-
Perplexity (PPL)
모델의 헷갈림 점수이다. confidence의 역수라고 생각하면 될것같다. PPL이 높으면, 엄청 헷갈리는거, 낮으면 안헷갈리는거! 정답으로 고민하고 있는 후보의 수? 라고 생각하면 됨. 그래서 PPL은 최소가 1이고, 최대는 무한대이다. -
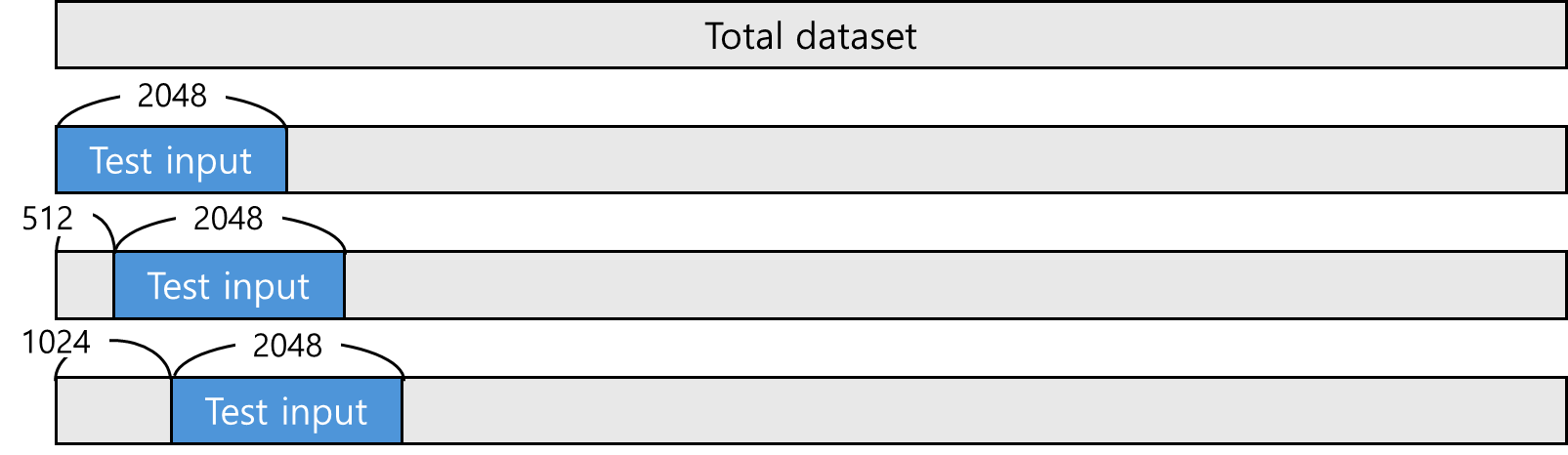
Sliding Window
PPL을 측정하기 위해서 사용되는 표준 방식이다. 각 추론에 사용되는 input token은 2048이고, sliding token은 512이다.
예를 들어서, wikitext 데이터는 쭉 긴 글이다. 그래서 추론하려면 적당한 선에서 자르는게 중요하다. 그냥 자르면 앞의 문맥을 알지 못해서 아무리 성능이 좋은 모델이라도 이상하게 추론 되는 경가 나온다. (=Context Fragmentation) 이를 방지하기 위해서 Sliding Window를 사용하는 것이다.
근데, test할때 모델이 text를 생성하면 어떻게 gt 데이터랑 채점하는건가 했더니, 2048을 input으로 하는게 아니라, 2048에서 3/4부터 +1토큰씩예측해서 총 512개의 예측값을 가지고 측정하는거라고 한다. 아래 그림을 보면 이해가 될거임.. (빨간색은 1토큰이야!)
