More On Supervised Learning Beyond
기존의 지도학습의 전통적인 이론들과 최근 진행되는 연구들에서 지도학습을 사용하는 예시들에 대해서 알아보자.
Linear regression과 softmax뿐만 아니라 decision tree와 random forest, boosting 등 단순하면서 효과적인 방법을 알아보자.
간단한 문제의 경우는 딥러닝을 사용하지 않고 Linear regression과 softmax뿐만으로 충분히 해결이 가능하다.
전통적으로 많이 사용한 방법들에 대해서 알아보자.
1. Naive Bayes
Naive하게 Bayes기법을 적용하는 방법이다.

x가 입력 Vector가 되고 이에 대응하는 Label Y가 주어진다.
스팸필터는 어떤 이메일이 올 때 주로 등장하는 5만 개의 단어 중에서 이 이메일이 어떤 단어를 포함하는지 0과 1로 표현할 수 있다. 어떤 이메일이 들어왔을 때 x라고 하는 입력 벡터에 대해서 y가 1로 스팸일지, y가 -1로 스팸이 아닐지 확률을 계산하는 문제이다.
이를 확률적으로 계산하는데 어려움을 가지기 때문에 문제를 해결하기 위해 Naive Bayes 가정을 한다.
가정)
- x의 벡터들이 어떤 y가 주어졌을 때 독립한다.
y가 스팸메일이라고 하는 label이 주어진다면 ,혹은 해당 메일이 스팸메일이 아니라고 하는 것이 주어져 있다면 각 단어가 등장하거나 등작하지 않을 확률이 전부 독립이다.- 독립이라는 가정을 통해서 스팸일 때 단어가 등장하는 빈도의 확률을 확률들의 곱으로써 표현할 수 있다.
스팸일 때 이 단어가 등장할 확률 또는 스팸이 아닐 때 이 단어가 등장할 확률을 계산한다.
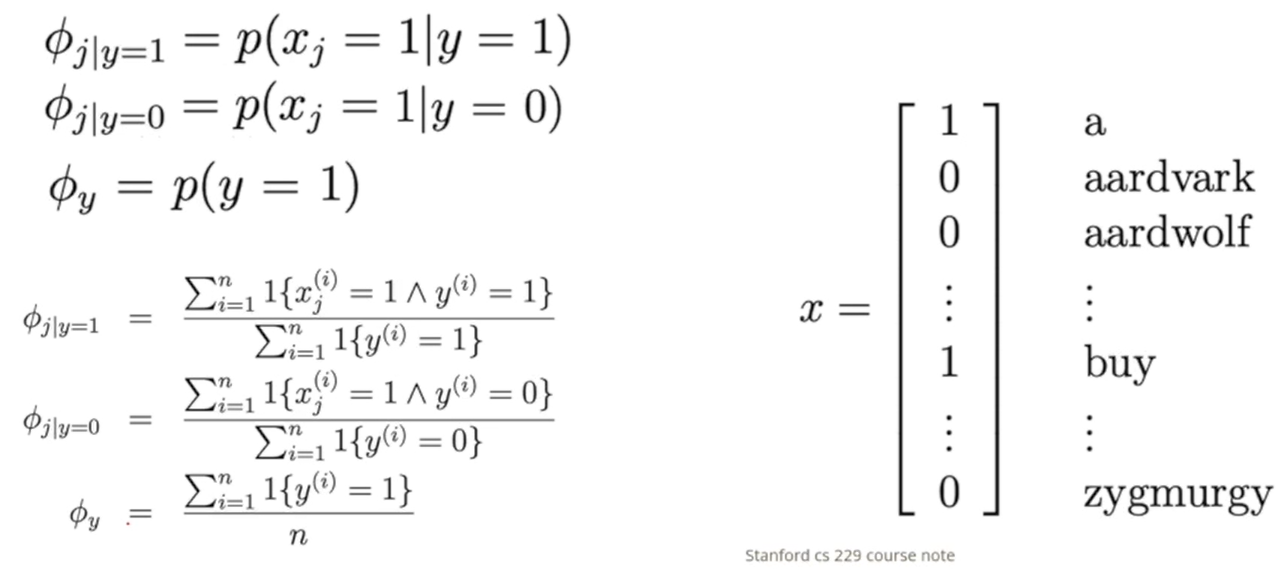
메일이 10,000개이고 스팸메일이 5,000개 있을 때, 그중 j번째 단어를 포함한 것이 몇 개 있는지를 세기만 하면 된다.
