Logistic Regression
로지스틱 회귀를 알아보기 전에 지난 시간에 대한 간단한 리뷰를 보고 가자!
- 0-1 손실을 사용하면, 손실이 미분 가능하지 않아 지도 학습 맥락에 적용이 가능한 Gradinet Descent 알고리즘을 사용할 수 없는 문제가 발생한다.
- 이를 로지스티 회귀를 사용해서 손실함수가 미분 가능한 형태로 근사해서 문제를 해결할 수 있다.
로지스틱 회귀는 binary classifiction에서 0-1 손실을 이용해서 yes 또는 no를 강제한 것과 다르게 yes의 확률이 얼마인가와 같은 soft-prediction을 사용했을 때 변화를 알아보자.
SVM과 로지스틱 회귀의 차이점과 softmax에서 이진이 아닌 여러 개의 클래스로 확장되는 경우도 알아보자.
1. Hard Guess VS Soft Guess
SVM이나 perceptron 알고리즘으로 선형 분류 알고리즘을 설계할 때 손실함수는 0-1 손실을 기반으로 한다. SVM에서 margin이 얼마나 큰가를 다룰 때, margin을 이용하면 경계에 영향을 미치는 데이터 포인트만 결정에 영향을 미치는 단점이 있다. 확실하게 분류할 수 있는 경우가 아닌 경우에는 어떤 확률로 분류하는 것이 유익하고 구별이 가능하다.
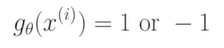
Hard Guess는 예측하는 분류는 정답을 반드시 둘 중의 하나 혹은 여러 개의 클래스 중에 하나를 선택해야 한다.
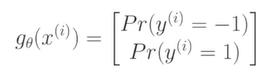
Soft Guess는 1일 확률과 0일 확률이 얼마라고 생각하는 지 말해서 결정을 사람들에게 하게 하는 것을 말한다.
2. Logistic Regression 개념
모델에 입력이 들어왔을 때 출력이 단순히 둘 중 하나만 되는 것이 아니라 1일 확률과 -1일 확률로 숫자 2개를 출력하는 형태의 모델을 사용한다.
둘 중에 하나만 내뱉는 것을 연속형 확률을 내뱉을 수 있도록 하여, 분류 문제를 회귀 문제로 변형하여 문제를 해결한다.
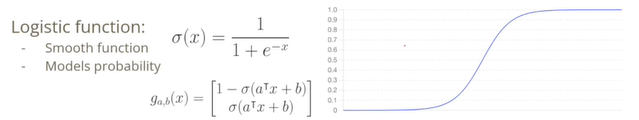
a와 b로 이루어진 파라미터들로 1일 확률과 -1일 확률이 로지스틱한 함수의 형태를 띄도록 함수를 정의한다.
3. Logistic Function
가 0보다 큰지 작은지만 표현했던 것을 0보다 크면 얼마나 큰지, 0보다 작으면 얼마나 작은지로 계산한다.
가 0보다 많이 크다면 1일 확률이 매우 높은 것이고, 가 0보다 아주 작은 음수값이라면 1일 확률이 매우 낮아지고 -1일 확률이 매우 높은 것이 된다.
경계선 부분에서는 Hard한 결정을 내리기 어렵기 때문에 Soft한 결정을 허용하도록 하는 로지스틱 회귀를 이용한다.
4. Cross Entropy Loss
비가 올 확률이 70%이고 만약 비가 온다면 이때의 손실값은 으로 Cross Entropy Loss로 계산할 수 있다. 정답에 얼마나 높은 확률로 예측하였는가를 구하는 방법이다.
- 확률을 낮게 예측을 했는데, 그 일이 실제로 발생하게 되면 예측이 잘못된 것으로 손실값이 높게 되고, - 확률을 높게 예측을 했는데, 그 일이 실제로 발생하게 되면 예측이 잘못된 것으로 손실값이 작게 된다. Cross Entropy Loss는 손실값을 작게하도록 하는 역할을 수행하는 손실함수이다. 왜 로그와 확률의 역수를 사용하는지에 대해서 알아보자.
KL divergence(relative entropy)
어떤 두 개의 확률분포가 존재할 때, 두 확률분포가 얼마나 멀리 떨어져 있는지를 나타내는 확률분포 사이의 거리를 측정하는 함수이다.
비가 올 확률이 70%, 비가 오지 않을 확률이 30%이라고 가정하고 비가 안왔다. 비가 안왔기 때문에 비가 올 확률은 0으로 사라지고 비가 오지 않을 가능성이 1로만 남게 된다. 0.7과 0.3의 분포와 0과 1의 분포 사이의 거리를 책정한다.
