오늘의 목표
- 데이터 전처리 마무리
- 지표 설정
오늘은 어제 못 한 대분류, 소분류 컬럼 추가하기, 도매/소매 분류하기, 비싼 금액을 어떻게 처리할지에 대한 기준 세우기를 하고자 한다.
카테고리 컬럼 생성
어제 Item Class에서 P01이 99.9%를 차지해서 이렇게 하나로 분류되는 Item Class는 유의미하지 않다고 판단해 컬럼 자체를 드랍했었다.
오늘은 Item을 나눠 분석할 수 있도록 대분류, 소분류를 추가하고자 한다.
카테고리 컬럼 생성
- ‘상품이름’에서 마지막 단어만 뽑아서 새로운 컬럼 Food 생성
- 보통 마지막이 해당 상품의 종류를 알려주기 때문에 선정
df = df.reset_index(drop=True)
last = []
for i in range(len(df)):
last.append(df['Item'][i].split(" ")[-1])
df['Food'] = last
# 집합을 통해서 단어 중복 제거 -> 총 116개
last = set(last)카테고리 분류
1. 유제품 및 계란류
- 유제품 : Butter, Buttermilk, Cream, Cheese, Milk, Yogurt, Sandwich(아이스크림샌드위치), Popsicles
- 계란: Eggs
2. 고기류 및 해산물
- 가공육: Bologna, Jerky, Ham, Loaf
- 육류: Chicken, Turkey, Thighs, Wings, Beef
- 해산물: Anchovies, Clams, Lox, Sardines, Scallops, Shrimp, Oysters
3. 과일 및 견과류
- 과일: Apples, Apricots, Cantelope, Dates, Lemons, Limes, Oranges, Peaches, Plums, Raisins, Tangerines, Fruit, Dew
- 견과류: Almonds, Peanuts, Walnuts, Nuts
4. 채소류
- 채소: Beets, Carrots, Potatos, Onions, Onion, Garlic, Broccoli, Cauliflower, Lettuce, Cabbage, Squash, Pumpkin, Asparagus, Corn, Cob, Beans, Peas, Oregano, Tomatos, Mushrooms, Slaw, Salad, Tofu
5. 빵, 면, 곡물류
- 빵 및 베이커리: Bagels, Bread, Brownies, Muffins, Donuts, Waffles, Puffs
- 파스타 및 면류: Manicotti, Spaghetti, Ravioli
- 곡류: Oatmeal, Rice
6. 음료
- 알코올 음료: Beer, Chardonnay, Wine
- 커피 및 차: Coffee
- 탄산 음료: Cola, Soda
- 주스 : Juice, Drink
7. 간식 및 디저트
- 초콜릿 및 캔디: Chocolate, Mints, Gum, Jelly
- 과자 및 스낵류: Chips, Cookies, Pretzels, Crackers, Popcorn, Fries, Roll, Balls, Bar
8. 조미료 및 양념류
- 버터 및 오일: Butter, Oil
- 잼: Jam, , Preserves
- 소스 및 드레싱: Sauce, Dip, Spread
- 양념 및 향신료: Salt, Pepper, Sugar
9. 가공 식품
- 냉동식품: Hot Dogs, Hamburger, Pizza, Dinner, Medly, Pancakes
- 수프 : Soup, Grits
- 캔 : Water(참치캔), Yams
- 믹스가루 : Mix
# 대분류 및 소분류를 매핑하는 딕셔너리
category_map = {
'Almonds': ('과일 및 견과류', '견과류'),
'Anchovies': ('고기류 및 해산물', '해산물'),
'Apples': ('과일 및 견과류', '과일'),
'Apricots': ('과일 및 견과류', '과일'),
'Asparagus': ('채소류', '채소'),
'Bagels': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Balls': ('간식 및 디저트', '과자 및 스낵류'),
'Bar': ('간식 및 디저트', '과자 및 스낵류'),
