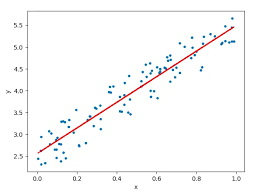
- hypothesis
Cost(Loss) function
- 세운 가설값과 실제값과 얼마의 차이가 존재하는지
- how fit the line to training data
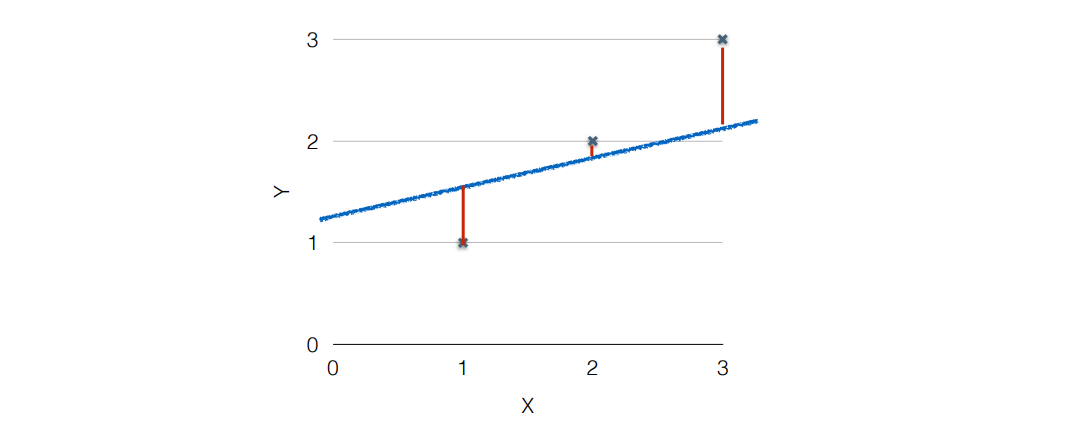
- cost function
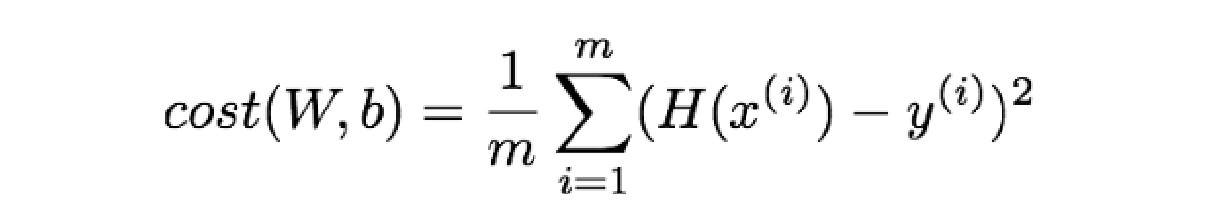
- 제곱으로 나타내는 것은 위의 그림과 같이 에서 음수로 차이가 나는 것을 다른 것들과 동일하게 차이를 양수로 나타낼 수 있다
Gradient descent algorithm
-
cost function 최소화
-
cost (W, b)의 cost function에서 cost를 최소화할 W, b 찾음
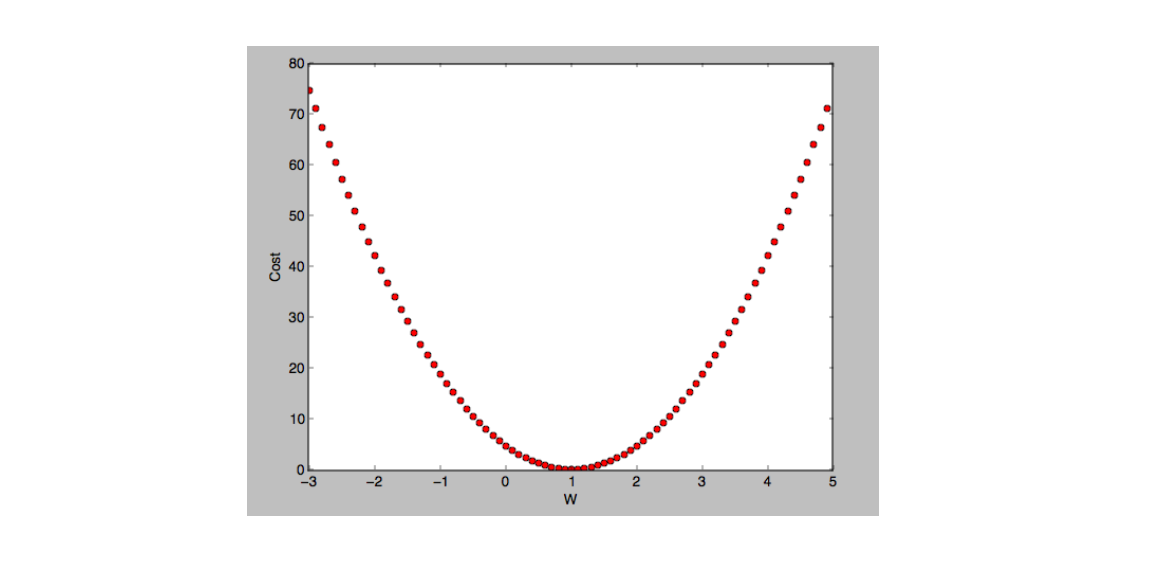