y가 1일 때의 j번째 단어의 빈도와 y가 -1로 스팸메일이 아닐 때의 j번째 단어의 빈도를 계산하고 스팸메일의 비율을 계산하면 최종적으로 확률의 역산을 베이즈 정리를 이용해서 진행할 수 있다.
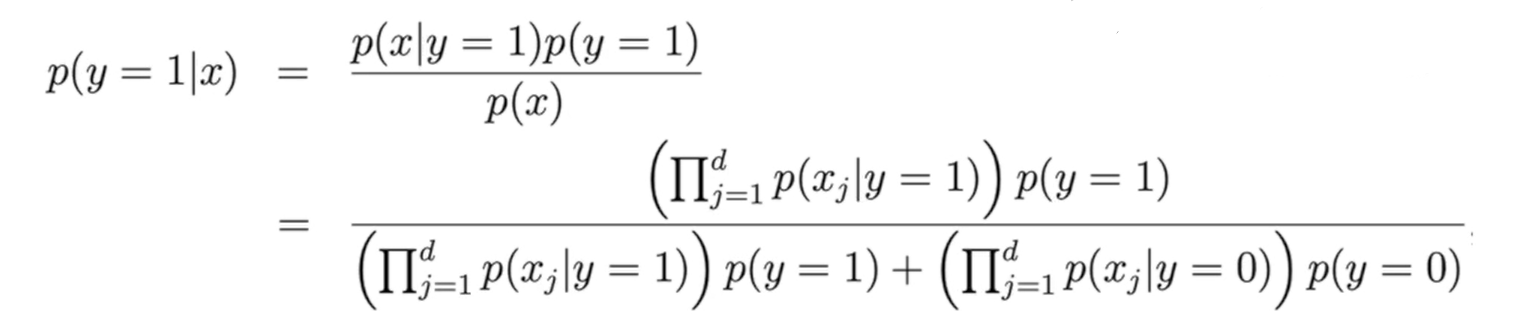
라고 하는 확률은 지금까지 계산한 것이 되고 이를 카운팅해서 계산을 할 수 있다면, 역산을 이용해서 최종적으로 어떤 x라는 입력이 들어왔을 때 해당 메일이 스팸인지 아닌지의 확률을 베이즈 정리를 통해 계산할 수 있다는 방법이 근본적인 Naive Bayes 방법이다.
주의)
- 조건부 독립이라는 가정이 현실적인 상황가 맞지 않을 수 있다.
조건부 독립을 사용함으로써 합리적으로 작동할 수 있다는 장점이 있다.
결과가 해석 가능하다는 장점이 있다.
각 단어의 어떤 단어가 스팸 메일을 결정하는 주요 인자인지 모델을 해석하는 데 사용할 수 있다. - 한번도 등장하지 않은 단어가 실제로 나오게 되면, 어떤 판단을 내려야 하는지 알 수 없다.