'Beans': ('채소류', '채소'),
'Beef': ('고기류 및 해산물', '육류'),
'Beer': ('음료', '알코올 음료'),
'Beets': ('채소류', '채소'),
'Bologna': ('고기류 및 해산물', '가공육'),
'Bread': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Broccoli': ('채소류', '채소'),
'Brownies': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Butter': ('유제품 및 계란류', '유제품'),
'Buttermilk': ('유제품 및 계란류', '유제품'),
'Cantelope': ('과일 및 견과류', '과일'),
'Carrots': ('채소류', '채소'),
'Cauliflower': ('채소류', '채소'),
'Chardonnay': ('음료', '알코올 음료'),
'Cheese': ('유제품 및 계란류', '유제품'),
'Chicken': ('고기류 및 해산물', '육류'),
'Chips': ('간식 및 디저트', '과자 및 스낵류'),
'Chocolate': ('간식 및 디저트', '초콜릿 및 캔디'),
'Clams': ('고기류 및 해산물', '해산물'),
'Cob': ('채소류', '채소'),
'Coffee': ('음료', '커피 및 차'),
'Cola': ('음료', '탄산 음료'),
'Cookies': ('간식 및 디저트', '과자 및 스낵류'),
'Corn': ('채소류', '채소'),
'Crackers': ('간식 및 디저트', '과자 및 스낵류'),
'Cream': ('유제품 및 계란류', '유제품'),
'Dates': ('과일 및 견과류', '과일'),
'Dew': ('과일 및 견과류', '과일'),
'Dinner': ('가공 식품', '냉동식품'),
'Dip': ('조미료 및 양념류', '소스 및 드레싱'),
'Dogs': ('가공 식품', '냉동식품'),
'Donuts': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Drink': ('음료', '주스'),
'Eggs': ('유제품 및 계란류', '계란'),
'Fries': ('간식 및 디저트', '과자 및 스낵류'),
'Fruit': ('과일 및 견과류', '과일'),
'Garlic': ('채소류', '채소'),
'Grits': ('가공 식품', '수프'),
'Gum': ('간식 및 디저트', '초콜릿 및 캔디'),
'Ham': ('고기류 및 해산물', '가공육'),
'Hamburger': ('가공 식품', '냉동식품'),
'Jam': ('조미료 및 양념류', '잼'),
'Jelly': ('간식 및 디저트', '초콜릿 및 캔디'),
'Jerky': ('고기류 및 해산물', '가공육'),
'Juice': ('음료', '주스'),
'Lemons': ('과일 및 견과류', '과일'),
'Lettuce': ('채소류', '채소'),
'Limes': ('과일 및 견과류', '과일'),
'Loaf': ('고기류 및 해산물', '가공육'),
'Lox': ('고기류 및 해산물', '해산물'),
'Manicotti': ('빵, 면, 곡물류', '파스타 및 면류'),
'Medly': ('가공 식품', '냉동식품'),
'Milk': ('유제품 및 계란류', '유제품'),
'Mints': ('간식 및 디저트', '초콜릿 및 캔디'),
'Mix': ('가공 식품', '믹스가루'),
'Muffins': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Mushrooms': ('채소류', '채소'),
'Nuts': ('과일 및 견과류', '견과류'),
'Oatmeal': ('빵, 면, 곡물류', '곡류'),
'Oil': ('조미료 및 양념류', '버터 및 오일'),
'Onion': ('채소류', '채소'),
'Onions': ('채소류', '채소'),
'Oranges': ('과일 및 견과류', '과일'),
'Oregano': ('채소류', '채소'),
'Oysters': ('고기류 및 해산물', '해산물'),
'Pancakes': ('가공 식품', '냉동식품'),
'Peaches': ('과일 및 견과류', '과일'),
