spark란?
아파치 스파크(apache spark)는 2011년 버클리 대학의 AMPLab에서 개발되어 현재는 아파치 재단의 오픈소스로 관리되고 있는 인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크입니다.
스파크의 특징
- Speed
- 인메모리(In-memory) 기반의 빠른 처리 - Ease of Use
- 다양한 언어 지원(Java, Scala, Python, R, SQL)을 통한 사용의 편의성 - Generality
- SQL, Streaming, 머신러닝, 그래프 연산 등 다양한 컴포넌트 제공 - Run Everywhere
- YARN, Mesos, Kubernetes 등 다양한 클러스터에서 동작 가능
- HDFS, Casandra, HBase 등 다양한 파일 포맷 지원
인메모리 기반의 빠른 처리
스파크는 인메모리 기반의 처리로 맵리듀스 작업처리에 비해 디스크는 10배, 메모리 작업은 100배 빠른 속도1를 가지고 있습니다. 맵리듀스는 작업의 중간 결과를 디스크에 쓰기 때문에 IO로 인하여 작업 속도에 제약이 생깁니다. 스파크는 메모리에 중간 결과를 메모리에 저장하여 반복 작업의 처리 효율이 높습니다.
다양한 컴포넌트 제공
스파크는 단일 시스템 내에서 스파크 스트리밍을 이용한 스트림 처리, 스파크 SQL을 이용한 SQL 처리, MLib 를 이용한 머신러닝 처리, GraphX를 이용한 그래프 프로세싱을 지원합니다. 추가적인 소프트웨어의 설치 없이도 다양한 애플리케이션을 구현할 수 있고, 각 컴포넌트간의 연계를 이용한 애플리케이션의 생성도 쉽게 구현할 수 있습니다.
다양한 언어 지원
스파크는 자바, 스칼라, 파이썬, R 인터페이스등 다양한 언어를 지원하여 개발자에게 작업의 편의성을 제공합니다. 하지만 언어마다 처리하는 속도2가 다릅니다. 따라서 성능을 위해서는 Scala 로 개발을 진행하는 것이 좋습니다.
다양한 클러스터 매니저 지원
클러스터 매니저로 YARN, Mesos, Kubernetes, standalone 등 다양한 포맷을 지원하여 운영 시스템 선택에 다양성을 제공합니다. 또한, HDFS, 카산드라, HBase, S3 등의 다양한 데이터 포맷을 지원하여 여러 시스템에 적용이 가능합니다.
다양한 파일 포맷 지원 및 Hbase, Hive 등과 연동 가능
스파크는 기본적으로 TXT, Json, ORC, Parquet 등의 파일 포맷을 지원합니다. S3, HDFS 등의 파일 시스템과 연동도 가능하고, HBase, Hive 와도 간단하게 연동할 수 있습니다.
스파크의 컴포넌트 구성
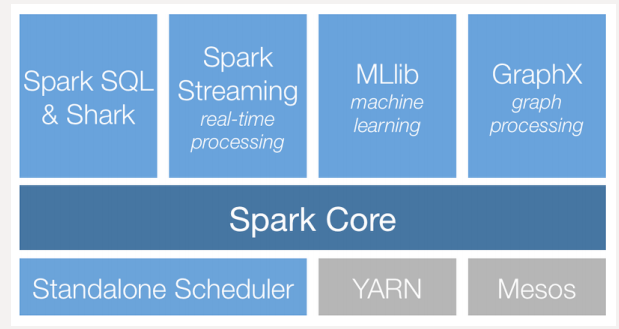
-
Spark Core
스케줄링, 메모리 관리, 장애 복구와 같은 기본적인 기능과 RDD, DataFrame, DataSet을 이용한 스파크 연산 처리를 담당합니다.
-
Spark SQL
RDD, DataSet, DataFrame 작업을 생성하고 처리하며, 하이브 메타스토어와 연결하여 하이브의 메타 정보를 이용하여 SQL 작업을 처리할 수 있습니다.
-
Spark Streaming
실시간 데이터 스트림을 처리하는 컴포넌트입니다.
-
MLlib
분류(classification), 회귀(regression), 클러스터링(clustering), 협업 필터링(collaborative filtering) 및 모델 평가 등이 가능한 머신 러닝 라이브러리 입니다.
- GraphX
페이지 랭크와 같은 분산형 그래프 프로세싱을 지원하는 컴포넌트입니다.
스파크의 기본 구조
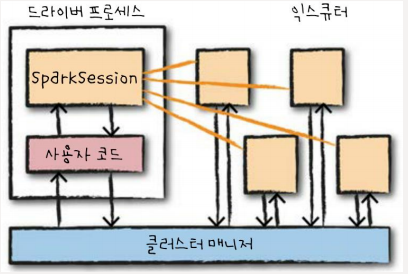
스파크 애플리케이션은 마스터-슬레이브 구조로 실행됩니다. 사용자가 클러스터 매니저에 스파크 애플리케이션을 제출하고, 클러스터 매니저로부터 받은 자원을 이용하여 작업을 처리합니다. 이때, 드라이버와 익스큐터는 단순한 프로세스이므로 같은 머신 또는 다른 머신에서 실행이 가능합니다.
- 드라이버 프로세스 : Master
스파크 응용을 위한 SparkSession을 관리하는 JVM 프로세스로 DAG(Directed Acyclic Graph) 기반 태스크 스케줄링을 수행합니다. 사용자 프로그램을 태스크라고 불리는 실제 수행 단위로 변환하고, 익스큐터 프로세스의 작업과 관련된 분석 및 관리를 담당합니다.
- 익스큐터(executor) : Slave
마스터인 드라이버 프로세스가 할당한 작업을 수행 및 결과를 반환하며, YARN의 컨테이너와 유사합니다.
스파크 API
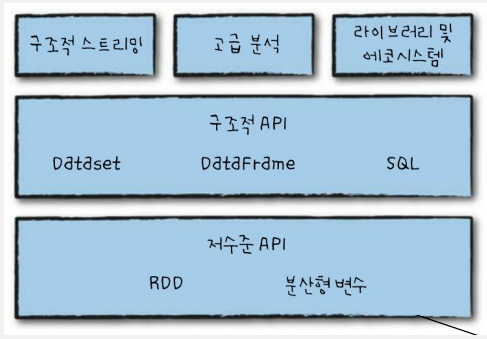
스파크 API는 데이터를 다루기 위한 저수준의 비 구조적 API인 RDD와 최적화를 자동으로 수행하는 고수준의 구조적 API로 나눌 수 있습니다.
- 데이터 모델 API
RDD
인메모리 데이터 처리를 통하여 처리속도를 높인 데이터 모델입니다. 최적화가 어렵고, 데이터의 형태(스키마)를 표현할 수 없습니다.
DataFrame(Spark 1.3에서 추가)
데이터를 스키마 형태로 추상화 하여 테이블처럼 다룰 수 있으며, 카탈리스트 옵티마이저가 쿼리를 효율화 하여 처리합니다. 파이썬 pandas의 dataframe이나 매트랩의 배열과 유사합니다.
DataSet(Spark 1.6에서 추가)
스파크 2.0부터 스파크 SQL의 메인 API로 지정되었으며, 데이터의 타입체크, 데이터 직렬화를 위한 인코더, 카탈리스트 옵티마이저를 지원하여 데이터 처리 속도를 더욱 증가시켰습니다.
참고