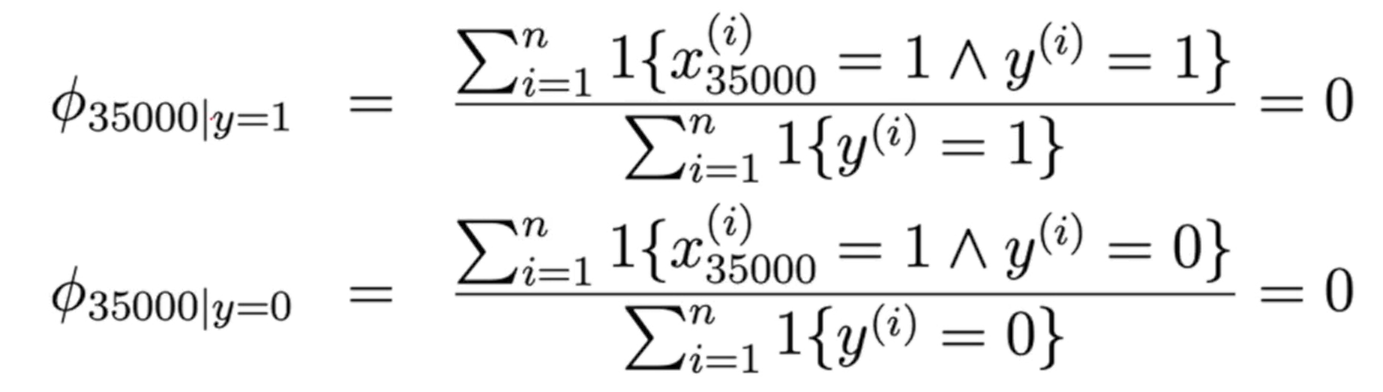
35,000번째 단어가 어떤 메일에서도 어떤 스팸 메일에서도 등장하지 않았을 때, 어떠한 영향을 주었는 모르는 상황에서 스팸인 확률과 스팸이 아닌 확류이 모두 0이 되는 문제가 발생한다.
2. Laplace Smoothing
위의 두번째 문제를 해결하기 위해 Laplace Smoothing을 사용한다.
각 단어의 등장 빈도로 스팸 메일에서 해당 단어가 몇 번 나왔는지 스팸 메일이 아닌 것에서 해당 단어가 몇 번 나왔는지 세는 형태로 비율을 추산할 때 모든 단어가 이미 한번씩은 등장했다고 가정한다.
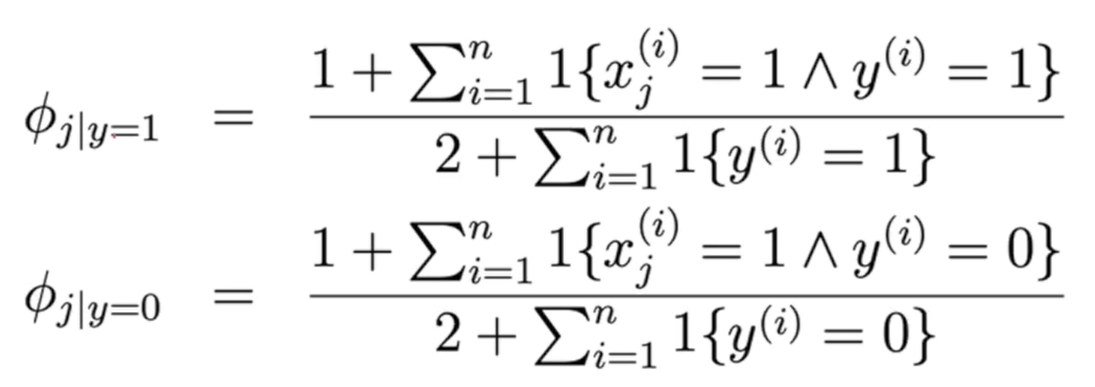
Laplace Smoothing를 사용함으로써 확률이 0이 발생하는 것을 없어지게 할 수 있다.
3. Decision Tree
의사결정나무는 해석 가능한 변수들을 해석할 수 있는 변수들을 이용해서 모델을 해석할 수 있다는 장점이 있다.
스스로 학습하는 능력이 조금 떨어지기 때문에 성능이 복잡한 과정에서는 성능면이 떨어질 수 있다.
