
Selenium 이란?
Selenium은 웹 애플리케이션을 테스트하기 위한 프레임워크이다. 웹에 하는 명령을 코드화시켜서 작동시키며, 다양한 브라우저 작동을 지원하며 크롤링에도 활용된다.
크롤링에서는 정적, 동적 페이지 크롤링으로도 접근이 불가능한 데이터에 접근할 때 유용하게 사용된다.
장점
- 동적 콘텐츠 처리: JavaScript로 생성된 동적 콘텐츠도 처리할 수 있습니다.
- 다양한 브라우저 지원: Chrome, Firefox, Safari, Edge 등 다양한 브라우저를 지원합니다.
- 다양한 언어 지원: 여러 프로그래밍 언어를 지원하므로 기존 개발 환경과 쉽게 통합할 수 있습니다.
- 광범위한 기능: 브라우저 조작, 요소 상호작용, 화면 스크린샷 등 다양한 기능을 제공합니다.
단점
- 속도: 브라우저를 직접 구동하므로 상대적으로 느립니다.
- 설치 및 설정: 브라우저 드라이버 설치 및 설정이 필요합니다.
- 리소스 사용: 브라우저를 실행하므로 메모리와 CPU 리소스를 많이 사용합니다.
- 단순 텍스트 스크래핑에는 과도: 단순히 HTML 데이터를 추출하는 경우에는 과도하게 복잡합니다.
Selenium 간단 실습 해보기
-
라이브러리 불러오기
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome()그러면 이렇게 새로운 크롬 창이 뜬다.
-
크롬창에 url 을 넣어서 해당 url 로 이동하도록 코드를 짜보자.
- get(url) 을 통해 지정한 url 로 이동할 수 있다.
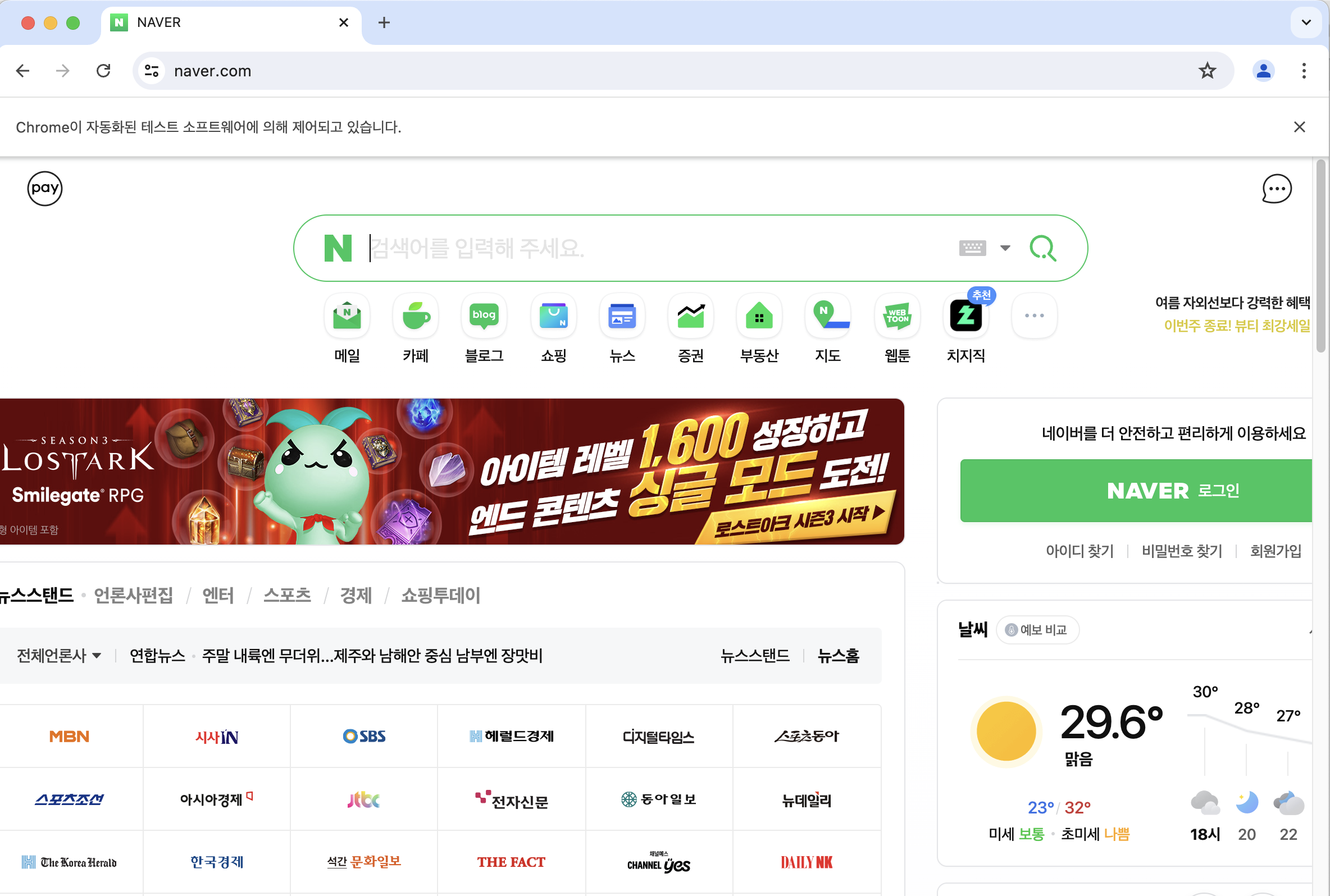
url = 'https://www.naver.com' driver.get(url)그러면 이렇게 네이버로 이동한 것을 확인할 수 있다.
