이번 챕터에서는 2강에 이어서 CentOS 기반 base image 생성을 진행해볼 예정이다.
🎈Python 설치
1. Python & PySpark 설치
# Python 설치
sudo yum install python3 -y
# Python 버전 확인
python3 -V
# PySpark 설치
sudo pip3 install pyspark findspark2. CentOS Python 환경설정
# 시스템 환경변수 편집
sudo vim /etc/profile
# 아래 내용 추가 후 저장
PATH 뒤에 ":/usr/bin/python3" 추가
# 시스템 환경변수 활성화
source /etc/profile
# Python & PySpark 사용자 환경변수 설정
sudo echo 'export PYTHONPATH=/usr/bin/python3' >> ~/.bash_profile
sudo echo 'export PYSPARK_PYTHON=/usr/bin/python3' >> ~/.bash_profile
# 사용자 환경변수 활성화
source ~/.bash_profile🎈Spark 설치
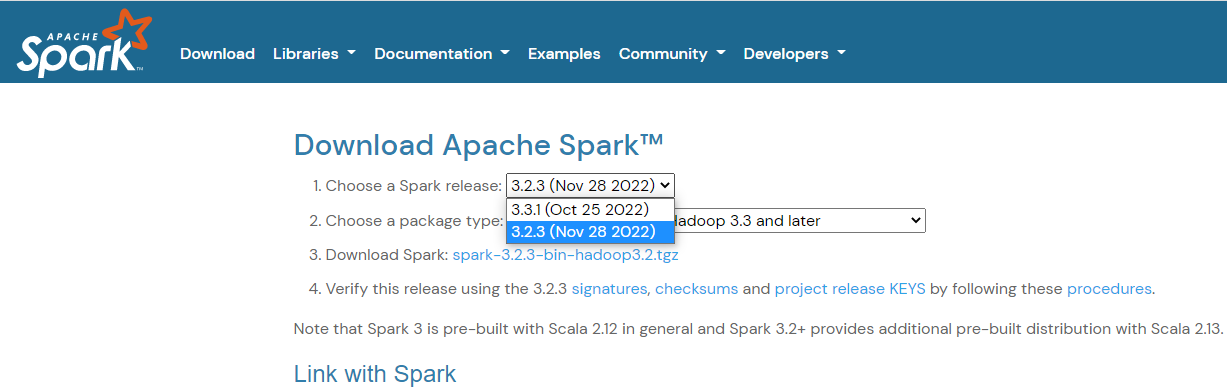
1. Spark 설치 및 압축 해제

- google에서 apache spark download 검색 후 원하는 버전의 Spark url을 가지고 다운로드 후 압축 해제
# 설치 관리용 디렉토리 이동
cd /install_dir
# Spark 3.2.3 설치
wget https://dlcdn.apache.org/spark/spark-3.2.3/spark-3.2.3-bin-hadoop3.2.tgz
# Spark 3.2.1 압축 해제
tar -xzvf spark-3.2.3-bin-hadoop3.2.tgz -C /usr/local
# Spark 디렉토리 이름 변경
mv /usr/local/spark-3.2.3-bin-hadoop3.2 /usr/local/spark2. CentOS Spark 환경설정
# Spark 환경변수 설정
sudo vim /etc/profile
# 아래 내용 추가 후 저장
PATH 뒤에 ":/usr/local/spark/bin" 추가
PATH 뒤에 ":/usr/local/spark/sbin" 추가
SPARK_HOME="/usr/local/spark"
# 시스템 환경변수 활성화
source /etc/profile
# Spark 사용자 환경변수 설정
echo 'export SPARK_HOME=/usr/local/spark' >> ~/.bash_profile
# 사용자 환경변수 활성화
source ~/.bash_profile3. spark-env.sh 수정
# spark-env.sh 파일 카피
cd $SPARK_HOME/conf
sudo cp spark-env.sh.template spark-env.sh
# spark-env.sh 파일 편집
sudo vim spark-env.sh
# 아래 내용 수정 후 저장
export SPARK_HOME=/usr/local/spark
export SPARK_CONF_DIR=/usr/local/spark/conf
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_WEBUI_PORT=180804. spark-defaults.conf 수정
# Spark spark-defaults.conf.template 파일 복사
sudo cp /usr/local/spark/conf/spark-defaults.conf.template /usr/local/spark/conf/spark-defaults.conf