'Peanuts': ('과일 및 견과류', '견과류'),
'Peas': ('채소류', '채소'),
'Pepper': ('조미료 및 양념류', '양념 및 향신료'),
'Pizza': ('가공 식품', '냉동식품'),
'Plums': ('과일 및 견과류', '과일'),
'Popcorn': ('간식 및 디저트', '과자 및 스낵류'),
'Popsicles': ('유제품 및 계란류', '유제품'),
'Potatos': ('채소류', '채소'),
'Preserves': ('조미료 및 양념류', '잼'),
'Pretzels': ('간식 및 디저트', '과자 및 스낵류'),
'Puffs': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Raisins': ('과일 및 견과류', '과일'),
'Ravioli': ('빵, 면, 곡물류', '파스타 및 면류'),
'Rice': ('빵, 면, 곡물류', '곡류'),
'Roll': ('간식 및 디저트', '과자 및 스낵류'),
'Salad': ('채소류', '채소'),
'Salt': ('조미료 및 양념류', '양념 및 향신료'),
'Sandwich': ('유제품 및 계란류', '유제품'),
'Sardines': ('고기류 및 해산물', '해산물'),
'Sauce': ('조미료 및 양념류', '소스 및 드레싱'),
'Scallops': ('고기류 및 해산물', '해산물'),
'Shrimp': ('고기류 및 해산물', '해산물'),
'Slaw': ('채소류', '채소'),
'Soda': ('음료', '탄산 음료'),
'Soup': ('가공 식품', '수프'),
'Spaghetti': ('빵, 면, 곡물류', '파스타 및 면류'),
'Spread': ('조미료 및 양념류', '소스 및 드레싱'),
'Squash': ('채소류', '채소'),
'Sugar': ('조미료 및 양념류', '양념 및 향신료'),
'Tangerines': ('과일 및 견과류', '과일'),
'Thighs': ('고기류 및 해산물', '육류'),
'Tofu': ('채소류', '채소'),
'Tomatos': ('채소류', '채소'),
'Turkey': ('고기류 및 해산물', '육류'),
'Waffles': ('빵, 면, 곡물류', '빵 및 베이커리'),
'Walnuts': ('과일 및 견과류', '견과류'),
'Water': ('가공 식품', '캔'),
'Wine': ('음료', '알코올 음료'),
'Wings': ('고기류 및 해산물', '육류'),
'Yams': ('가공 식품', '캔'),
'Yogurt': ('유제품 및 계란류', '유제품')
}
# 대분류와 소분류를 할당하는 함수
def assign_category(food_item):
return category_map.get(food_item, ('Uncategorized', 'Uncategorized'))
# 음식 리스트를 데이터프레임으로 변환
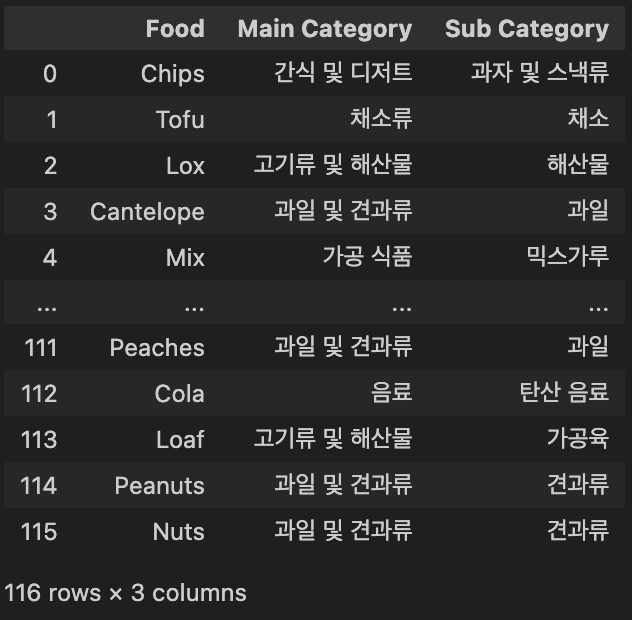
category = pd.DataFrame(last, columns=['Food'])
# 대분류와 소분류 컬럼을 추가
category[['Main Category', 'Sub Category']] = category['Food'].apply(lambda x: pd.Series(assign_category(x)))
# 결과 출력
category- 결과:
# 'Food' 컬럼을 기준으로 원래 df와 category 데이터프레임 병합
df = pd.merge(df, category, on='Food', how='left')그 다음은 도매/소매 나누기. 아마존 데이터가 도매/소매로 분류되는게 아니라 사실 모두 도매 전자상거래. 그래서 대량으로 살수록 개당 가격이 저렴해지는 특성 때문에 Discount Amount가 모든 행마다 있는 것이 아닐까? 이렇게 생각해서 도매/소매로 처음에는 나누려고 했다. 그래서 평균 * 1.3 을 임계치로 설정하여 그 이하는 소매, 반대는 도매로 설정했었다.
그리고, Imagine Pancake Mix처럼 제품 하나의 정가가 몇 백만원씩 하는 제품들이 꽤 있다. 이런 제품들에 대해서 어떻게 처리하면 좋을지 고민이 됐다.