-
어제 공부했던 크롤링 방법을 참고해서 네이버 검색창에서 삼성전자 주식을 검색하는 코드를 작성해보자
참고: https://velog.io/@ehdtkd98/개인공부-웹-크롤링과-비동기-프로그래밍
- 먼저 개발자도구(fn + f12)를 사용하여 검색창의 코드 위치를 알아낸다.
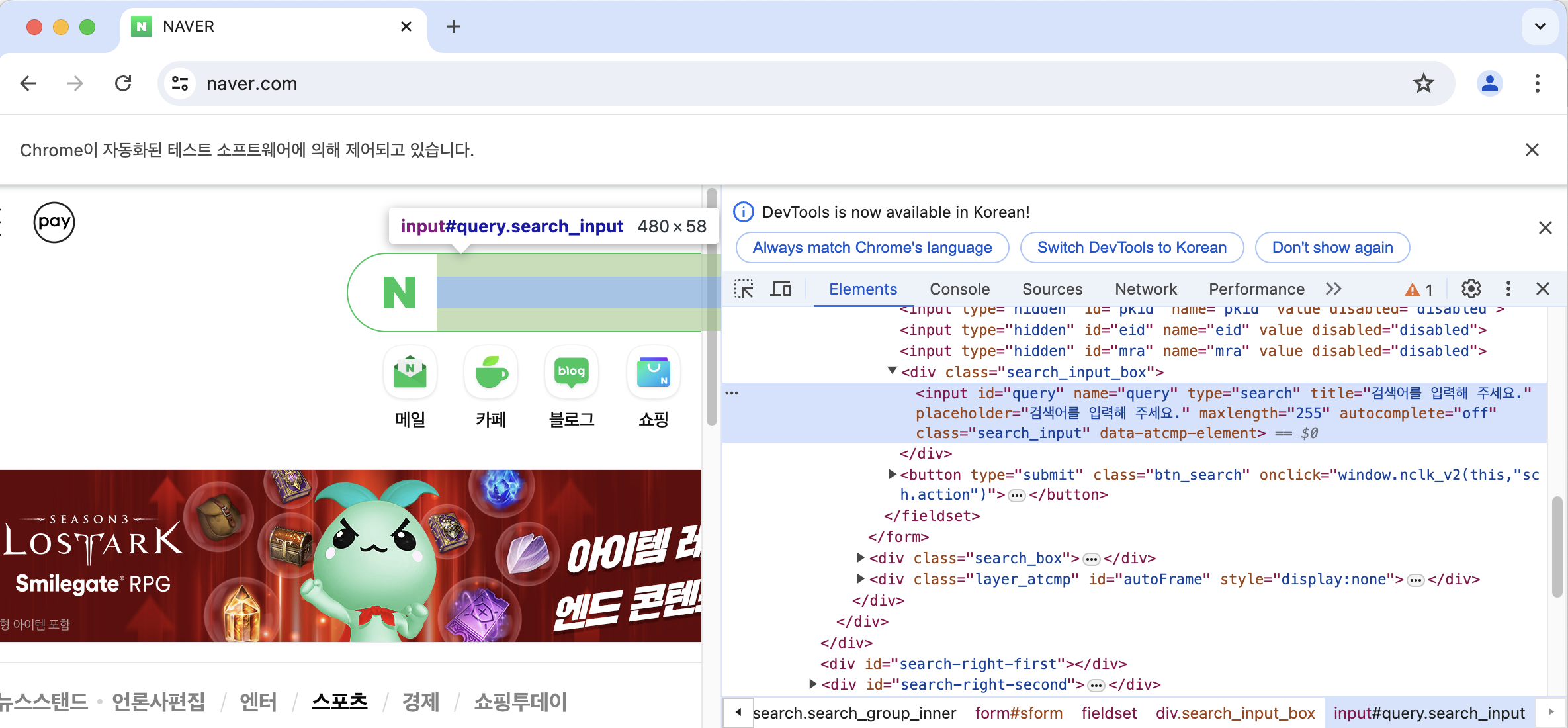
- 위치를 알아냈으면 selenium 의 XPath 로 특정 요소에 접근할 수 있는 경로를 알아내자