# Spark spark-defaults.conf 파일 설정
sudo vim /usr/local/spark/conf/spark-defaults.conf
# 아래 설정 후 저장
# 클러스터 매니저 정보
spark.master yarn
# 스파크 이벤트 로그 수행 유무
# true시 spark.eventLog.dir에 로깅 경로 지정해야합니다 - 스파크 UI에서 확인 가능합니다.
spark.eventLog.enabled true
# 스파크 이벤트 로그 저장 경로
spark.eventLog.dir /usr/local/spark/logs5. Spark logs 디렉토리 생성
sudo mkdir -p /usr/local/spark/logs6. Spark Worker 수정
# Spark workers 파일 생성
sudo cp /usr/local/spark/conf/workers.template /usr/local/spark/conf/workers
# Spark workers 파일 설정
sudo vim /usr/local/spark/conf/workers
# 아래 설정 후 저장
# localhost -> localhost는 지우던가 주석처리
dn1
dn2
dn3🎈Zookeeper 설치
1. Zookeeper 설치
- Zookeeper 또한 google에서 release 확인 후 버전 다운로드
# 설치 관리용 디렉토리 이동
cd /install_dir
# Zookeeper 3.8.0 설치
sudo wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
# Zookeeper 3.8.0 압축 해제
sudo tar -xzvf apache-zookeeper-3.8.0-bin.tar.gz -C /usr/local
# Zookeeper 디렉토리 이름 변경
sudo mv /usr/local/apache-zookeeper-3.8.0-bin /usr/local/zookeeper2. CentOS Zookeeper 환경변수 설정
# Hadoop 시스템 환경변수 설정
sudo vim /etc/profile
# 아래 내용 추가 후 저장
ZOOKEEPER_HOME="/usr/local/zookeeper"
# 시스템 환경변수 활성화
source /etc/profile
# Spark 사용자 환경변수 설정
echo 'export ZOOKEEPER_HOME=/usr/local/zookeeper' >> ~/.bash_profile
# 사용자 환경변수 활성화
source ~/.bash_profile3. zoo.cfg 수정
# Zookeeper 설정 경로 이동
cd /usr/local/zookeeper
# Zookeeper 설정 파일 복사
sudo cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
# zoo.cfg 편집
sudo vim ./conf/zoo.cfg
# 아래 내용 수정 후 저장
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
clientPort=2181
maxClientCnxns=0
maxSessionTimeout=180000
server.1=nn1:2888:3888
server.2=nn2:2888:3888
server.3=dn1:2888:38884. dataDir 생성 및 myid 수정
# Zookeeper 데이터 디렉토리 생성
sudo mkdir -p /usr/local/zookeeper/data
sudo mkdir -p /usr/local/zookeeper/logs
# Zookeeper 디렉토리 사용자 그룹 변경
sudo chown -R $USER:$USER /usr/local/zookeeper
## 아래는 스크립트로 처리예정
# myid 파일 편집
sudo vim /usr/local/zookeeper/data/myid
# 아래 내용 수정 후 저장
1🎈SSH 설치
1. ssh key 생성 및 접속 테스트
# Docker에서 SSH 시작을 위해 설치
yum -y install initscripts
# SSH 시작
service sshd start
# ssh(22 port listen 확인)
netstat -nplt
# ssh key 생성
ssh-keygen -t rsa # 이후 Enter만 세 번 입력 탁! 탁! 탁!
# authorized_keys 생성
cat >> ~/.ssh/authorized_keys < ~/.ssh/id_rsa.pub
# localhost 접속 테스트
ssh localhost
# Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
# authorized_keys를 이용해 추후 모든 node들이 통신을 할 수 있도록 key값 수정
vim authorized_keys
# 복사된 key값 뒤에 node 개수만큼 복사 후 host name 수정수정 authorized_keys 결과값
🎈Container 이미지 생성
기초 설치가 완료된 컨테이너를 이미지로 만들어서 5개의 서버에 배포할 예정이다.
1. docker commit
# docker login 명령어
docker login
docker hub ID 입력
docker hub Password 입력
# Login 완료 문구 출력됨
# docker image 만들기
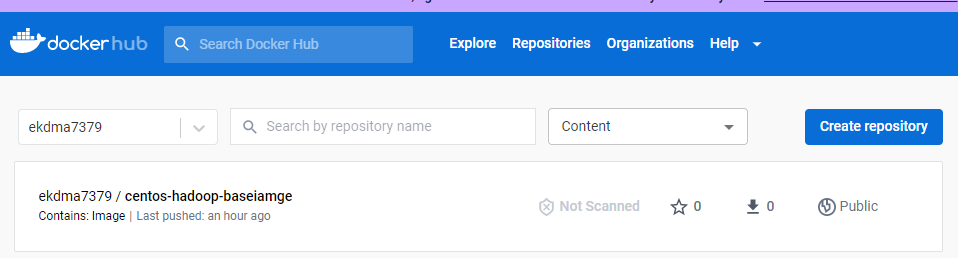
docker commit nn1 ekdma7379/centos-hadoop-baseiamge
# docker image 생성이 잘 되었는지 확인
docker images
# docker image를 docker hub에 업로드
docker push ekdma7379/centos-hadoop-baseiamge결과적으로 다음과 같이 docker hub에 push된 부분을 확인할 수 있다.
🎈[참조]

개발자입니다.