실습
- 문제정의

- 문제정의
- 데이터 수집
from sklearn.datasets import fetch_openml
boston = fetch_openml('boston')
# 분홍색 경고창 = 버전에 따라 다른 코드, 필수 파라미터 누락
boston.keys()
import pandas as pd
X = pd.DataFrame(boston['data'], columns=boston['feature_names'])
y = pd.DataFrame(boston['target'])-데이터 확인하기
X.info()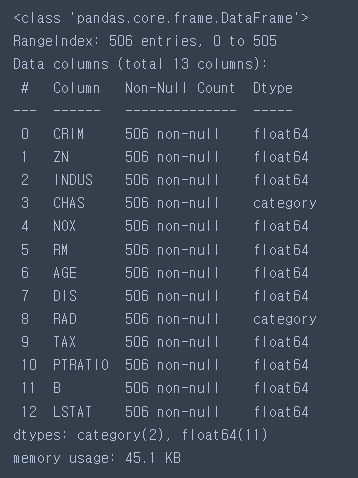
-category → int로 변경
X[['CHAS', 'RAD']] = X[['CHAS', 'RAD']].astype(int)X['RAD'].value_counts()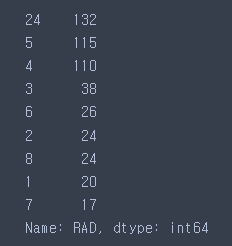
-확인하기
X.info()- 데이터 전처리
from sklearn.preprocessing import StandardScaler
# 스케일러 가져오기
sds = StandardScaler()
# 스케일러에게 학습시키기(변환 할 범위 정하기)
sds.fit(X)
# 변환
X_sds = sds.transform(X)- 탐색적 데이터 분석

- 탐색적 데이터 분석
- 모델 선택 및 하이퍼 파라미터 튜닝
-train, test 나누기
- 모델 선택 및 하이퍼 파라미터 튜닝
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)from sklearn.linear_model import LinearRegression
# 수학 공식을 이용한 모델, 하이퍼 파라미터 굳이 쓸게 없다
lr = LinearRegression()from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()▼
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(max_depth = 5, max_features = 0.7, min_samples_leaf = 10,
min_samples_split = 20)- GridSearch 사용하기
from sklearn.model_selection import GridSearchCV
param = {
'n_estimators' : [60, 80, 100, 120, 140],
'max_depth' : [3, 4, 5, 6],
'min_samples_split' : [15, 20, 25, 30],
'min_samples_leaf' : [10, 15, 20, 25],
'max_features' : [0.4, 0.5, 0.6, 0.7]
}
grid_search = GridSearchCV(RandomForestRegressor(), param, cv = 5)
grid_search.fit(X_train, y_train)
grid_search.best_params_
grid_search.best_score_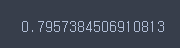
from sklearn.linear_model import Lasso, RidgeLasso Regression + 정규화
Lasso : 모든 가중치에 똑같은 값으로 규제 → 특성 선택
Ridge : 모든 가중치에 똑같은 비율로 규제 → 모든 특성 사용# 규제 조절 : alpha
# alpha 상승 : 규제를 많이 가한다.
# alpha 하강 : 규제를 조금 가한다, alpha를 너무 낮게 잡으면 LinearRegression과 같은 결과
lasso = Lasso(alpha = 0.1)
Ridge = Ridge(alpha = 0.1)- 학습
lr.fit(X_train, y_train)
rf.fit(X_train, y_train)
lasso.fit(X_train, y_train)
Ridge.fit(X_train, y_train)- 예측 및 평가
from sklearn.model_selection import cross_val_score
score = cross_val_score(lr, X_train, y_train, cv = 5)
score.mean()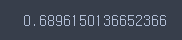
score = cross_val_score(rf, X_train, y_train, cv = 5)
score.mean()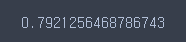
score = cross_val_score(lasso, X_train, y_train, cv = 5)
score.mean()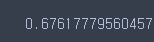
score = cross_val_score(Ridge, X_train, y_train, cv = 5)
score.mean()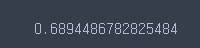

노는게 제일 좋아~!