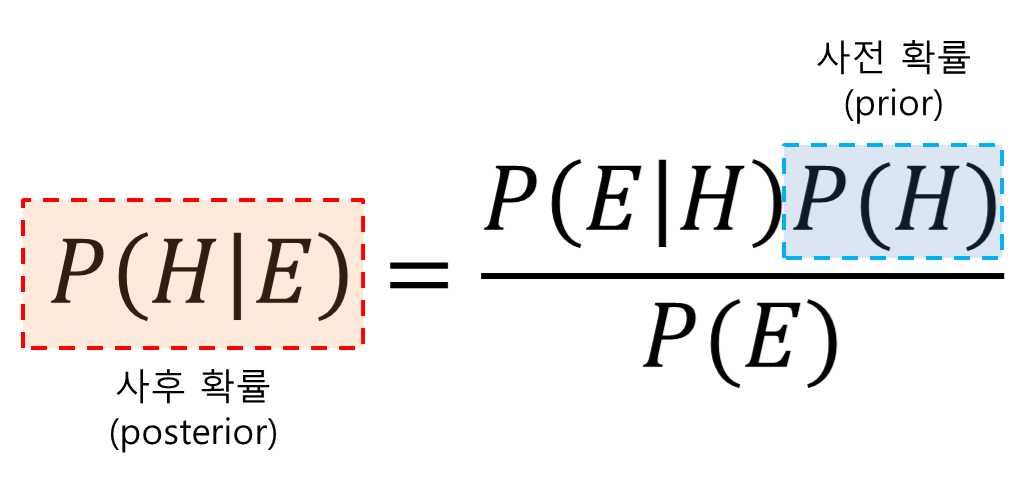
이골이 나는 베이즈 정리
📘 참고서적
- 딥러닝을 위한 수학 - 신경망 수학기초부터 역전파와 경사하강법까지
베이즈 정리
딥러닝 공부를 하면서 정말 귀에 못이 박히도록 들은 정리 == 베이즈 정리
내가 베이즈 정리를 공부하면서 가장 헷갈렸던 건, 바로 고등학교 시절에 배웠던 '조건부 확률' 때문이었다. 두 정리는 식도 비슷하게 생겼고, 나름 관계가 밀접하기 때문에 더욱 헷갈렸던 거 같다. 그래서 베이즈 정리에 대해 설명하기에 앞서, 내가 헷갈렸던 '베이즈 정리'와 '조건부 확률'의 차이점, 그리고 관계성에 대해 설명하도록 하겠다.
베이즈 정리와 조건부 확률
내가 이해한 바로, 조건부 확률의 또 다른 형태의 계산법이 '베이즈 정리'이다.
조건부 확률은 P(AㅣB)를 해석할 때, 사건 B가 일어났다는 전제 하에 사건 A가 일어날 확률을 의미한다.
하지만, 베이즈 정리는 위의 내용을 더 확장하여 B에 대한 정보를 바탕으로 P(B)와 P(AㅣB)를 알고 있다면, 이를 활용해 P(BㅣA)를 추론할 수 있게 하는 것이다. 즉, 새로운 증거 P(A)에 기반하여 어떤 사건이 발생했다는 주장에 대한 신뢰도를 갱신해 나가는 방법으로 이해할 수 있다. (새로운 정보가 기존의 추론에 어떻게 영향을 미치는가를 나타내는 것이다.)
그렇기 때문에 베이즈 정리는 조건부 확률과 계산법이 다르다. 이를 이해하기 위해서는 '사후확률(posterior probability)', '사전확률(prior probability)'을 이해해야 한다.
사전확률, 사후확률
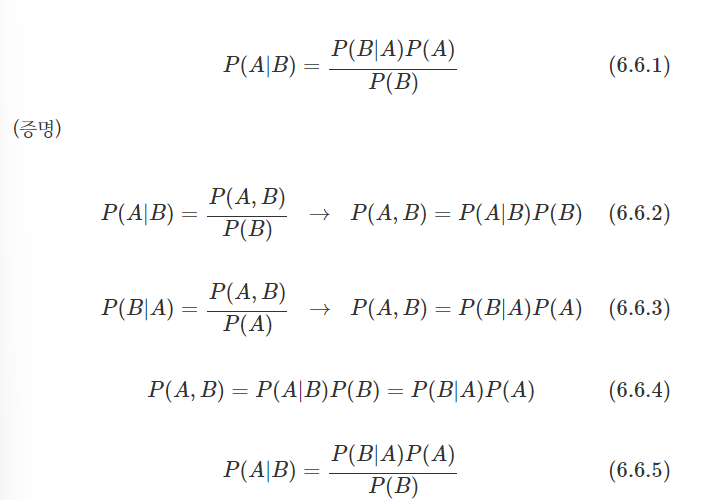
- 사전확률(prior) = P(A)
- 사후확률(posterior) = P(AㅣB)
- 가능도(likelihood) = P(BㅣA)
- 증거(evidence) = P(B)
하나씩 알아가보자.