의사결정나무에서 중간 노드들은 결정을 의미한다. 결정에서 뻗어나가는 가지들은 해당 결정에서 어떤 결론을 내렸는가를 가지고 판단해서 어느 가지로 갈 것인가를 반복적으로 결정한다. 최종적으로 Leaf node에 도달하게 되면 배정된 class label 값을 예측하는 문제에 적용한다.
Classification에서의 Decision Tree
동물이 포유류인지 아닌지 판단하는 문제일 경우를 생각해본다.

Root node : 동물이 털이 있는가? 를 기준으로 판단한다.
second node : 털이 있을 경우에 아이를 낳는가? 를 기준으로 판단한다.
단순한 질문으로 분류하는 단점이 있을 수 있지만, 전문 지식을 바탕으로 분류할 수 있으며 반복적으로 여러개를 사용해서 효과적인 분류기를 만들어 낼 수 있다.
Regression에서의 Decision Tree
집의 가격을 방의 개수와 면적으로 평가하는 문제일 경우를 생각해본다.

Root node : 집의 크기가 2,000보다 큰가요? 를 기준으로 판단한다.
second node : 방의 개수가 3개보다 많은가? 를 기준으로 판단한다.
오차나 실제 적용에는 무리가 될 수 있지만, 집의 가치를 큰 3개의 카테고리로 분류하기에는 적합하고 실제 출력도 실수값으로 예측 과제라고 할 수 있다.
-
분류의 경우, 질문을 했을 때 분할이 얼마나 균일하게 분산이 발생하는지 엔트로피와 같은 방법으로 측정해서 질문을 선택할 수 있다.
-
회귀의 경우, 질문에서의 특정한 값을 예측해야 하는 경우에는 각 leaf마다 분산이 적어서 해당 추정치를 오차가 적도록 하는 분할 기준을 선택해야 한다.
3. Bagging
의사결정나무의 응용으로 의사결정나무를 여러개 활용해서 종합적으로 앙상블 모델을 사용하여 결정하는 방법이다.
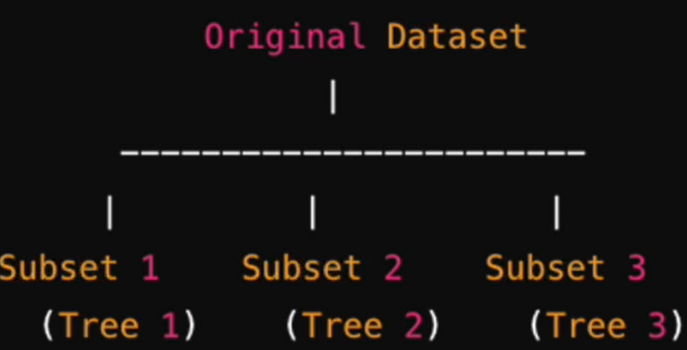
tree 1, tree2, tree3를 통해서 각각 독립적으로 평가를 하고, 평가들을 종합해서 최종적으로 결정을 한다. 특정 질문에 치우치거나 특정 데이터에 과적합하지 않고 분산을 줄일 수 있는 방법이다.
4. Random Forest
여러개의 의사결정나무를 사용해서 tree 1, tree2, tree3를 각각 독립적으로 학습시키 후에 어떤 입력에 대해서 tree 1, tree3는 포유류라고 하고 tree2는 포유류가 아니라고 한다면 종합해서 포유류라고 판단한다.
random forest는 몇몇 나무들이 비정상적으로 잘못 판단을 내리더라도 대다수의 나무가 올바른 결정을 내리기만 한다면 성능이 올라간다.
회귀의 경우에도 나무들의 값을 평균을 냄으로써 판단을 내릴 수 있다.
bagging VS random forest
bagging과 random forest의 차이점을 잘 모르겠어서 추가로 찾아서 작성해보았다.
두 기법은 모두 독립적으로 학습된 모델들의 결과를 결합하는 앙상블 방법이라는 공통점을 가진다. random forest는 bagging의 확장판으로 생각한다.
bagging은 단순 다수결이나 평균으로 독립적으로 학습된 모델의 결과를 결합한다.