- 그래서 이에 대해 같은 이름을 갖는 제품들을 필터링 후 같은 제품인데 다른 List Price가 있다면 그 둘을 나눠 수량을 추론해볼 수 있지 않을까? 라는 생각을 했다.
이 두가지에 대해 아무리 고민해도 명확한 해결책이 떠오르지 않아서 튜터님께 질문을 드렸고 다음과 같은 답변을 받았다.
- 도매/소매로 나눴는데 괜찮은가?
- 이 데이터에서 얻을 수 있는 충분한 근거가 부족하기 때문에 위험할 수 있다.
- 그러면, 도매/소매 대신에 대량구매, 소량구매로 카테고리를 나눠서 분석을 하는건 어떨까요?
- 굿
- Imagine Pancake Mix처럼 제품 하나의 정가가 몇 백만원씩 하는 제품들이 꽤 있다. 이런 제품들에 대해서 어떻게 처리하면 좋을지 고민 중이다.
- 같은 이름을 갖는 제품들을 필터링 후 같은 제품인데 다른 List Price가 있다면 그 둘을 나눠 수량을 추론해볼 수 있지 않을까요?
- 이 또한 위험할 수 있다. 이 데이터를 통해 SKU를 알아낼 수 없기 때문에 좋지 않은 방법이다.
- 그러면 비상식적이다라고 생각하는 기준을 세워서 그 기준을 넘는 제품들에 대해 Item 명과 Item Number 를 같이 비교하면서 그 가격이 합당하지 않은 제품이라면 box 단위로 보는 것은 어떨까요?
- 굿굿
- 같은 이름을 갖는 제품들을 필터링 후 같은 제품인데 다른 List Price가 있다면 그 둘을 나눠 수량을 추론해볼 수 있지 않을까요?
그래서 결론은 :
- 도매/소매 → 대량구매/소량구매
- 비상식적인 가격의 제품들 → 기준을 세워서 그 기준을 넘는 제품들에 대해 Item 명과 Item Number 를 같이 비교하면서 그 가격이 합당하지 않은 제품이라면 box 단위로 보자!
대량판매/소량판매 기준 나누기
amount_threshold = df['Sales Amount'].mean() * 1.3 # 매출 금액 기준 (Sales Amount의 평균 2744.115588)
# 두 가지 기준을 함께 고려하여 소매와 도매로 구분
df['Sales Type'] = df.apply(lambda row: '소량판매' if (row['Sales Amount'] <= amount_threshold) else '대량판매', axis=1)
df['Sales Type'].value_counts()- 결과:
Sales Type 소량판매 51462 대량판매 5883 Name: count, dtype: int64
# 그래프의 크기 설정
plt.figure(figsize=(12, 8))
# scatterplot 그리기
sns.scatterplot(data=df, x='Sales Amount', y='Sales Quantity', hue='Sales Type', palette={'대량판매': 'blue', '소량판매': 'green'}, alpha=0.6)
# 그래프 제목 및 축 라벨 설정
plt.title('Scatterplot of Sales Quantity vs. Sales Price')
plt.xlabel('Sales Amount')
plt.ylabel('Sales Quantity')
# 범례 추가
plt.legend(title='Sales Type')
# 그래프 표시
plt.show()-
결과:
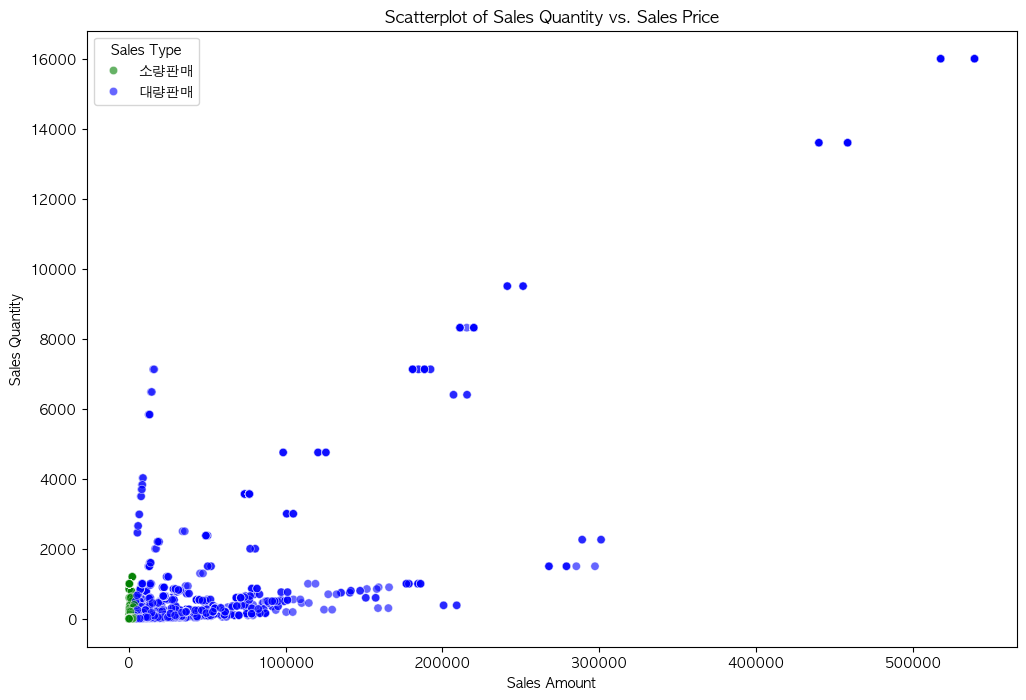
- 대량판매/소량판매 결과 꽤 합당해 보인다.
