spark streaming이란?
- SQL엔진 위에 만들어진 분산 스트림 처리 프로세싱
- 데이터 스트림을 처리할때 사용
- 시간대 별로 데이터를 합처(aggregate) 분석할 수 있음
- Kafka, Amazon Kinesis, HDFS 등과 연결 가능
- 체크포인트를 만들어서 부분적인 결함이 발생해도 다시 돌아가서 데이터 처리 가능
Discretized Streams (DStreams)
Spark Streaming은 Spark RDD를 기반으로 Micro-batch를 수행한다.
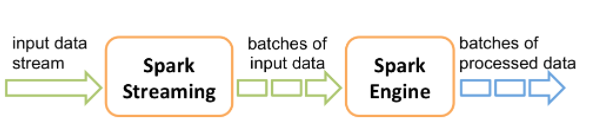
그림처럼 실시간으로 input data stream을 받아서 DStream(discretized stream)의 작은 배치 단위로 나눠 Spark Engine으로 보낸다. Spark engine에서는 가공한 데이터를 반환한다.

DStream은 이산화된 데이터로, 시간별로 도착한 데이터들의 RDD 집합이다.
Window Operations
- 지금의 데이터를 처리하기 위해 이전 데이터에 대한 정보가 필요할 때
State 관리
- 이전 데이터에 대한 정보를 State로 주고받을 수 있다.
ex)카테고리별 총합 구할 때
1번째 데이터 - 1번째 데이터 합
2번째 데이터 - 1,2번째 데이터 합
3번째 데이터 - 1,2,3번째 데이터 합...
실습
소켓으로 부터 스트리밍을 받아 사용자 입력한 단어 카운트를 console로 뿌리는 예제
streaming.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
#스파크 인스턴스 생성
spark = SparkSession.builder.appName("stream-word-count").getOrCreate()
# readStream 포멧 설정 (socket) / 호스트설정(localhost) / 포트설정 ( 9999)
lines_df = spark.readStream.format("socket").option("host", "localhost").option("port", "9999").load()
# lines_df 데이터 프레임을 words_df 데이터 프레임으로 변환
words_df = lines_df.select(expr("explode(split(value, ' ')) as word"))
# 공백 단위로 잘린 word 기준으로 카운트
counts_df = words_df.groupBy("word").count()
# read -> write
word_count_query = counts_df.writeStream.format("console")\
.outputMode("complete")\
.option("checkpointLocation", ".checkpoint")\
.start()
word_count_query.awaitTermination()1. 소켓 오픈
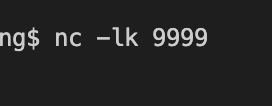
nc -lk 9999 명령어로 local의 9999포트 오픈
2. streaming.py spark-submit
위 streaming.py를 제출하게되면 아래와 같은 그림 출력

이제 스트리밍을 보내면 word, count가 증가하게 된다.

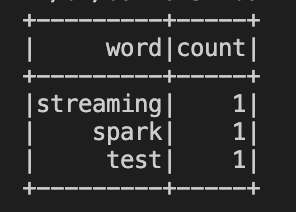
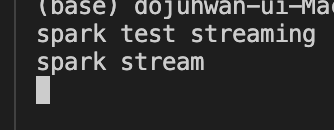
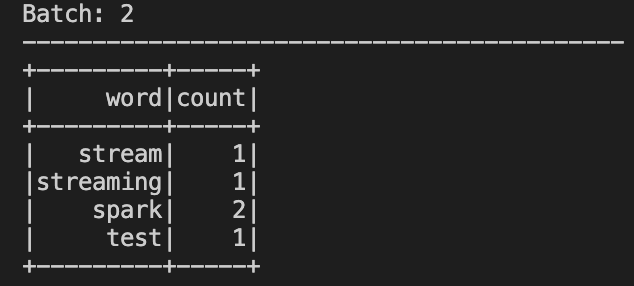
현재 주고받은 데이터는 streaming.py에서 설정한 .checkpoint 디렉토리에 저장되며
소켓이 끊겨도 재연결 시 체크포인트가 저장되어 있어 기존의 데이터를 불러올 수 있다.
참조

반갑습니다.