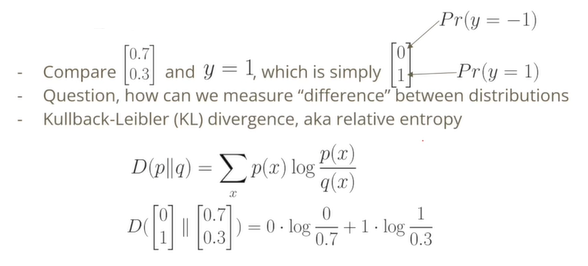
p의 역할이 정답으로 0과 1 레이블이 되고, q의 역할이 0.7, 0.3 레이블이 된다.
그럼으로 Cross Entropy Loss가 정답의 확률을 얼마나 잘 예측했는지 평가할 뿐만 아니라 확률분포 사이의 거리라는 KL divergence의 근거에 기반을 하고 있다.
Logistic Regression의 손실함수
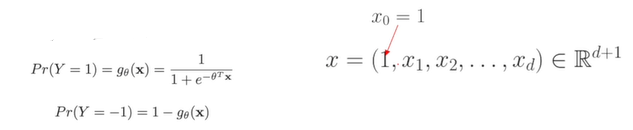
Linear Regression 에서는 를 사용하였지만, Logistic Regression 에서는 를 사용하지 않고 를 추가하여 와 유사한 형태로 만들어준다.
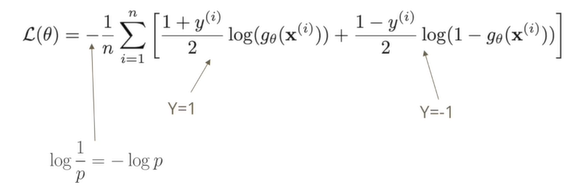
가 1일 확률로, 부분을 -1일 확률로 예측하여 손실함수는 정답이 1인 경우에는 이 확률의 역수로 구한다. 기존의 정답이 1이냐 -1이냐에 따라서 첫번 째 항만 사용하는지두 번째 항만 사용하였다면, 가 Y가 1이면 1이 되고, Y가 -1이면 0이 되는 항이다. 그럼으로 Y가 1이면 첫 번째 항만 등장하고, Y가 -1이면 두 번째 항만 남도록 한다.
는 log1/{p(Y=1)}이고, 는 log1/{p(Y=-1)}에 대응된다. 로지스틱 함수를 대입하여 계산하면 가 가 된다. 가 이였기 떄문이다.
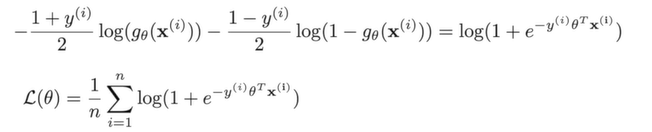
하나의 형태로 정리하여 로지스틱 회귀 손실함수를 사용할 수 있다. 들의 합으로 로지스틱 손실을 계산할 수 있다. 이로써 Gradient descent을 사용하여 최적의 를 찾을 수 있다.
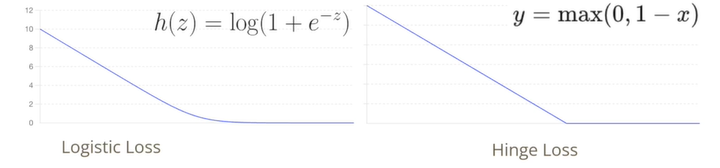
로지스틱 손실을 로지스틱 함수가 아닌 로지스틱 손실함수를 정의하면 로지스틱 손실함수의 평균으로 구할 수 있고 soft margin에서 사용했던 hinge loss와 식이 동일한 것을 확인할 수 있다. 로지스틱 회귀에서의 로지스틱 손실 함수는 hinge loss와 유사하지만 hinge loss에서 미분할 수 없는 부분이 부드럽게 바뀐 형태이다.
5. Multiclass Classification
이분법적인 분류가 아닌 클래스가 여러 개인 경우의 문제를 다중 분류라고 한다. 다중 분류는 이항 분류의 일반화로 문제를 해결할 수 있다. 이항 분류를 여러번 반복하는 형태로 풀 수도 있지만 Softmax를 사용하여 logistic regression과 유사하게 처리할 수 있다.
