BeautifulSoup
BeautifulSoup은 파이썬 라이브러리로, HTML 및 XML 파일을 파싱하고 구문 분석하는 데 사용된다. 간단한 구문으로 웹 페이지의 특정 요소를 쉽게 추출할 수 있다.
- 파싱이란?
- 웹페이지에서 원하는 데이터를 추출하여 가공하기 쉬운 상태로 바꾸는 것.
장점
- 사용이 간편: 간단하고 직관적인 구문을 제공합니다.
- 빠른 파싱: 정적 HTML 문서를 빠르게 파싱할 수 있습니다.
- 가벼움: 시스템 리소스를 적게 사용합니다.
- 다양한 파싱기 지원: lxml, html.parser 등 다양한 파싱기를 지원하여 유연하게 사용할 수 있습니다.
단점
- 동적 콘텐츠 처리 불가: JavaScript로 생성된 동적 콘텐츠를 처리할 수 없습니다.
- 브라우저 상호작용 불가: 브라우저 자동화 기능이 없으므로, 페이지 상호작용은 불가능합니다.
- 에러 처리 제한: 잘못된 HTML 문서를 처리할 때의 에러 처리 능력이 제한적입니다.
BeautifulSoup 실습
실습 목표: 네이버 증권 페이지에서 TOP 종목 리스트와 그 현재가를 크롤링하기!
- 라이브러리 불러오기
from bs4 import BeautifulSoup
import requests- 네이버 증권 페이지 url
url = 'https://finance.naver.com/'requests라이브러리를 사용하여 네이버 증권 페이지 가져오기
response = requests.get(url)
response.encoding = 'euc-kr' # 한글 인코딩 설정
html = response.text- BeautifulSoup으로 파싱
soup = BeautifulSoup(html, 'html.parser')soup 를 확인해보면 다음과 같이 파싱이 잘 된 것을 확인할 수 있다.
결과:

- 원하는 html 요소 찾기
-
fn + f12 를 눌러 개발자 도구에 들어간다.
-
오른쪽 상단의 insperctor 기능을 눌러 html 을 찾고싶은 요소를 선택한다.
-
그러면 선택한 html 요소를 찾을 수 있다.
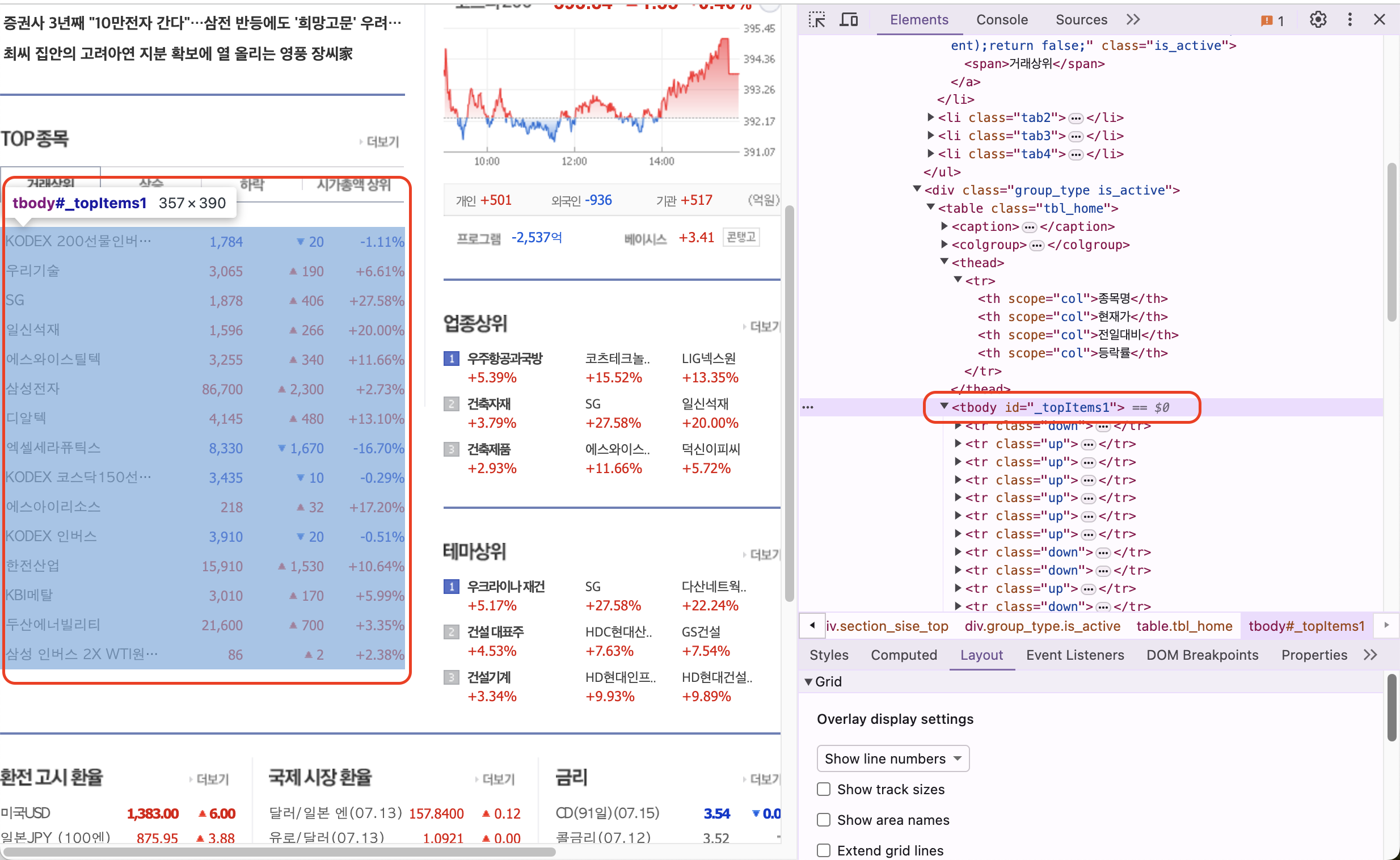
- 결과를 보면 tbody 태그의 id=’_topItems1’ 에 각 종목들이 있는것을 확인할 수 있다.