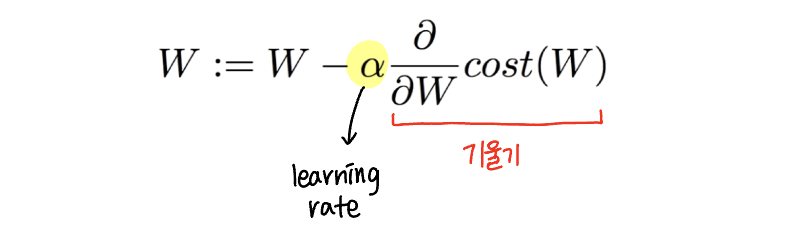
-
start w/ initial guesses
- 임의의 (a, b)에서 시작
- cost(W, b) 시도하고 줄이기 위해 W, b 계속해서 변경 -
parameter를 바꿀 때마다 cost(W, b)를 최대한 줄일 경사를 선택
-
위 과정 반복
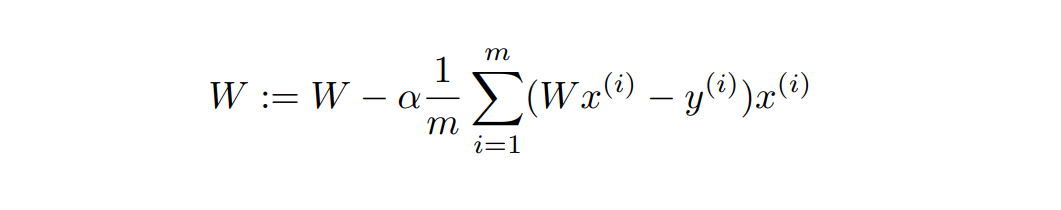
Multi-variable Linear Regression
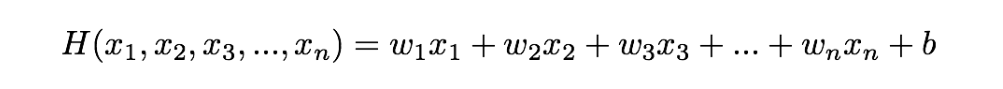
- 무수히 많아지면
-> matrix multiplication
Hypothesis using matrix
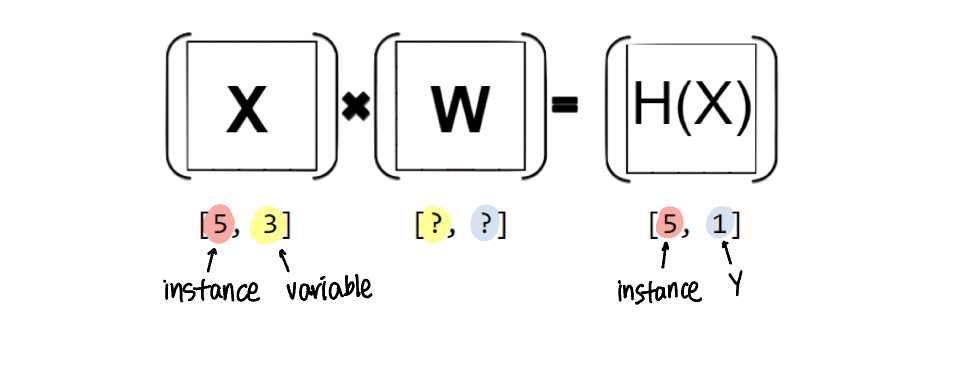
기존의 hypothesis 와 matrix hypothesis에서
matrix hypothesis 는 TensorFlow에서 쓰일 수 있다