- 분류 문제: 각 모델의 예측 결과 중 다수결 투표(Majority Voting)를 통해 최종 결과를 결정한다.
- 예: Tree 1, Tree 2, Tree 3이 각각 "포유류", "포유류 아님", "포유류"를 예측했다면, 다수결 결과로 "포유류"로 판단한다. - 회귀 문제: 각 모델의 예측값의 평균을 최종 결과로 사용한다.
- 예: Tree 1, Tree 2, Tree 3이 각각 5, 7, 6을 예측했다면, 평균값 이 최종 예측값이 된다. - Bagging은 데이터 샘플링(bootstrap)에만 랜덤화를 적용한다.
- 각 모델은 데이터의 서로 다른 샘플을 학습하지만, 모든 특성을 사용한다.
- 서로 다른 분류기를 예측하고 제일 좋은 하나를 선택하는 과정으로 모델 간의 독립성을 가진다.
- 단일 트리에 비해서 분산을 크게 줄이지 못한다.
random forest는 bagging과 동일하게 단순 다수결이나 평균으로 독립적으로 학습된 모델의 결과를 결합한다.
- 차이점은 랜덤화가 데이터 샘플링뿐만 아니라 특성(feature)의 샘플링에도 적용된다.
- 각 트리가 데이터를 학습할 때, 모든 특성을 사용하지 않고 랜덤하게 선택된 일부 특성만 사용하여 학습한다.
- 특정 특성에 지나치게 의존하는 트리를 방지하고, 모델 간의 상관성을 줄여 성능을 높인다.
- 예를 들어, 모든 트리가 "몸무게"라는 특성만 보고 학습한다면 비슷한 예측을 내릴 가능성이 높아진다. 특성을 랜덤하게 샘플링하면, "몸무게", "발 크기", "털의 색상" 등 다양한 특성을 기준으로 학습하므로 모델의 다양성이 증가한다.
결론적으로 두 방법 독립적인 트리들의 결과를 결합하는 앙상블 방법으로 bagging은 데이터 샘플링만으로 모델 간의 상관성을 낮추고, random forest는 데이터 샘플링에 특성 샘플링을 추가적으로 적용하여 모델 간의 상관성을 낮추고 다양성을 극대화한다.
5. Adaptive Boosting(AdaBoost)
기존의 bagging은 트리 여러개를 독립적으로 학습을 시켰다면, Adaptive Boosting는 여러 개의 모델을 순차적으로 학습시킨다.
첫 번째 모델을 학습해서 테스트할 때 잘못 분류하는 것에는 더 큰 가중치를 부여한다. 다음 학습에서 잘못 분류한 것들을 위주로 학습을 해서 반복을 통해서 점점 모델이 스스로 학습하도록 한다. 틀리는 것들을 기준으로 더 큰 가중치를 부여해 학습시켜 모델의 성능이 점점 좋아지는 것을 볼 수 있다.
bagging VS boosting
bagging은
- 여러 개의 모델을 평행하게 학습시킨다.
- 분산을 줄이는 효과가 있다.
- 분류의 경우 투표, 회귀의 경우 평균을 통해서 결과를 계산한다.
boosting은
- 여러 개의 모델을 순차적으로 학습시킨다.
- 분산이 줄어들면서 오차는 점점 개선되지만, overfitting 발생 위험이 있다.
- 다수결 투표나 평균을 구할 떄 가중치를 사용해서 진행한다.
6. 지도학습의 예
- Data: x입력과 이에 대응하는 정답y로 된 쌍이 데이터 형태로 존재
- Model: 어떤 모델 클래스 종류를 사용할 것인지 모델 정의
- Loss: 해당 모델 종류로 부터 나온 예측과 정답을 어떻게 비교할 것인지 손실 함수 정의
다음 3가지 프레임으로 정의할 수 있는 것을 지도학습이라고 한다.
super resolution
저해상도의 이미지를 고해상도의 이미지로 개선하는 문제이다.