- 찾은 html 요소를 find 함수에 id 를 넘겨줘서 찾는다.
# 원하는 html 요소 찾기
top_items = soup.find('tbody', id='_topItems1')- 그러면 다음과 같은 결과가 나오는데 모든 종목들은 tr 태그 내에 있고
- 내가 찾고자 하는 종목명과 현재가는 각각 a 태그와 td 태그에 담겨있는 것을 확인할 수 있다.
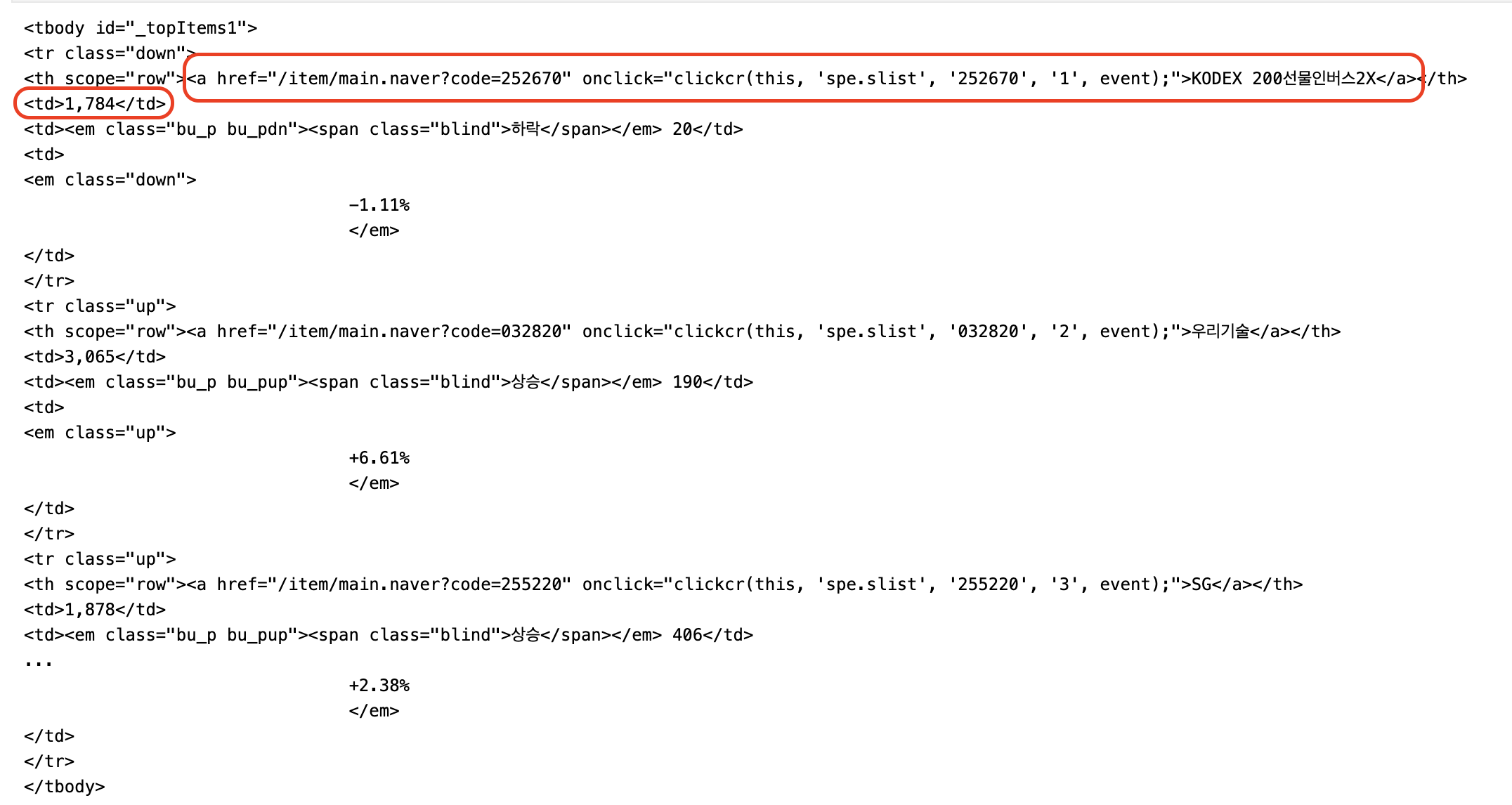
- 종목명과 현재가를 추출하여 리스트에 저장
- 찾아낸 태그들로 top_items 의 각 행들을 돌며
<tr>태그를 찾고<a>태그의 text 만을 추출해 종목명을 추출하고,<td>태그의 text 만을 추출해 현재가를 추출한다.
