
저번 포스트에 이어서 Spring Reactive Web 의존성을 추가하여 단일 스레드 + 비동기/논블로킹 통신을 알아보자.
준비물
Dependencies
WebFlux를 사용하기 위해 필수 의존성을 추가한다.
- Spring Reactive Web
- 당연하게 있어야 할 의존성인 Spring Reactive Web을 추가한다.
- 물론, start.spring.io에서 추가하는 것이 더 편하다.
# build.gradle의 dependencies안에 추가
implementation 'org.springframework.boot:spring-boot-starter-webflux'- Spring Data R2DBC
- JPA와 비슷한 기능을 가진 R2DBC를 추가한다.
- R2DBC를 추가하는 이유는 JPA를 사용하면 데이터를 조회하거나 저장하는 등의 처리 과정에서 블로킹으로 처리하기 때문에 WebFlux를 사용하는 의미가 사라지기 때문이다.
- 단, R2DBC는 JPA처럼 연관 관계 매핑을 지원하지 않는다.
# build.gradle의 dependencies안에 추가
implementation 'org.springframework.boot:spring-boot-starter-data-r2dbc'- H2 Database, Lombok
- 내장 데이터베이스인 H2를 사용한다.
- Lombok을 통해 필요한 어노테이션을 사용한다.
왜 Spring Reactive Web인가
Spring Reactive Web은 Spring MVC에서 사용하는 Tomcat서버를 사용하지 않고 Netty서버를 사용한다.
Netty 는 비동기 이벤트 기반 네티워크 애플리케이션 프레임워크로, 1개의 이벤트에 대하여 다수의 Worker 스레드로 동작하게 된다.
반면, Tomcat은 블로킹/동기 방식을 사용한다.
Domain
Customer
WebFlux를 사용하기 위한 간단한 Customer객체를 하나 생성하자.
@RequiredArgsConstructor
@Data
public class Customer {
@Id
private Long id;
private final String firstName;
private final String lastName;
}그저, 이름을 받는 객체이다.
Repository
그리고, Customer를 CRUD하기 위한 저장소도 생성한다.
public interface CustomerRepository extends ReactiveCrudRepository<Customer, Long> { // 2)
@Query("SELECT * FROM customer WHERE last_name = :lastname") // 쿼리문
Flux<Customer> findByLastName(String lastName); // 1)
}1) JPA와 같이 find메서드와 save메서드 등을 제공한다.
- Flux라는 반환 타입을 갖는다.
- Flux : 0 ~ N개의 데이터 전달
- Mono : 0 ~ 1개의 데이터 전달
2) JPA와 다르게 ReactiveCrudRepository로 확장한다.
SQL
Customer를 저장하기 위한 테이블을 만든다.
DROP TABLE IF EXISTS CUSTOMER;
CREATE TABLE customer (
id SERIAL PRIMARY KEY,
first_name VARCHAR(255),
last_name VARCHAR(255)
);DataBase 초기 상태 지정
DataBase의 값을 조회하기 위해 초기 설정을 해준다.
@Slf4j
@Configuration
public class DBInit {
@Bean
ConnectionFactoryInitializer initializer(ConnectionFactory connectionFactory) { // 1)
ConnectionFactoryInitializer initializer = new ConnectionFactoryInitializer();
initializer.setConnectionFactory(connectionFactory);
initializer.setDatabasePopulator(new ResourceDatabasePopulator(new ClassPathResource("schema.sql")));
return initializer;
}
@Bean
public CommandLineRunner demo(CustomerRepository repository) { // 2)
return (args) -> {
// save a few customers
repository.saveAll(Arrays.asList(new Customer("Jack", "Bauer"),
new Customer("Chloe", "O'Brian"),
new Customer("Kim", "Bauer"),
new Customer("David", "Palmer"),
new Customer("Michelle", "Dessler")))
.blockLast(Duration.ofSeconds(10));
};
}
}프로젝트를 빌드할 때, 데이터베이스의 테이블을 생성하고 초기 값을 넣어주기 위해 initailizer메서드와 demo메서드를 Beam으로 등록한다.
WebFlux
Controller - 1
클라이언트로부터 요청을 받기 위해 Controller를 생성한다.