- Data: 저해상도(입력x), 고해상도(출력y)
- Model: 딥러닝 CNN이나 vision transformer 부류의 모델
- Loss: Pixel-wise MSE나 PSNR
object dectection
박스를 이용해서 실제로 위치 정보까지 같이 제공하여 여러 객체가 존재하는 경우에도 탐지할 수 있는 문제이다.
- Data: 이미지(입력x), 위치 정보로 박스의 좌표 양 내 끝 좌표와 레이블(출력y)
- Model: 딥러닝 CNN이나 vision transformer 부류의 모델
- Loss: difference(box 좌표) + cross entropy loss(레이블)
BERT
transformer기반의 LLM의 시초로 일반적인 task를 할 수 있는 언어모델이다.
Task 1
어떤 문장에서 특정 문장에 특정 단어를 mask 처리를 처리해서 mask를 예측하는 문제이다. 문장을 tokenizer로 문장을 단어 별로 쪼개고 단어를 벡터화하여 데이터를 사용한다.
mask된 단어를 잘 표현했는지와 표현하지 못하는지로 classification loss류의 cross entropy loss를 사용할 수 있다.
- Data: mask된 문장(입력x), mask하기 이전의 원래 문장(출력y)
- Model: transformer LLM
- Loss: cross entropy loss
Task 2
두 개의 문장이 잘 연결되는 문장인지 예측하는 문제이다. 실제 두 문장이 연속된 문장이라면 yes 그렇지 않은 경우에 No로 판단한다. 굉장히 긴 문장이나 책에서 연속된 문장을 따오는 형태의 데이터를 사용한다.
- Data: 문장A와 문장B 쌍(입력x), 이진분류로 Yes or No(출력y)
- Model: transformer LLM
- Loss: cross entropy loss
Anomaly Detection
여러 개의 단계로부터 센서값 입력을 받아서 정상 상황인지 문제 발생 상황인지를 판단하는 문제이다.
- Data: 센서값(입력x), 이진분류로 정상 or 이상(출력y)
- Model: deep learning
- Loss: cross entropy loss
7. Semi-Supervised Learning
많은 데이터를 전부 label를 찾아주는 것은 시간적, 금전적으로 어렵기 때문제 준 지도학습을 사용한다.
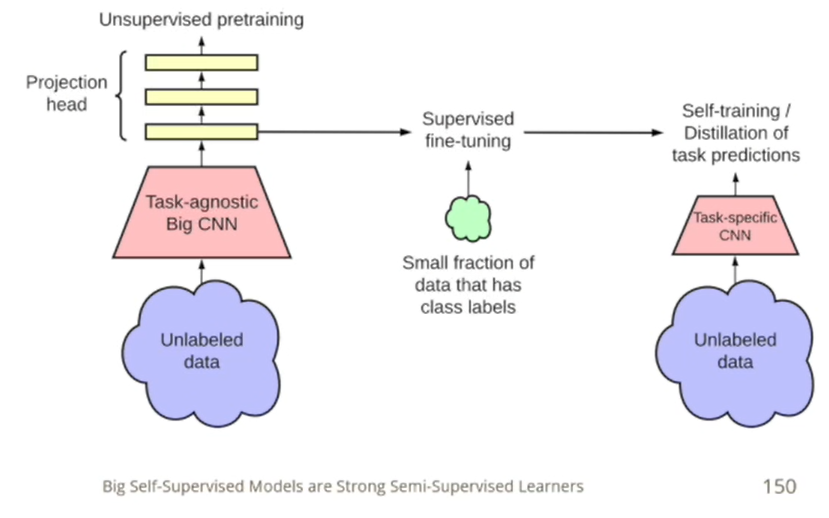
대부분은 데이터는 unlabel이고, loss값을 계산할 수 있는 label된 데이터가 많이 없는 경우이다.