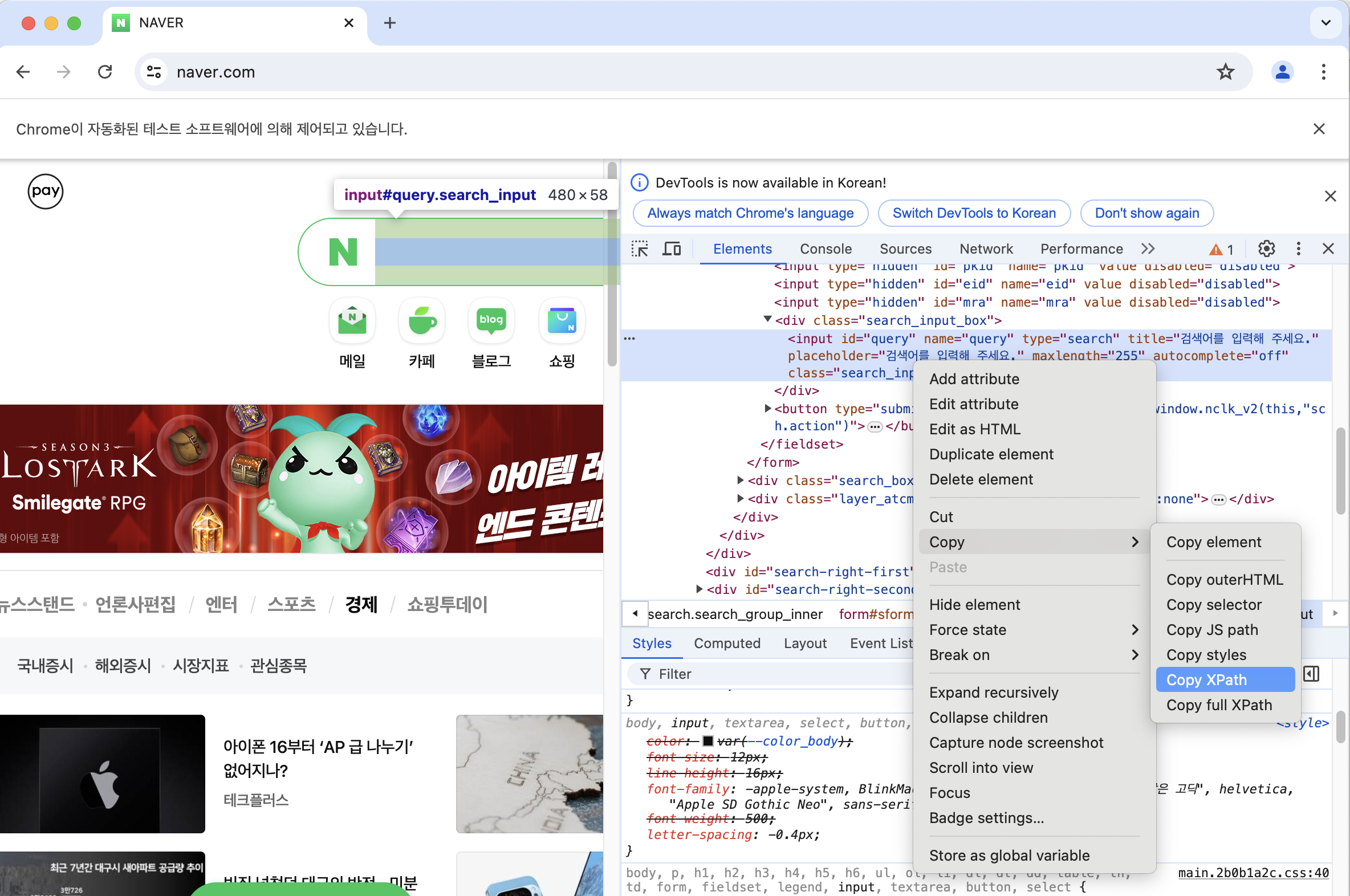
-
복사한 XPath 경로를 활용해 삼성전자 주식을 검색해보자
key_word = input('키워드를 입력하세요: ') driver.find_element(By.XPATH, '//*[@id="query"]').send_keys(f'{key_word}' + '\n')그러면 다음과 같이 입력할 수 있는 창이 뜨고, ‘삼성전자 주식’을 검색하면 ‘삼성전자 주식’ 페이지로 이동할 수 있다.