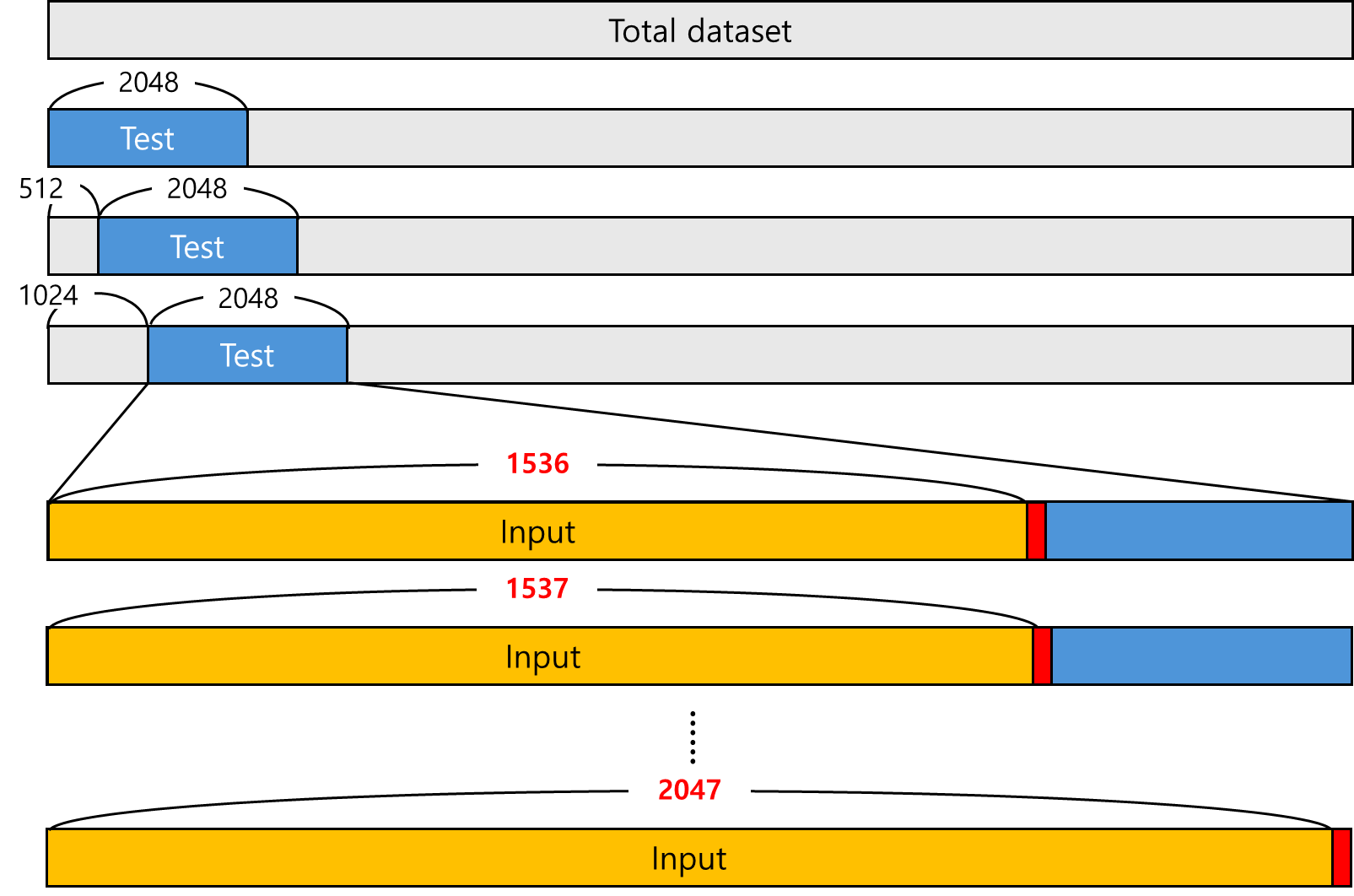
-
PPL 측정
- wikitext-2 데이터셋을 다운 (wikitext-2-raw-v1)
import torch from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig from datasets import load_dataset from tqdm import tqdm # 모델 id 설정 model_id = "beomi/Llama-3-Open-Ko-8B" # 한국어 Llama-3 # model_id = "meta-llama/Meta-Llama-3-8B" def main(): device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Using Device: {device}") tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype = torch.float16, device_map = "auto" ) print(f"Complete Load Model: {tokenizer}") test_set = load_dataset("wikitext", "wikitext-2-raw-v1", split="test") encodings = tokenizer("\n\n".join(test_set["text"]), return_tensors="pt") window_length = model.config.max_position_embeddings stride = 512 seq_len = encodings.input_ids.size(1) print(f"\ntest set seq_len: {seq_len} token") print(f"Window Size: {window_length}") print(f"Stride: {stride}") print(f"Complete Load Dataset") nlls = [] # 오차값 담는 리스트 prev_end_loc = 0 print(f"\nMeasurement Started (PPL)...") for begin_loc in tqdm(range(0, seq_len, stride)): end_loc = min(begin_loc + window_length, seq_len) trg_len = end_loc - prev_end_loc input_ids = encodings.input_ids[:,begin_loc:end_loc].to(device) target_ids = input_ids.clone() target_ids[:, :-trg_len] = -100 # 이해 안됨! with torch.no_grad(): outputs = model(input_ids, labels=target_ids) # model에서 loss를 계산해주나보네?? neg_log_likelihood = outputs.loss * trg_len nlls.append(neg_log_likelihood) prev_end_loc = end_loc if end_loc == seq_len: break ppl = torch.exp(torch.stack(nlls).sum() / end_loc) print(f"\n========================================") print(f" 최종 PPL Result: {ppl.item():.2f}") print(f"========================================") if __name__ == "__main__": main()

안녕하세요.