Gradient Descent
지도학습의 다양한 문제들에 대해서 공통적으로 적용이 가능한 gradient descent 알고리즘에 대해서 알아보자.
gradient descent에는 다양한 파라미터와 튜닝 알고리즘이 존재한다. 각 파라미터들을 바꿨을 때 알고리즘이 어떤 차이가 발생하는지 확인해보고 이해하자.
1. Gradient Descent 개념
지도 학습을 구성하는 요소들은 다음과 같다.
- 입력x와 그에 대응되는 정답y 쌍이 총 n개 있다고 가정
- 함수 클래스 g중에서 제일 잘하는 함수를 찾겠다
- 함수가 얼마나 잘하는지 평가하는 손실함수 (MSE, 평균제곱오차)
- pointwise loss를 데이터 포인트에 대해서 다 더해진 손실함수 L를 최소화한다.
현실적으로 큰 차원의 입력이 있는 경우에는 손으로 해결할 수 없기에 gradient descent 방법을 사용하게 된다. 딥러닝 네트워크를 사용하거나, 최적화하고자 하는 파라미터가 매우 커지거나, 복잡한 손실함수를 사용하는 경우에서 gradient descent를 사용하는 것이 좋은 솔루션이 된다.
기존에는 미분을 통해서 미분값이 0이 되는 지점을 후보군으로 추리고 누가 최소인가를 찾아서 그 지점이 최소점일 것이라고 생각해 문제를 해결하였다. gradient descent도 gradient가 0이 되는 지점을 찾는 알고리즘이 된다. 미분 값이 0이 되는 지점이 반드시 최소값이 되는 경우는 아니다.
gradient descent의 가정
1. 함수의 gradient는 알고 있다. f'을 알고 있어 특정 위치에서의 미분값만 알 수 있다.
2. gobal view를 가지지 않는다. 함수를 전체적으로 바라본다면 최소점을 찾기 쉽겠지만 일반적으로 받아드릴 수 없다.
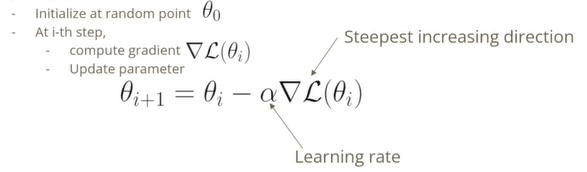
어디가 최소점일지 모르는 지점에서 시작해서 어디가 가장 가파르게 증가하고 감소하는 방향인지 gradient(미분값)를 계산한다.
- 미분값으로 이루어진 벡터는 손실함수 L이 가장 빠르게 증가하는 방향을 나타낸다.
- 부호를 통해서 -로 방향을 설정할 수 있다.
- 파라미터를 learning rate 알파만큼 곱해서 변형시킨다.
learning rate의 값이 커야되는 경우와 작아야 하는 경우을 알아보자.
learning rate는 방향을 정했을 때 가장 가파르게 감소하는 방향으로 몇 걸음을 걸을 것인가를 의미한다. 높은 값을 사용하게 되면 한 번에 먼지점으로 가게 되고, 낮은 값을 사용하며 되면 짧은 근처의 지점으로 가게 된다. step를 적게 써서 최소 지점을 찾는 것이 제일 좋은 case이다.
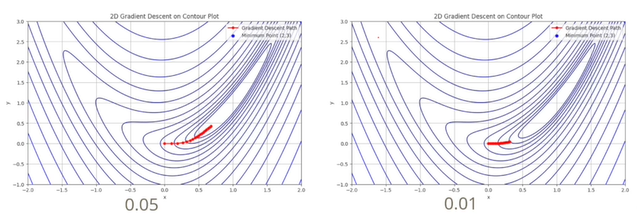
함수값에 대한 등고선은 등고선에 수직한 방향으로 이동하는 것이 gradient가 빠르게 감소하는 것이다. (0,0)에서 출발하여 대략 최소값이 (1.5, 1.5)로 이동하는 경우에서의 learning rate값이 각각 0.05와 0.01인 경우이다. 왼쪽의 경우 learning rate를 0.05로 큰 값을 부여한 경우이고, 오른쪽은 learning rate를 작은 값을 부여해 비슷한 방향으로 이동하지만 시간이 오래걸린다.
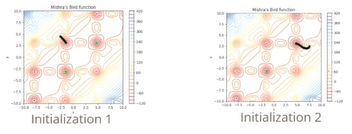
초록색 별로 표시된 두 부분이 최소값이 된다. gradient descent는 전체를 볼 수 없다. 첫번째 그림의 경우 시작점에서 빠르게 감소하는 방향으로 이동하지만 분지 형태에 빠지게 되어 나올 수 없다. 두번째 그림은 첫번째와 다른 시작점에서 시작하여 최소값에 도달할 수 있다.
- gradient가 0인 지점으로는 가지만 반드시 최소값을 보장할 수 없다.
- 같은 함수에 대해서도 초기값이 바뀜에 따라서 드라마틱하게 수렴하는 지점이 달라질 수 있다.
- 시도할 때마다 랜덤하게 initialization한다.
2. gradient descent 알고리즘
지도학습에서 목표는 pointwise loss 손실들의 합인 L을 최소화하는 문제이다. 천만개의 데이터 포인트를 매번 계산할 수는 있지만, L 이라는 손실 함수는 각 Gradient 들의 합임으로 계산 과정이 오래 걸린다.