@RestController
public class CustomerController {
private final CustomerRepository customerRepository;
public CustomerController(CustomerRepository customerRepository) {
this.customerRepository = customerRepository;
}
@GetMapping("/customer")
public Flux<Customer> findAll() { // 1)
return customerRepository.findAll().delayElements(Duration.ofSeconds(1)).log();
}
}1) customerRepository에 있는 customer 정보를 전부 불러온다.
- 반환 하는 데이터의 개수 2개 이상의 데이터가 전달될 수 있으므로, Flux로 반환한다.
- 처리 속도가 매우 빠르기 때문에 눈으로 확인할 수 있게 1초 딜레이를 준다.
결과 화면
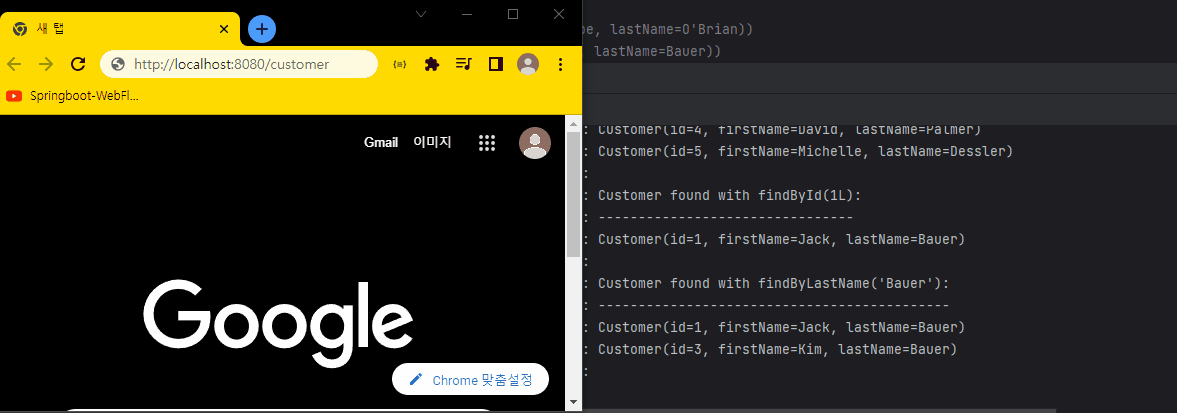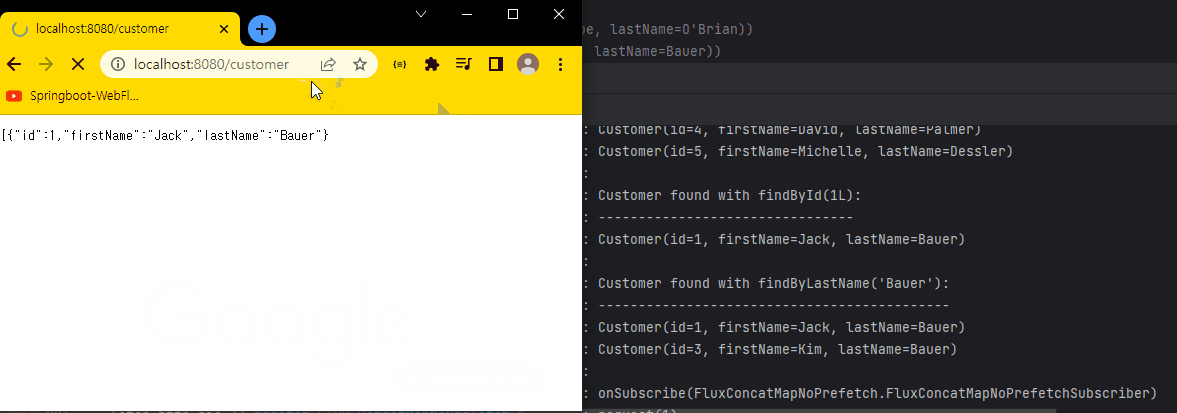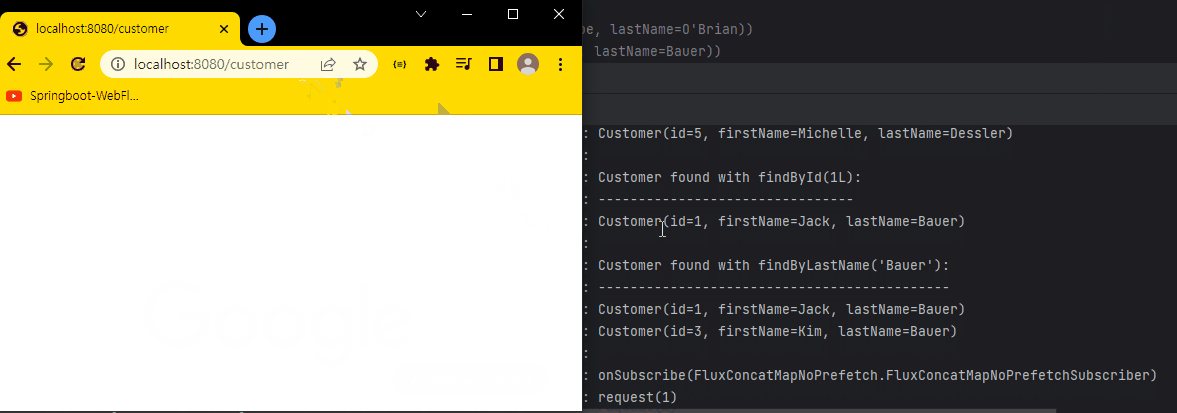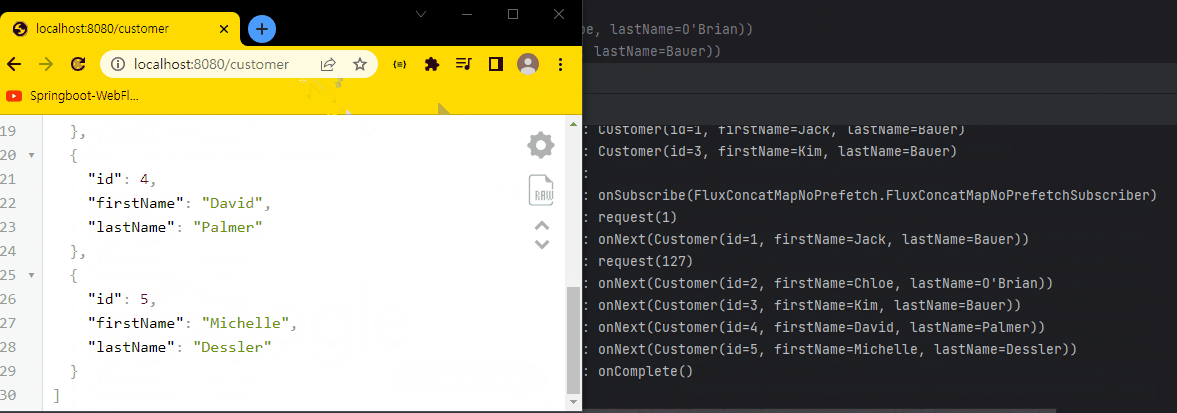
Spring MVC와 다른 점은, 만약 Spring MVC로 구현했다면 5명의 Customer 데이터를 한번에 가져온 다음 응답한다.
반면, Spring WebFlux는 onNext()를 통해 Customer 데이터를 1개 가져오면 가져온 값을 브라우저로 바로 전달한다.
마지막 onComplete() 메서드가 실행되면서 응답을 완료한다.
하지만, 실제 개발에서는 딜레이를 걸지 않기 때문에 위 코드만 보면 MVC와 별 차이가 없어 보인다. (실제론 단일 스레드로 처리하기 때문에 차이는 존재한다.)
이 차이를 명확하게 확인하기 위해, SSE 프로토콜과 함께 사용해보자.
SSE(Server-Sent-Events) 프로토콜
Client가 Server로부터 데이터를 받을 수만 있는 방식을 SSE라고 한다.
이번에 내가 구현할 것은 클라이언트의 POST요청을 통해 DB에 접근하면 이벤트가 발생하여 구독하고 있던 클라이언트에게 DB로 들어간 데이터를 보여주고자 한다.
SSE 프로토콜의 간단한 흐름은 아래 그림과 함께 설명하고, 자세한 내용은 다음 포스트에서 다뤄보겠다.
