데이터 분석에서 사용하는 샘플링과 리샘플링
샘플링(sampling)
전체 데이터(모집단)에서 임의의 표본을 뽑아내는 것으로 표본 추출을 의미한다.
- 현실에서는 모집단 전체를 조사하는 것이 어렵거나 불가능한 경우가 많다.
- 그래서 일부를 뽑아 분석하고, 이 표본을 통해 전체의 특성을 추정한다.
리샘플링(Resampling)
이미 수집한 데이터(표본)에서 다시 데이터를 뽑는 것을 의미한다.
- 데이터를 여러 방식으로 나눠서 검증하거나
- 불균형한 데이터 문제를 해결하거나
- 통계량의 불확실성(분산)을 추정할 때 사용한다.
모델 평가, 불균형 데이터 보정, 통계적 추론 등에서 사용된다.
대표적인 리샘플링 기법
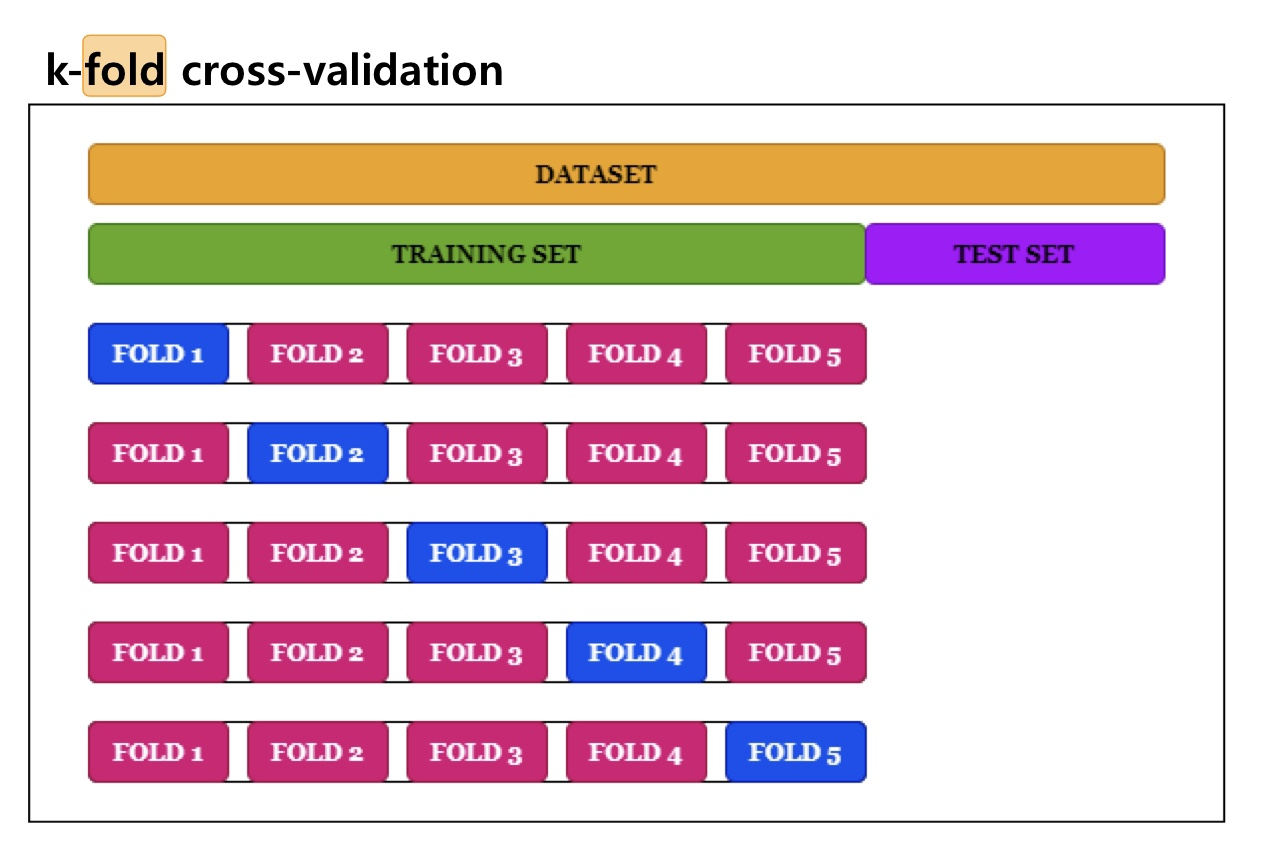
📚 K-Fold 교차 검증 (K-Fold Cross Validation)
데이터를 여러 조각(Folds)으로 나누고, 매번 다른 조각을 검증용 데이터로 사용해 학습과 검증을 반복하는 방식한다.
✔️ 작동 방식 요약
- 전체 데이터를 먼저 Training Set과 Test Set으로 나눕니다.
- Training Set을 다시 K개의 Fold로 나눕니다.
- 각 반복마다 1개의 Fold는 검증용(Validation Set), 나머지 Fold는 훈련용(Training Set)으로 사용합니다.
- 이 과정을 K번 반복하여 모든 Fold가 한 번씩 검증용으로 사용되도록 합니다.
- 최종적으로 K개의 평가 결과 평균을 계산합니다.

Hello