- 추출한 내용을 리스트로 저장하면 내가 원했던 목표를 달성할 수 있다!!
# 종목명과 현재가를 추출하여 리스트에 저장
stock_list = []
rows = top_items.find_all('tr')
for row in rows:
# 종목명 추출
stock_name = row.find('a').row.find('a').get_text(strip=True)
# 현재가 추출
current_price = row.find_all('td')[0].get_text(strip=True)
stock_list.append((stock_name, current_price))
# 결과 출력
for idx, (name, price) in enumerate(stock_list, start=1):
print(f"{idx}. 종목명: {name} | 현재가: {price}")- 종목명 추출
.get_text(strip=True)→ 앞뒤의 공백 문자 제거
- 현재가 추출
row.find_all('td')[0]→ [0] 으로 첫번째 요소를 선택한 이유는<td>태그를 검색하면 현재가, 전일대비, 등락률 이렇게 총 세개가 나오는데 그 중 우리가 원하는 건 첫번째 현재가이기 때문이다.
- 결과:
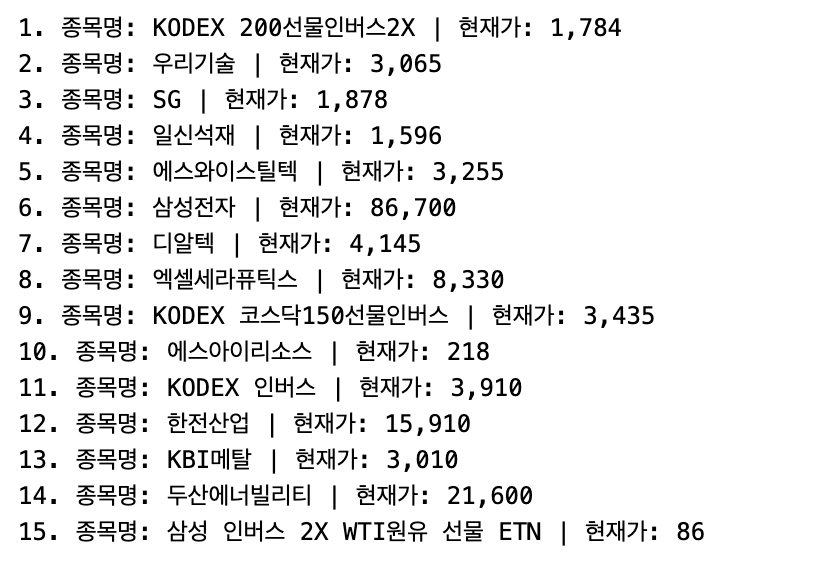
- 이제 모든 구문을 하나로 합쳐 함수로 만들면 ‘네이버 증권 페이지에서 TOP 종목 리스트의 이름과 현재가 추출’을 할 수 있다!
def get_top_stocks(url='https://finance.naver.com/'):
"""
네이버 증권 페이지에서 TOP 종목 리스트를 추출하는 함수
Parameters:
url (str): 네이버 증권 페이지 URL
Returns:
list: 종목명과 현재가가 포함된 리스트
"""
# requests 라이브러리를 사용하여 네이버 증권 페이지 가져오기
response = requests.get(url)
response.encoding = 'euc-kr' # 한글 인코딩 설정
html = response.text
# BeautifulSoup으로 파싱
soup = BeautifulSoup(html, 'html.parser')
# 원하는 html 요소 찾기
top_items = soup.find('tbody', id='_topItems1')
# 종목명과 현재가를 추출하여 리스트에 저장
stock_list = []
if top_items:
rows = top_items.find_all('tr')
for row in rows:
# 종목명 추출
stock_name = row.find('a').get_text(strip=True)
# 현재가 추출
current_price = row.find_all('td')[0].get_text(strip=True)
stock_list.append((stock_name, current_price))
return stock_list
# 함수 호출 및 결과 출력
top_stocks = get_top_stocks()
for idx, (name, price) in enumerate(top_stocks, start=1):
print(f"{idx}. 종목명: {name} | 현재가: {price}")
데이터분석 공부 일기~!