L에 대한 gradient descent를 계산하는 것이 각 데이터 포인트에 대해서 Gradient를 계산해서 평균을 낸 것이 전체 Gradient가 되고, 이 Gradient를 이용해서 세타라는 파라미터를 업데이트해주는 것이 gradient descent 알고리즘이다.
3. SGD 알고리즘
n번 계산하는 방법을 Stochastic Gradient Descent를 사용해 간단하게 한다.

SGD는 한 iteration(반복)에서 n개의 gradient 평균을 내는 것이 아니라 데이터를 랜던하게 하나 뽑고, 하나 뽑은 데이터의 gradient를 대표로 대신 사용한다.
4. Mini-batch Gradient Descent 알고리즘
실제 gradient를 사용하지 않기 때문에 노이즈 형태의 행동을 보일 수 있고, 데이터에 따라서 들죽날죽할 수 있기 때문에 실제로 많이 사용하는 알고리즘은 Mini-batch Gradient Descent 알고리즘이다.

데이터를 하나 뽑는 것이 아니라, B라고 하는 batch로 데이터 b개를 뽑는다. b개를 뽑아서 b개에 대한 gradient를 평균 낸 것을 각 iteration(반복)에서 Gradient 삼아서 업데이트를 하는 것이다.
5. 선형회귀에 Gradient Descent 적용하기
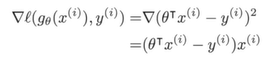
pointwise loss가 선형회귀에서는 MSE를 일반적으로 사용하였다. 미분해서 0이 되는 지점을 표준 방정식을 통해서 애널리틱하게 찾아낼 수 있다.

gradient descent를 사용해서 휴리스틱하게도 문제를 해결할 수 있다. 데이터가 너무 많거나 변수의 차원이 너무 높은 경우에 사용된다. gradient 방향으로 세타를 조금식 업데이트해 나가는 과정으로 선형 회귀 문제를 해결할 수 있다.
Gradient Descent가 적용되지 않는 경우가 발생할 수 있다. local minimize 에 갇히게 되는 경우가 발생할 수 있고, 평평한 지대에 갇혀서 더 나아지 못하고 gobal minimize를 찾을 수 없을 수 있다.
6. Gradient Descent에서의 테크닉
Gradient Descent류의 알고리즘을 적용할 때 사용할 수 있는 테크닉에 대해서 알아보자.
Momentum SGD
평평한 지점에 갇히지 않게 하기 위한 방법으로 Momentum SGD는 관성을 부여하는 방식이다.
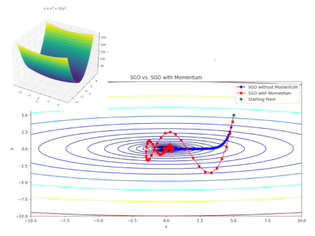
매 지점에서 가장 가파른 방향으로 나아가는 것이 아니라 산등성이에서 공을 굴리는 것과 같은 공의 관성을 부여하여 오르락 내리락하면서 수렴하는 경우이다.
그 순간에 gradient만 바라보는 것이 아니라 지금까지의 궤적을 판단해서 다음에 어디로 이동할지를 결정하는 내용이다.

베타를 0과1 사이의 값으로 하였을 때, 현재 위치에서의 gradient와 지금까지의 gradient의 총합에 선형결합으로 나타낸다. 에는 전전 gradient들이 가중된 합으로 들어가 있다.
베타가 작을수록 현재 값만 의존하는 것이고, 베타가 클수록 현재값보다는 과거의 값에 의존하는 것이다.
RMS Prop
SGD를 교정하는 테크닉 중에 하나는 RMS Prop이다.
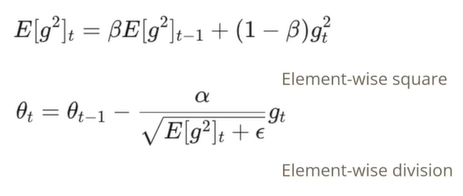
방향들에 대해서 차별화를 주는 방법이다. 현재 위치에서의 gradient를 계산할 때 gradient의 각 위치에서의 크기 값에 따라서 정규화를 적용해주는 형태이다.
Momentum SGD는 1차원 모멘텀을 진행하는 것이고, RMS Prop는 2차원 모멘텀을 생각하는 형태의 Gradient Descent의 변형이다.
ADAM
Momentum SGD와 Gradient Descent를 합친 기법이다.

Gradient의 1차원적인 모멘텀인 와 2차원적인 모멘텀 을 동시에 사용하고 bias correction을 사용해서 약간의 편향을 조정하고 1차원 모멘텀에서 2차원 모멘텀을 나누어 현재 나아가야 하는 방향을 정한다.
Learning Rate Scheduling
learning rate자체를 스케줄링하는 방법도 있다.
목적지에 다다를수록 learning rate를 작게 부여하고, 일정 에포크 동안 발전이 없으면 크게 부여하는 경우이다.
정리)
-
함수의 전체 개형을 알 수는 없지만, 임의의 점에서 어느 방향을 이동했을 떄 가장 빠르게 함수값이 줄어드는지 알 수 있다.
-
슬로프를 내려가면서 gradient가 0인 지점을 찾을 수 있다.
-
랜덤한 init를 가지기 때문에 시행에 따라서 다른 지점에 수렴할 수 있다.
-
learning rate를 적절하게 조정해서 찾아야 한다.
-
Momentum SGD는 모멘텀을 축적한다.
-
RMS Prop은 각 방향에 대한 크기에 기반해서 learning rate를 조절
-
ADAM은 1차원 모멘텀에서 2차원 모멘텀을 동시에 고려해서 learning rate를 조정해 결정
