-
원본 모델 PPL 측정
모델 로드 시, torch_dtype = torch.float16으로 설정함.model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype = torch.float16, device_map = "auto" ) -
실험 결과
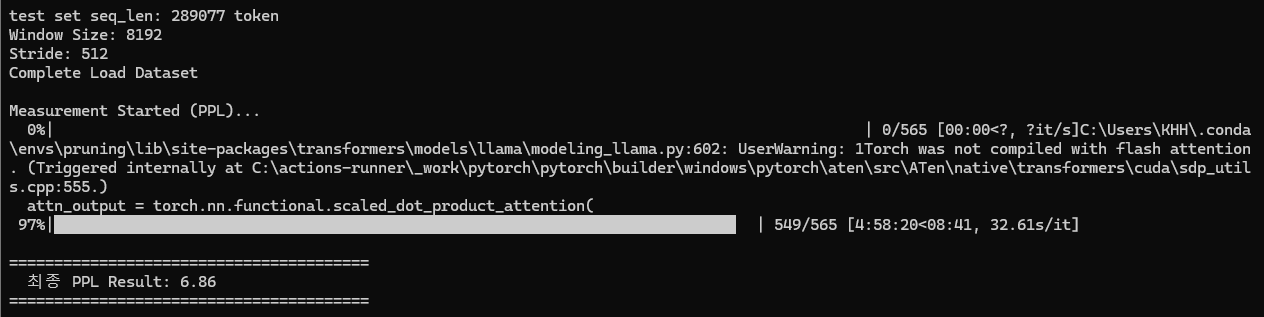
beomi/Llama-3-Open-Ko-8B 모델로 테스트 한 결과이고 PPL이 6.86이였다. (보통 10PPL이하면, 좋은 모델이라고 한다.) 이 값을 기준으로 경량화를 했을때, 속도/성능이 얼마나 변화되는지 확인해보자.- 시간이 5시간이나 걸린 이유
- window size를 모델 설정 사이즈를 그대로 사용했더니 8192로 되어서, 2048보다 계산량이 16배가 늘어나게 되었다.
- Flash Attention을 사용을 안했다고 나옴.
- 모델 추론 중 nvidia-smi
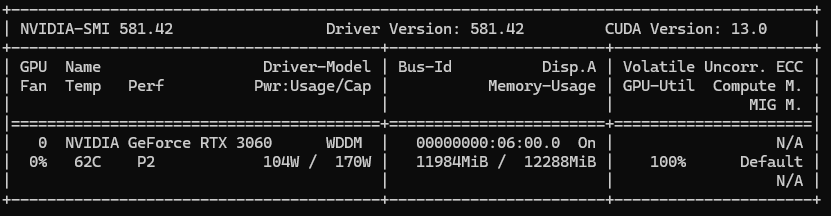
- 시간이 5시간이나 걸린 이유

안녕하세요.