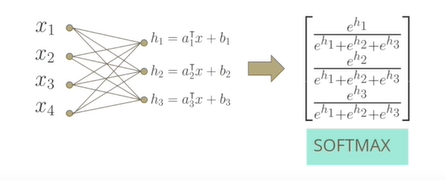
각각의 선형 함수를 통과시키고, 선형값이 모두 더해서 1이 안될 수도 있고 음수일 수도 있기 때문에 Exponential을 취해서 더한 값이 1이 되도록 정규화를 하는 softmax를 적용하여 확률과 유사한 함수를 구한다.
Softmax Function
로지스틱 함수의 일반화된 버전으로 max함수를 hard하게 max를 찾지 않고, soft하게 max를 찾는 것이다.

softmax의 총합은 1이 되고 각 값이 양수가 되도록 하는 함수가 된다.
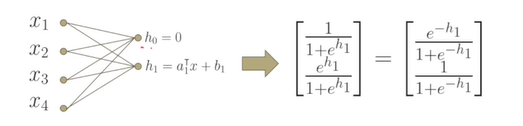
로지스틱 함수에서 어떤 확률을 구하고 반대의 경우 1에서 뺀 값을 확률로 계산하였던 것을 첫번째의 값 으로 하고, 두번째부터는 로 선형함수로 계산하여 softmax로 계산하면 로지스틱 회귀 함수와 비슷한 것을 확인할 수 있다.
지도학습에서의 Softmax Function 정의
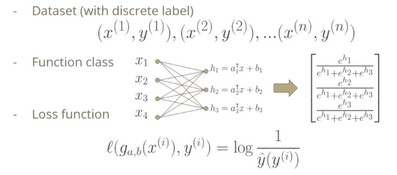
- 데이터셋은 입력 vector x와 y가 여러개의 다중 클래스 레이블을 가지며 n개 주어져 있다.
- 함수 클래스는 부터 라고 하는 입력x를 선형으로 표현하는 로 나타내 Exponential을 취하고 정규화한 결과가 함수의 최종 산물이 된다.
- 손실 함수는 Cross Entropy를 사용하여 정답에 얼마나 높은 확률을 예측했는가를 평가하여 손실을 계산한다.

d가 x에 대한 입력 차원이고 되고, k가 클래스의 개수가 된다. x 입력에 dxk라는 A 메트릭을 곱해서 각각 레이블에 대응되는 스코어를 h라는 중간값을 얻어내고, h를 softmax를 통과시켜서 함수 클래스를 정의한다.
6. False Positive, False Negative
이항 문제에서 암에 걸릴 확률이 30%이고 걸리지 않을 확률이 70%이고, 모델의 출력이 0.7 대 0.3이라고 가정한다. 이는 기준점을 50%으로 두고 있는 것이다. 이런 경우와 달리 암에 걸릴 경우에 빠르게 알려주어야 하는 것에 기준점을 주면 30%의 확률이 되더라도 반영하게 된다.
한계점이 높아서 왠만하면 암이라고 판단하지 않겠다고 한다면, 암을 정확하게 판단하겠지만 암을 놓치는 경우가 발생한다.
한계점이 낮아서 왠만하면 암이라고 판단하지 않겠다고 한다면, 암을 놓치는 경우는 없지만 암이 아닌 경우를 암이라고 오인하는 경우가 발생한다.
Precision와 Recall

Precision와 Recall 사이에는 trade-off 관계가 발생한다. 둘 다 적절하게 반영하고자 할 때는 F1-score를 사용한다.
ROC Curve
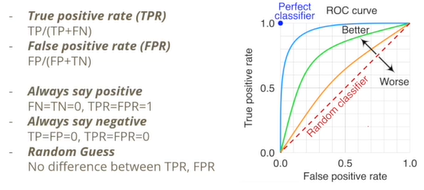
언제나 양성이라고 판단하는 테스트가 있다면, TPR과 FPR를 생각하면 둘 다 1인 경우가 발생한다.
언제나 음성이라고 판단하는 테스트를 시행한다면, TPR과 FPR를 생각하면 둘 다 0이 된다.
실제로는 한계점이 변화함에 따라서 (0, 0)으로부터 (1, 1)로 가는 형태의 tradeoff curve를 얻게 된다.
ROC Curve의 아래 면적이 넓을수록 prefect classifier에 최대한 가까이 가는 것이 있을 수록 좋은 경우이다.
정리)
- Logistic Regression은 기존의 0-1 손실이 아니라 soft guess를 허용한다.
- soft guess를 허용하기 위해 확률을 허용하여 로지스틱 함수를 이용하여 계산한다.
- 확률을 산출하는 평가척도로 cross entropy loss를 이용한다.
- class가 많아지면 softmax로 확장하여 적용한다.
