Classification
분류에서 이진 분류를 선형적으로 분류하는 선형 분류를 다루어 보자.
선형 분류가 선형 회귀와 어떤 관계를 가지는지도 이해하면서 알아보자.
Classification VS Regression
분류 문제는 입력에 대해서 카테고리에 속한 y값을 예측하는 형태의 문제이다.
회귀 문제는 입력에 대해서 연속한 값 y를 예측하는 형태의 문제이다.
1. Linaer Classification
Linaer Classification 중에서 카테고리가 2가지로 나누어진 Binary Classification에 대해서 먼저 알아본다.
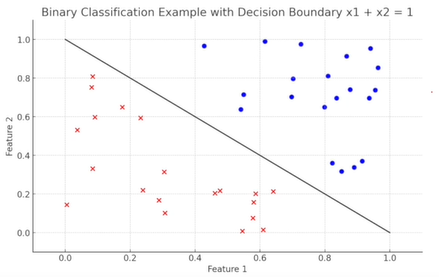
2차원으로 주어진 데이터를 좌표평면에 표현할 때, 2차원 입력에 대응되고 y가 -1과 1이 되는 경우이다.
Linear Regression에서 1차원에서 d차원으로 확장해던 것처럼 Linear Classification에서도 확장이 가능하다.
2. 지도학습에서의 Binary Classification

1. Function Class를 정의할 때, 가장 좋은 함수를 어느 집단에서 찾을 것이지 생각해야 한다.
2. 손실 함수가 좋은지 안좋은지 어떤 기준으로 판별할지 정해야 한다.
가정)
데이터가 선형적으로 분리 가능하다.
=> 데이터를 나누는 선형적인 선 혹은 Hyerplane이 존재하는 경우에 대해서 문제를 해결하도록 한다.
Regression 문제에서와 동일하게 가장 간단한 형태의 Linear Regression부터 보았듯이 동일하게 Classification 문제에서도 가장 간단한 형태의 분류기 Linear Classifier부터 본다.

Linear Classification에서 Function Class를 정의해보자.
x가 d차원에 존재하고 있을 때, 가 0을 기준으로 0보다 큰지 작은지에 따라서 결정하는 함수가 된다. Hyerplane을 그어서 위의 데이터들을 1로 아래의 데이터들은 -1로 분류하게 되는데, 경계선을 직선으로 긋겠다는 의미이다.
해당 함수가 판별을 잘하는지 기준을 정의해보자.
손실 함수를 0-1 loss로 분류를 데이터 포인트에 대해서 할 때, 정답을 맞혔는지 못 맞혔는지 카운딩하는 함수가 된다. 예측한 레이블이 +1인데 정답 레이블이 -1인 경우에는 손실값이 1이되며, 예측한 레이블과 정답 레이블이 모두 -1인 경우에는 손실값이 0이 된다. 실제 손실값은 각 포인트에서 예측과 정답을 비교하게 되며 얼마의 비율로 잘 못 맞혔는지 평가하는 함수가 된다.
가정에서 세웠던 것을 정리하면, 정답을 100% 맞히는 분류기가 하나는 반드시 존재한다. 즉 손실이 0이 되도록 만드는 완벽한 분류기가 존재한다고 가정한다. 해당 가정에 따라 올바르게 분류하는 직선 분류 알고리즘을 찾기 위한 방법으로 Perceptron Algorithm이 있다.
Perceptron Algorithm
- 데이터에 대해서 임의로 직선을 그어 데이터를 잘못 분류한 데이터들 기준으로 a,b 값을 업데이트하고 일련의 과정을 반복하여 올바른 분류기로 수렴하게 된다는 알고리즘이다.
- Gradient Descent 알고리즘과는 다르게 매 순간 잘못 분류되어 있는 점을 찾아서 a,b 값을 업데이트하고 다시 잘못된 것을 찾아 이를 반복하게 된다.
- 선형적으로 분리 가능해서 데이터를 올바르게 분류하는 선형 분류기가 하나 이상 존재한다면 반드시 특정 완벽한 분류 알고리즘으로 수렴한다는 것을 증명한다.
- 만약 선형 분류기를 할 수 없는 상황일 떄는 해당 알고리즘이 멈추지 않고 영원이 돌게 된다.

Linear Programming
- 최적화를 하기 위해서 지켜야 하는 제약 조건은 분류기에서는 가 양수이면 y는 +1이여야 하고, 가 음수이면 y는 -1이여야 한다. 가 모든 데이터 포인트에 대해서 양수이면, 올바르게 모든 데이터를 분류했다고 할 수 있다.
- Linear Classification 문제를 Linear Programming로 치환해서 풀게 되면 목표는 없고, 제약 조건만 가지는 형태의 최적화 문제를 해결하는 것이다.
- 조건이 선형이고 목표도 선형적인 경우의 문제는 특별히 최적화에서 Linear Programming으로 다룬다.

Linear Programming는 Perceptron Algorithm과 다르게 정답이 없는 경우에는 최적화를 실행하지 않는다. 정답 솔루션이 존재하지 않는 경우에 알려준다는 장점을 가진다.
옳다고 판다는 솔루션이 여러개 존재하는 경우에 어떤 것을 줄지 알 수 없다.