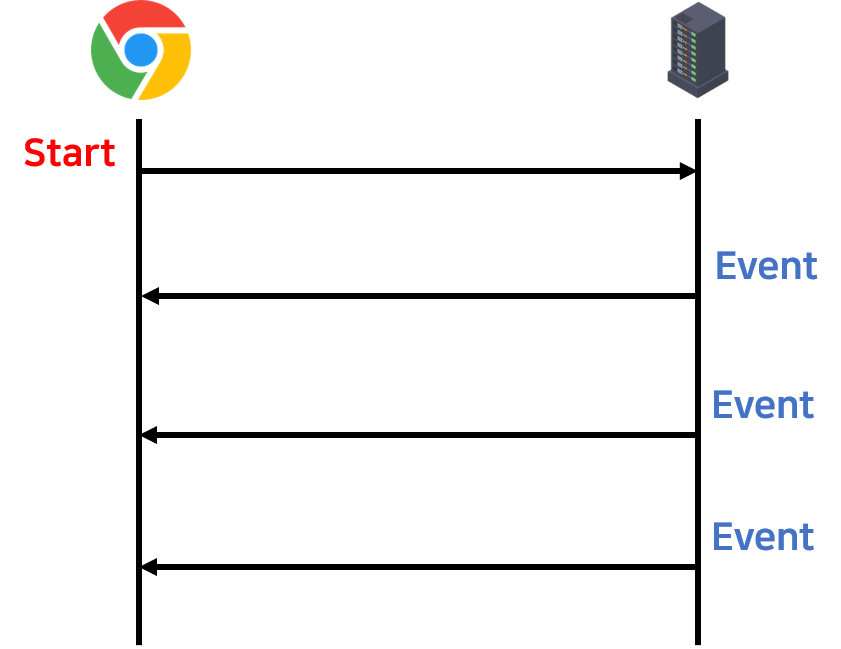
이처럼, 클라이언트가 서버로 요청을 보내고, 서버에서 작성한 로직이나 이벤트가 발생하면 데이터를 즉시 클라이언트로 전달하는 방식이다.
이제, 코드로 넘어가보자.
Controller - 2
간단한 시나리오는 다음과 같다.
- 사용자(클라이언트)가
/customer/sse를 구독(SSE 프로토콜로 통신하고 {클라이언트가 여러개일 경우}각 Stream을 sink*)한다.
Sink의 역할❗
두 개 이상의 Stream의 Sink를 맞춰주는 역할이다.
조금 더 쉽게 설명하면,
Client A와 Client B에서 각자 요청을 보내면 서버는 Flux A와 Flux B를 클라이언트에 맞게 응답한다.
즉, 서로 다른 Stream이 생긴다.
이때, Sink는 서로 다른 Stream을 연결하는 역할이다.
Event(Data)가 발생되면 Sink로 연결된 각 Stream으로 Event를 수신할 수 있다.
/customer/sse는 Customer가 새로 추가되면 이벤트를 발생하고, 이벤트가 발생하면 새로 추가된 Customer의 정보를 실시간 + 비동기적으로 제공한다.- Post방식
/customer로 요청하여 새로운 Customer 를 저장한다. - 이벤트가 발생하면서
/customer/sse를 구독하는 모든 사용자에게 새로 추가된 Customer의 정보를 제공한다.
@RestController
public class CustomerController {
private final CustomerRepository customerRepository;
private final Sinks.Many<Customer> sink; // 1) 추가
public CustomerController(CustomerRepository customerRepository) {
this.customerRepository = customerRepository;
this.sink = Sinks.many().multicast().onBackpressureBuffer(); // 2) 추가
}
```
중략
```
@GetMapping("/customer/sse")
public Flux<ServerSentEvent<Customer>> findAllSSE() { // 3)
// 4)
return sink.asFlux().map(customer -> ServerSentEvent.builder(customer).build()).doOnCancel(() -> sink.asFlux().blockLast());
}
@PostMapping("/customer")
public Mono<Customer> save() {
return customerRepository.save(new Customer("Hong", "gildong")).doOnNext(sink::tryEmitNext); // 5)
}
}1. private final Sinks.Many<Customer> sink;
Sinks.Many<Customer>라는 객체를 선언한다.