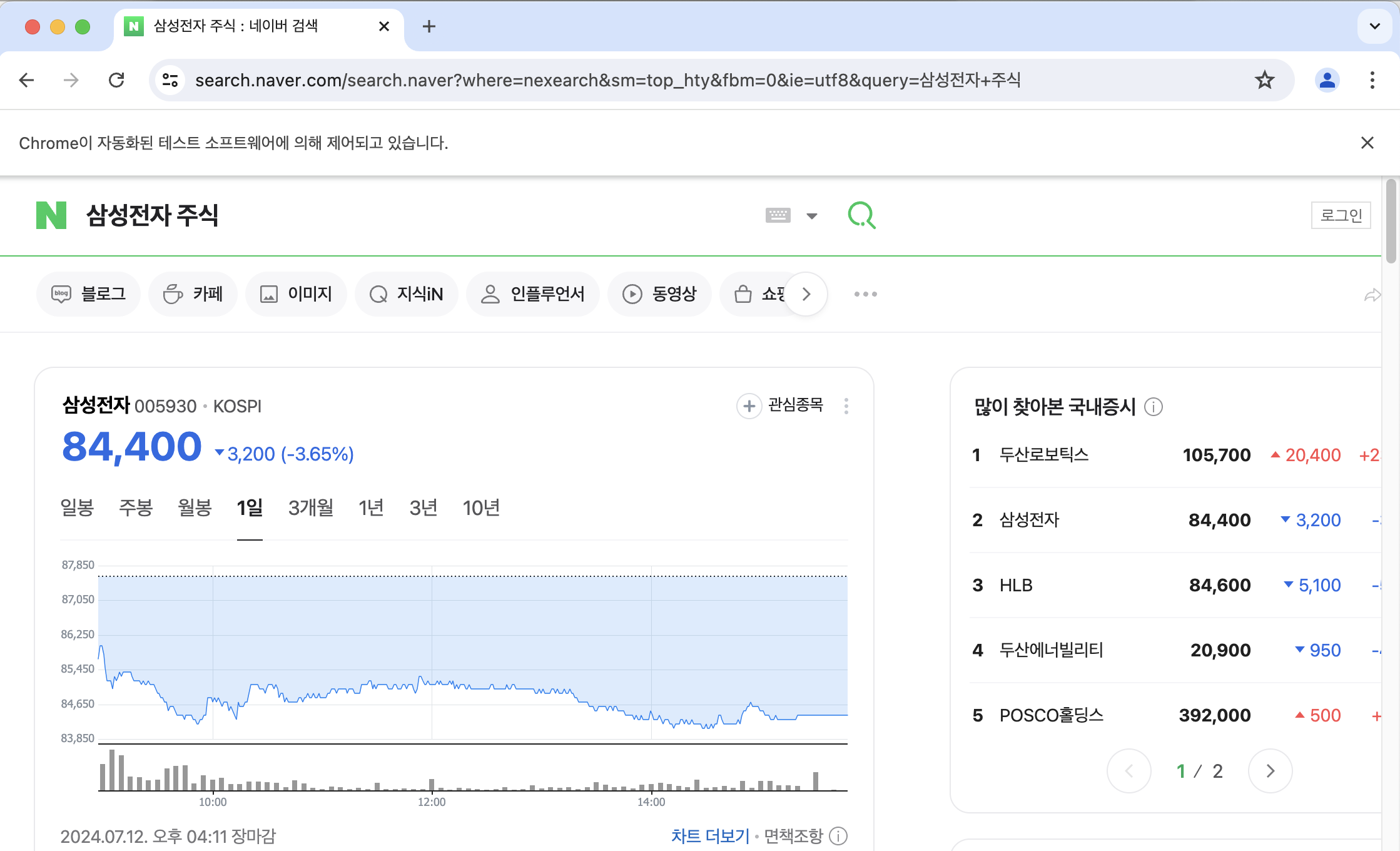
(어제 검색했을 때보다 2,600 이 떨어졌네요…!)