Semi-Supervised Learning은 unlabel로 데이터로부터 이미지의 기본적인 특성을 배우고, 추출된 특성을 바탕으로 효율적으로 적은 label 데이터로 분류하는 기법을 배운다.
label이 없는 것에서 특성을 배울 수 있는 이유는 augmentaion 기법으로
이미지부터 특징을 추출하는 신경망을 사용한다. 이미지부터 특징을 추출하는 함수가 원본 이미지로 다양하게 증강된 이미지로부터 동일한 특징이 나와야 한다. 또는 두 개의 다른 이미지로부터 특징을 뽑으면 다른 값이 나와야 한다. 두 조건을 바탕으로 학습을 하게 되면 유의미한 특성을 배울 수 있다.
8. Generatived Models
생성형 모델은 대표적인 비지도학습으로 label이 주어지지 않는다. 데이터가 많이 주어져 있을 때 데이터의 분포를 파악하는 모델이다.
GAN
현재는 diffusion을 많이 사용하지만 과거 GAN이 많이 사용되었다.
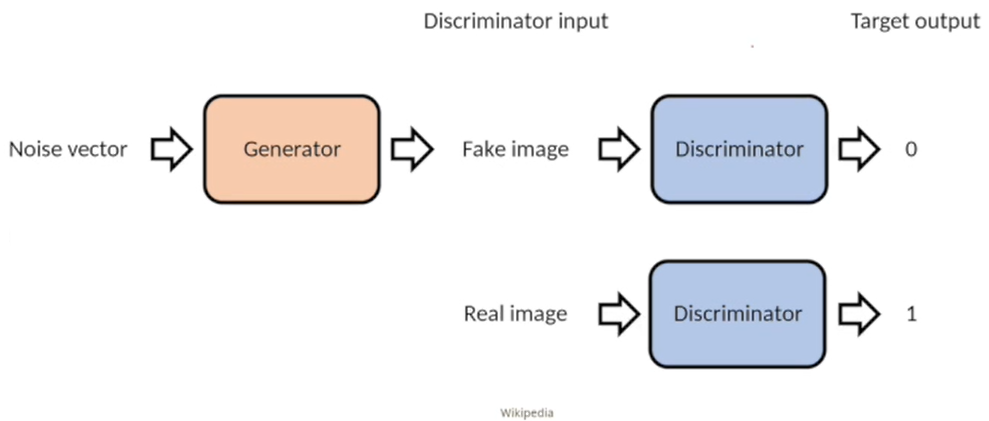
GAN은 이미지를 생성하는 Generator와 생성된 이미지가 가짜인지 진짜인지 판별하는 Discriminator 2개가 상호보완적으로 적용하여 반복적으로 학습하면서 Generator의 성능을 올린다.
실제로는 전체 과제는 데이터만 주어지고 label이 없는 비지도학습이지만 Discriminator 입장에서는 이 이미지가 생성된 가짜 이미지인지 실제 이미지인지에 따라서 label 0과 1이 주어져 있는 것을 학습하는 일종의 지도학습 과제를 전체 프레임에서 진행하고 있다.
9. Diffision Model
정교한 이미지를 생성하는 생성모델이다.

이미지에 노이즈를 추가하여 노이즈화 시키는 과정을 정방향 프로세스라고 부르고, 반대로 노이즈화된 것에서 노이즈를 제거하는 디노이징 과정을 거치는 역방향 프로세스가 존재한다.
실제 모델이 학습하는 것은 각 단계에서 노이즈를 하나 줄이면 무슨 일이 벌어지는가 어떻게하면 노이즈를 줄일 수 있는가를 학습한다.
이미지에 노이즈를 더하고 빼면 어떤 이미지가 나와야 하는지 알고 있다. 일종의 지도학습처럼 한 단계 디노이징하면 어떤 이미지가 나와야 되는지 모델을 학습시킬 수 있다.