이때 Margin을 이용해서 분류기를 선택한다. Margin은 각 점으로부터의 거리가 되며, 모든 점으로부터 직선상의 거리를 보았을 때 가장 짧은 거리를 Margin으로 계산한다. Margin이 큰 값을 가지는 분류기가 더 견고하다고 본다.
3. SVM
Margin을 Maximized하는 분류기를 찾는 문제를 Support Vector Machine이라 한다.

margin값인 d를 최대화하는 것으로 a, b의 scaling을 통해서 값이 유지가 된다. 이 말은 와 가 같은 것으로 분자값인 를 1로 고정하고 분모인 가 제일 작아지면 최종적으로 margin값인 d가 최대화된다는 것으로 생각하는 것이 SVM이다.
SVM은 Convex problem(볼록) 카테고리에 들어가기 때문에 효율적으로 해결할 수 있는 전용 알고리즘들이 존재한다.
최적화하고자 하는 목표가 quadratic 함수(이차함수)일 때, 목표와 제약 조건이 모두 quadratic하기 때문에 결론적으로 QCQP (quadratic constrained quadratic program) 카테고리에 속하게 된다. 선형도 quadratic의 일부이기 때문에 제약 조건도 quadratic이 된다. QCQP에 해당하는 것은 Linear Programming가 쉽게 해결된 것과 같이, 효율적으로 해결할 수 있는 전용 알고리즘이 있다.
- 여러 개의 솔루션이 존재한다면 margin이 큰 솔루션을 사용하는 것이 합리적이다.
- SVM 알고리즘을 사용해서 margin이 큰 솔루션을 찾을 수 있다.
4. Soft-margin SVM
데이터가 선형적으로 완벽하게 분류되지 않는 경우가 훨씬 더 많다. 이런 경우를 Slack Variable이라는 개념을 SVM에 추가하여 해결할 수 있다.

기존의 SVM은 를 최소화하고, 제약 조건이 전체값 이 1보다 커야 한다는 것이다. 올바르게 분류되면서 margin이 1이상이여야 한다는 것을 제약 조건으로 가진다.
모든 점이 조건을 만족할 수 없다면, 각 점마다 추가로 패널티를 사용해서 제타_i를 넣어서 해결한다. 제타값이 0인 경우가 가장 좋은 경우이고, 올바르게 분류되지 않은 점들에 대해서 제타값이 그나마 적게 사용한다.
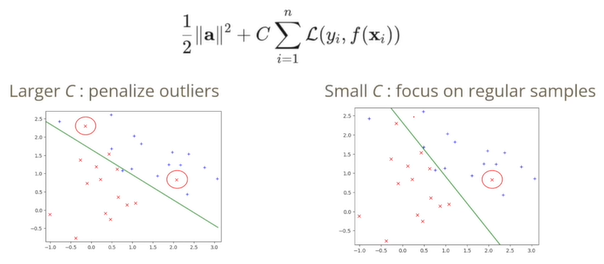
잘못 분류되어 있는 값을 심각하게 받아드리면 C값들이 커져야 하고, 좀 잘못 분류해도 괜찮은 경우에는 C값들이 작아야 한다.
Hinge Loss
Hinge Loss를 사용해서 최적화 문제를 작성해보자.
기존의 최적화 문제는 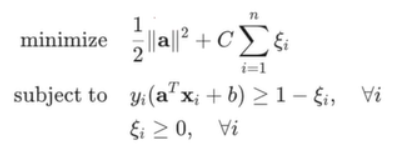 였는데,
였는데,
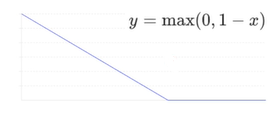
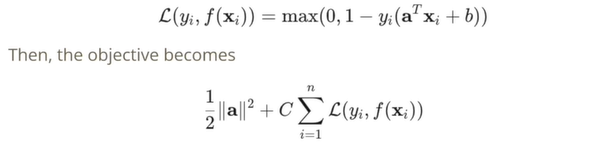
제타_i가 전부 0 이상이여야 하면서, Hinge Loss라는 라는 함수를 이용하면 목표를 최소화하는 문제로 바꿀 수 있다. 이로써 간단하게 손실함수를 표현할 수 있다.
선형 분류기는 선형 회귀와 같이 직선을 이용해서 표현한느 것이 불충분하다면, 다른 복잡한 함수를 사용하는 경우는 quadratic한 Kernel를 사용해서 해결할 수 있다.
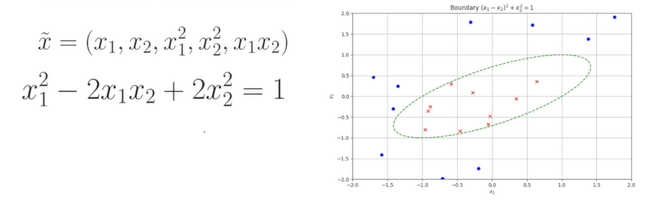
표현할 수 있는 함수의 형태가 커지면서 데이터를 더 올바르게 표현할 수 있다. 하지만 kernel를 추가하게 되면 overfitting에 빠지게 될 수 있다.
정리)
-
올바르게 분류하는 선형 분류기가 존재한다면, Perceptron Algorithm 알고리즘이나 Linear Programming 알고리즘을 사용하여 찾을 수 있다.
-
SVM 알고리즘은 0-1 손실을 사용하여 분류하는 알고리즘이다.
-
SVM은 여러 개의 존재하는 정답들 중에서 margin이 최대화되는 형태의 분류기를 찾는다.
-
올바르게 분류하는 분류기가 조재하지 않는다면, Soft-margin SVM 알고리즘을 사용하여 찾을 수 있다.
-
0-1 손실을 사용하면, 손실이 미분 가능하지 않아 지도 학습 맥락에 적용이 가능한 Gradinet Descent 알고리즘을 사용할 수 없는 문제가 발생한다.
-
이를 로지스티 회귀를 사용해서 손실함수가 미분 가능한 형태로 근사해서 문제를 해결할 수 있다.