- 먼저 개발자도구(fn + f12)를 사용하여 검색창의 코드 위치를 알아낸다.
-
이 페이지에서 삼성전자의 더 자세한 정보들을 알고싶다면? 3번과 같은 방법으로 가능!
- 경로 복사하고
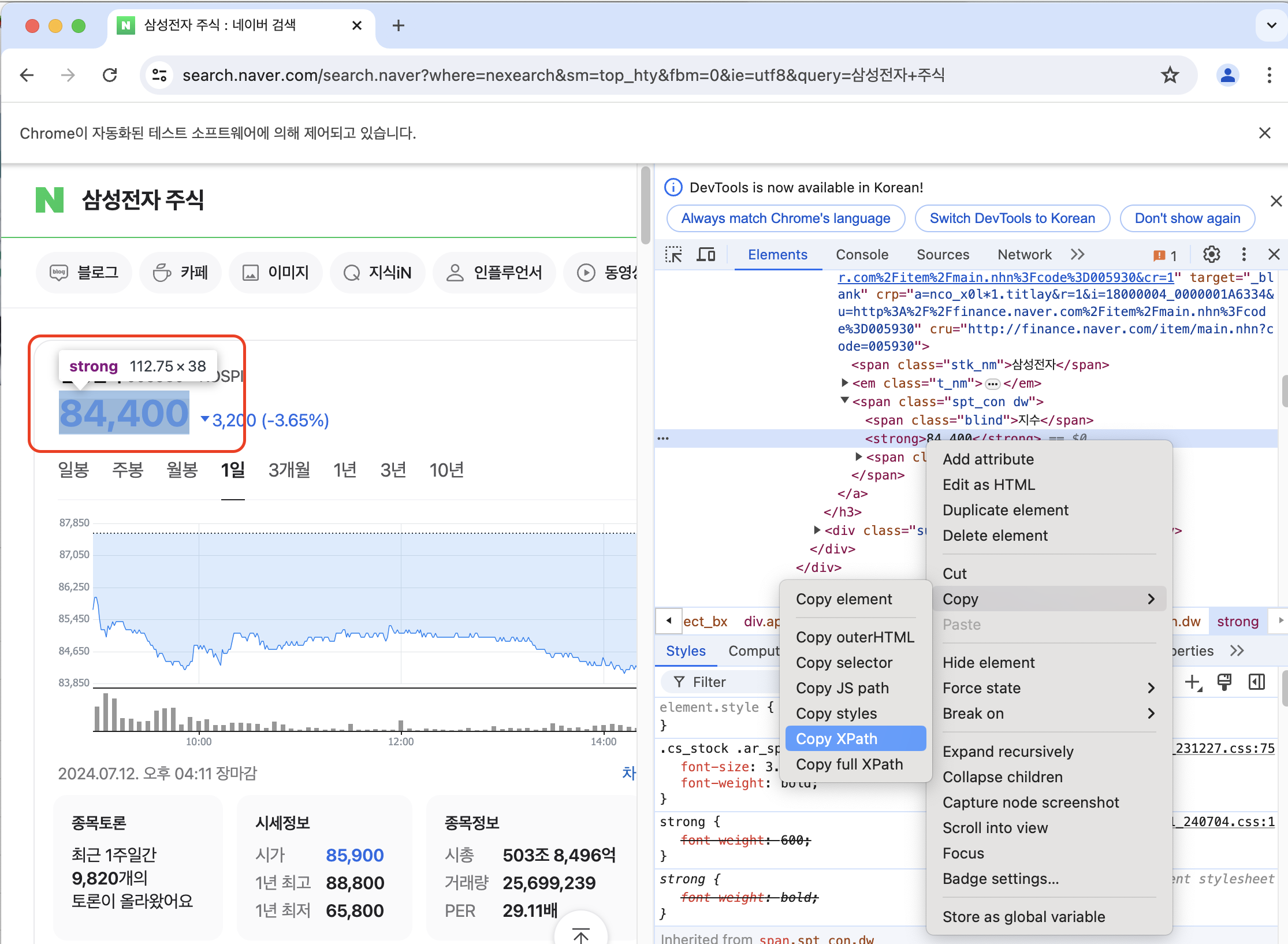
- 이번에는 검색이 아니고 클릭을 하는거니까 send_keys 를 click() 으로 바꿔주면 된다.
driver.find_element(By.XPATH, '//*[@id="main_pack"]/section[1]/div/div[2]/div[1]/div/h3/a/span[2]/strong').click()
그러면 다음과 같이 네이버 증권 페이지로 이동할 수 있다!