2. this.sink = Sinks.many().multicast().onBackpressureBuffer();
- 생성자에 -
Sinks.Many<Customer>객체의 생성 옵션과 함께 추가한다. - 옵션은
unicast(),multicast(),replay()가 있다.unicast(): 하나의 Subscriber 만 허용한다. 즉, 하나의 Client 만 연결할 수 있다.multicast(): 여러 Subscriber 를 허용한다.replay(): 여러 Subscriber 를 허용하되, 이전에 발행된 이벤트들을 기억해 추가로 연결되는 Subscriber 에게 전달한다.
onBackpressureBuffer(): publisher가 subcriber에 수용할 수 없는 양의 데이터를 전달하면 데이터를 Buffering 해서 저장.
3. Flux<ServerSentEvent<Customer>>
findAllSSE메서드는 비동기 스트림 형태로 Customer 객체들을 담는 Server-Sent Events를 반환한다.
4. findAllSSE() 메서드와 내부 로직
- sink.asFlux()를 사용하여
Sinks.Many<Customer>타입의 sink를Flux<Customer>타입으로 변환. - map 함수를 사용하여 각 Customer 객체를
ServerSentEvent<Customer>의 형식으로 변환(SSE 객체).- 변환된 SSE 객체들은 비동기적으로 전송.
doOnCancel(): 구독을 취소할 때 실행하는 함수sink.asFlux().blockLast(): 구독이 취소된 후, 현재 데이터 스트림을 종료
❗만약,sink.asFlux().blockLast()메서드를 사용하지 않고 클라이언트에서 종료하여 구독 취소 한다면? 👉 실질적으로 스트림이 종료되지 않아, 여전히 서버 측 리소스가 사용 중이거나 차단되어 있을 수 있어 새로운 요청이 제대로 처리되지 않는다.
5. save() 메서드
- firstName = Hong, lastName = gildong인 객체 저장 및 반환(Mono타입).
- 저장이 완료되면 doOnNext() 콜백 함수를 통해 다음 작업 수행.
- sink::tryEmitNext : sink에 새로 저장된 고객 데이터를 추가
- findAllSSE() 메서드에서 SSE 스트림을 구독 중인 클라이언트들이 새 추가된 고객 데이터를 실시간으로 받게 됨.
결과화면

글로 조금 설명을 덧붙여보자면,
처음에 /customer/sse 를 구독한 클라이언트는 하나였다.
그리고 Post방식으로 /customer를 통해 이벤트를 발생시키니 해당 데이터가 바로 구독한 클라이언트로 전송된다.
추가로, 새로운 클라이언트가 /customer/sse를 구독하고 다시 이벤트를 발생시키니 두 클라이언트 모두에게 데이터가 전달되는 것을 알 수 있다.
마치며
WebFlux를 공부하기 위해 뛰어들었지만, 내가 습득하지 못한 여러 개념들이 바탕되었기 때문에 어렵게 공부했다는 느낌이 들었다.
모르거나 아리송한 개념이 있으면 이해할 때까지 찾아보는 습관 덕분인지 이해는 할 수 있었다.
하지만 WebFlux에 대해 완벽한 수준은 아니라서 누군가 이 포스트르 본다면 틀린 부분이 산더미처럼 보일지도 모른다.
피드백은 언제나 환영이기 때문에, 지나가던 고수님들께서 이 글을 보신다면 꼭 피드백을 받고 싶다.
백엔드 개발을 하면서 동기/블로킹 방식의 개발을 자주 했다.
어쩌면, 웬만한 프로젝트는 동기/블로킹으로 개발했던 것 같다.
개발을 하면서도 대규모 트레픽에서 약한 모습을 종종 봐왔기 때문에 WebFlux의 비동기/논블로킹 방식이 필요하다고 생각했다.
물론, 상황마다 WebFlux와 MVC를 다뤄야할 것이다.
그렇기에, WebFlux의 중요성을 다시 한 번 알게 되었고, 두가지 모두 능숙하게 다룰 수 있는 개발자가 되는 날까지 WebFlux에 가까워 지려고 한다.
References
YouTube : Springboot-WebFlux
알림 기능을 구현해보자 - SSE(Server-Sent-Events)!
Accessing data with R2DBC