정가 기준 판매 카테고리 나누기
예를 들어 Imagine Pancake Mix 처럼 1 개 단위의 정가가 몇 백만원인 제품들이 많이 있다. 상식적으로 팬 케이크 반죽이 몇 백만원이나 하는 것은 옳지 못하다고 생각.
그래서, 이런 제품들에 대해 기준을 세워 그 기준을 넘는 제품들은 Item 을 살펴보며 합당하면 개별 단위로 보고, 그게 아니라면 Box 단위로 보고자 한다.
기준: 상위 25%
# List Price의 평균 계산
list_price_q3 = df['List Price'].quantile(0.75)
# 판매 유형을 구분
def categorize_sale(row):
# Sub Category가 '육류', '해산물', '알코올'인 경우 무조건 개별판매
if row['Sub Category'] in ['육류', '해산물', '알코올 음료']:
return '개별판매'
# List Price가 평균 이상인 경우 박스판매, 그 외에는 개별판매
elif row['List Price'] >= list_price_q3:
return '박스판매'
else:
return '개별판매'
# 새로운 컬럼 '판매 유형' 추가
df['Pricing Category'] = df.apply(categorize_sale, axis=1)df['Pricing Category'].value_counts()- 결과:
Pricing Category 개별판매 46349 박스판매 10996 Name: count, dtype: int64
df.info()- 결과:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 57345 entries, 0 to 57344 Data columns (total 24 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Custkey 57345 non-null int64 1 DateKey 57345 non-null datetime64[ns] 2 Discount Amount 57345 non-null float64 3 Invoice Date 57345 non-null datetime64[ns] 4 Invoice Number 57345 non-null int64 5 Item Number 57345 non-null object 6 Item 57345 non-null object 7 Line Number 57345 non-null int64 8 List Price 57345 non-null float64 9 Order Number 57345 non-null int64 10 Promised Delivery Date 57345 non-null datetime64[ns] 11 Sales Amount 57345 non-null float64 12 Sales Amount Based on List Price 57345 non-null float64 13 Sales Cost Amount 57345 non-null float64 14 Sales Margin Amount 57345 non-null float64 15 Sales Price 57345 non-null float64 16 Sales Quantity 57345 non-null int64 17 Sales Rep 57345 non-null int64 18 U/M 57345 non-null object 19 Food 57345 non-null object ... 22 Sales Type 57345 non-null object 23 Pricing Category 57345 non-null object dtypes: datetime64[ns](3), float64(7), int64(6), object(8) memory usage: 10.5+ MB Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
그리고 오늘 추가적으로 데이터의 정합성에 대해 고민하던 중 Sales Margin Amount가 음수인 데이터, Sales Cost Amount가 0인 데이터도 찾게 되어 이런 데이터들은 분석의 방향성에 맞지 않다고 생각되어 데이터에서 제외해줬다.
내일 할 일
- KPI 지표 Tableau로 그려보기
- 시각화 차트 그려보기
- 가능하다면 파이썬으로 RFM 분석도 해보기