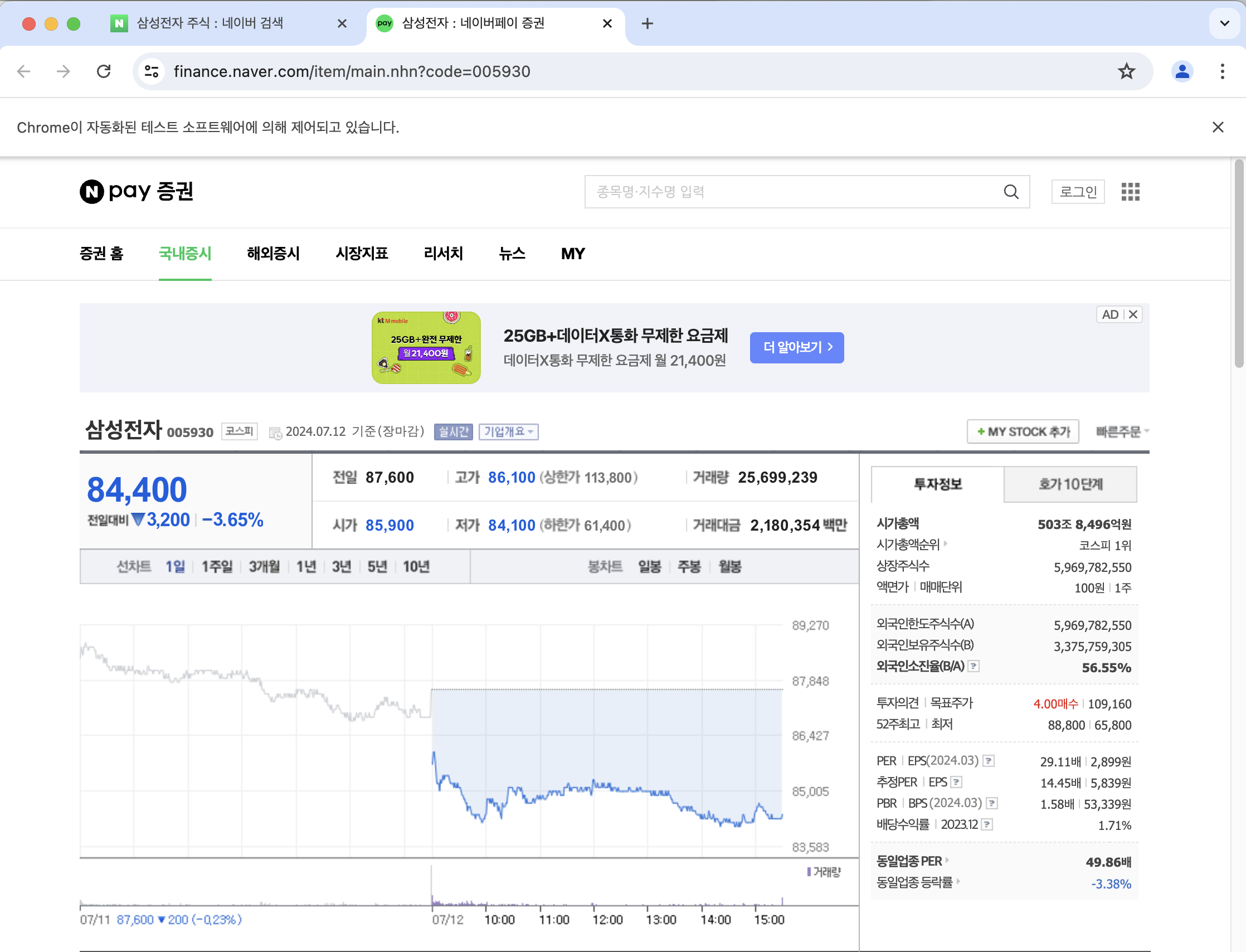
- 경로 복사하고
다음 글에서는 웹 크롤링에 사용되는 또 다른 라이브러리 BeautifulSoup 과 html 태그, 상속에 대해 공부해보도록 하겠다.

데이터분석 공부 일기~!