사전확률(prior)
사전확률은, 쉽게 말하자면 '이미 알고 있는 내용'이다. ('사전에 준비한 내용입니다.'와 같은 의미로 '사전'을 이해하면 편하다.)
예를 들어, 우리는 이미 가지고 있는 지식을 통해 동전을 던져 앞면이 나올 확률을 1/2 라고 부여했다. 이를 사전확률이라고 하는 것이다.
사후확률(posterior)
사후확률은, 쉽게 말하자면 '수정된 확률'이라고 볼 수 있다.
위의 사진을 예시로 들자면, B라는 사건이 발생한 후에 갱신된 사건 A의 확률을 의미하는 것이다.
결국, 베이즈 정리는 사후확률을 계산하는 것과 마찬가지이다.
가능도(likelihood)
어떤 특정한 값을 관측할 때, 이 관측지가 어떠한 확률분포에서 나왔는가?에 대한 값으로, 확률의 확률이라고 볼 수 있다.
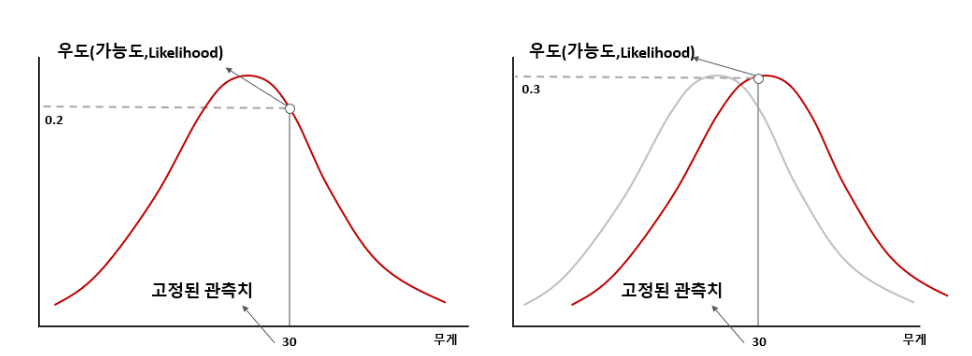
위의 그림으로 쉽게 말하자면, 확률밀도함수가 나타내는 그래프의 y값으로 볼 수 있다.
이렇게 되면 대체 '확률'은 무엇이냐고 물을 수 있는데, 확률과 가능도 간의 차이는 무엇을 고정했는가 차이이다.
가능도는 고정된 관측값이 어떠한 확률분포에서 어느 정도의 확률로 나타나는지에 대한 확률이지만, 확률은 고정된 확률분포에서 어떠한 관측값이 나타나는지에 대한 확률이다.
그렇기 때문에, 가능도는 이미 시행된 결과를 확인하는 것이다.
(확률은 시행하기 전에 예측하는 것이다.)
해당 내용을 잘 정리해둔 블로그 링크를 첨부하겠다. (https://dlearner.tistory.com/43)
증거(evidence)
또 다른 명칭으로는 정규화 상수(Normalizing constant)라고 부르기도 한다. 이는 위의 사진으로 이야기하자면, P(B)(사건 B의 확률)이다.
그렇다면 또 질문이 생긴다. 과연 정규화는 무엇이고, 정규화를 하는 이유는 또 뭘까?
-
정규화(Normalization)
: 데이터의 단위를 모두 0~1 사이로 옮겨지게 해준다. -
정규화를 하는 이유?
: 정규화를 하는 이유는 너무 많은 데이터의 단위가 존재하는데, 이를 하나하나 다 따지게 되면 데이터 분석을 할 수 없는 상황에 봉착하게 된다. 그렇기 때문에 데이터들의 단위를 무시할 수 있도록, 또 그 데이터들의 값 범위를 비슷하게 만들어야 한다. 결국, 양질의 데이터 분석을 위해선 정규화 과정이 필요한 것이다. -
정규화를 배우다 보면 꼭 나오는 표준화(Standardizaiton)
: 표준화는 이미 '정규분포'를 따른다는 가정 하에서 데이터의 평균을 0, 표준편차를 1이 되도록 한다. (이를 정규분포의 표준화라고 부른다.)
해당 내용을 잘 정리해둔 블로그 링크를 첨부하겠다.
(https://bskyvision.com/849)
증거가 필요한 이유는, 사후확률을 구할 때 가능도와 사전확률의 곱의 결과를 1로 만들어 주기(정규화 해주면서) 때문이다. 또, 증거는 사건 A에 종속적이지 않다.
베이즈 정리를 활용한 단순 베이즈 분류자(Naive Bayes Classifier)
사실 Navie Bayes를 보는 순간 너무나도 반가웠다. 저번에 읽었던 논문에서 나왔던 내용이기 때문이다! 그 때는 단순히 Classification의 과정을 알아보면서, 이 과정으로 Naive Bayes Classifier이 작동한다고만 썼는데, 이번에는 최대한 이해하려고 노력했다.
