 65279 Data columns (total 19 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Custkey 58062 non-null int64 1 DateKey 58062 non-null datetime64[ns] 2 Discount Amount 58062 non-null float64 3 Invoice Date 58062 non-null datetime64[ns] 4 Invoice Number 58062 non-null int64 5 Item Number 58062 non-null object 6 Item 58062 non-null object 7 Line Number 58062 non-null int64 8 List Price 58062 non-null float64 9 Order Number 58062 non-null int64 10 Promised Delivery Date 58062 non-null datetime64[ns] 11 Sales Amount 58062 non-null float64 12 Sales Amount Based on List Price 58062 non-null float64 13 Sales Cost Amount 58062 non-null float64 14 Sales Margin Amount 58062 non-null float64 15 Sales Price 58062 non-null float64 16 Sales Quantity 58062 non-null int64 17 Sales Rep 58062 non-null int64 18 U/M 58062 non-null object dtypes: datetime64[ns](3), float64(7), int64(6), object(3) memory usage: 8.9+ MB
데이터 전처리 후 최종 데이터의 개수는 58062 개로 기존 데이터의 개수보다 약 11% 정도 감소했다.
내일 할 일
- 내일은 Item Class 를 드랍한 대신 대분류, 소분류를 Item에 맵핑할 예정
- 전처리 후 최종 데이터파일 만들기.
- Tableau로 파일 불러오기
- 지표 선정 및 시각화 해보기.