Class Label(y)들과 Feature Vector(x)들로 이루어진 데이터 집합이 있다고 가정하자.
단순 베이즈 분류자의 목표는, 각 Class Label에 대해, 주어진 한 Feature Vector가 그 Class Label에 속할 확률을 구하는 것이다.
정리하면 아래와 같다.
주어진 한 x가 y에 속할 확률을 구하는 것
== 어떤 한 x가 주어졌을 때 확률이 가장 큰 y를 그 x에 부여
== y에 대한 P(yㅣx)
== P(yㅣx)의 베이즈 확률
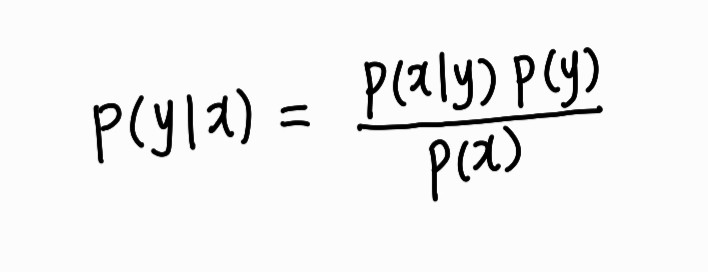
이와 같은 식으로 표현할 수 있다.
위 식은, 특징 벡터 x가 분류명 y의 한 인스턴스를 대표할 확률(==P(yㅣx))은 분류명 y가 특징 벡터 x를 산출할 확률(==P(xㅣy))에 분류명 y가 발생할 사전확률(==P(y))을 곱하고 모든 분류명에 대한 특징 벡터의 주변확률(==P(x))로 나눈 것이라는 뜻이다.
임의의 특징 벡터가 주어졌을 때, 그 특징 벡터가 속할 확률이 가장 높은 분류명이 곧 그 특징 벡터의 분류 결과이다. (우리가 구하고자 하는 것도 이것이다.)
그렇기 때문에 우리는 P(yㅣx)들의 상대적인 대소관계만 알아가면 된다. (그 중에서 가장 확률이 높은 분류명만 고르면 되기 때문이다.)
P(x)는 모든 y에 대해 동일하다. (상수로써 작용) 그렇기 때문에 우리가 구해야하는 건 결국 P(xㅣy)밖에 없는 것이다. (P(y) 값들은 데이터 집합에서 추정이 쉽게 가능하다.)
결국, 우리는 분류명에 따라 특징 벡터가 발생할 가능도를 구하면 된다.
그렇다면, 과연 P(xㅣy)는 어떻게 구해야 할까?
P(xㅣy)는, 특징 벡터들이 모두 분류명 y를 대표한다고 할 때 특징 벡터들의 확률이다. x들이 모두 분류명 y에서 온 것임을 알고 있으므로, y는 고정이 된다. 그래서 결론적으로는 P(x)만 남게 된다.
x는 개별 특징들의 벡터이다. 특징을 n개라고 할 때, x = (x0, x_1, ..., x(n-1)) 이런 식으로 표현이 가능하다. 그러므로 P(x)는 모든 개별 특징이 각자 특정한 값들을 동시에 가질 결합 확률에 해당한다. 그리고 특징 벡터의 모든 특징은 서로 독립적이다. (x_1의 값이 벡터의 다른 특징의 값에 아무런 영향도 받지 않는다.)
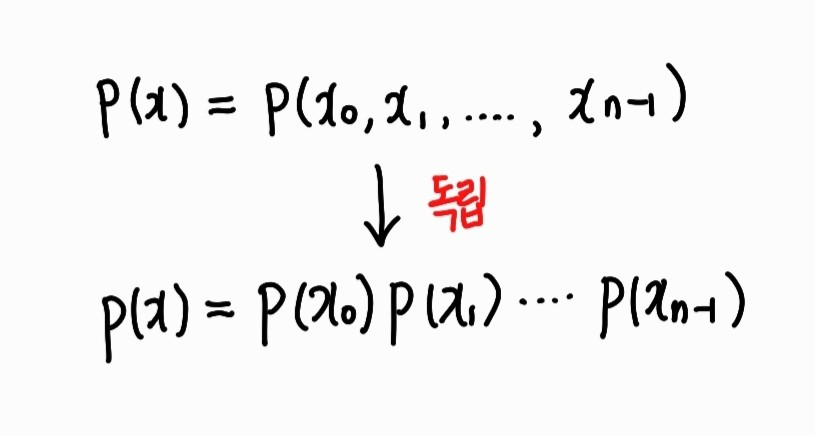
그렇게 되면 위와 같이 식이 매우 간단해진다. 우리는 결국, 각 분류명에 각 특징이 몇 번이나 출현하는지에 대해서 구하면 되는 것이다.
휴 너무 어려웠다. 다음은 통계의 기초 지식으로 돌아오겠다!
