On-Premise 서버 간 네트워크 통신을 위해 Overlay 네트워크를 구성하고 hostname, rpc 통신을 위한 static IP 할당을 하여 Docker Container를 실행한다.
실행된 Container 끼리 Overlay 네트워크로 할당된 IP를 통해 SSH 통신까지 마무리 지을 예정이다.
🎈서버 속 Container간 통신 세팅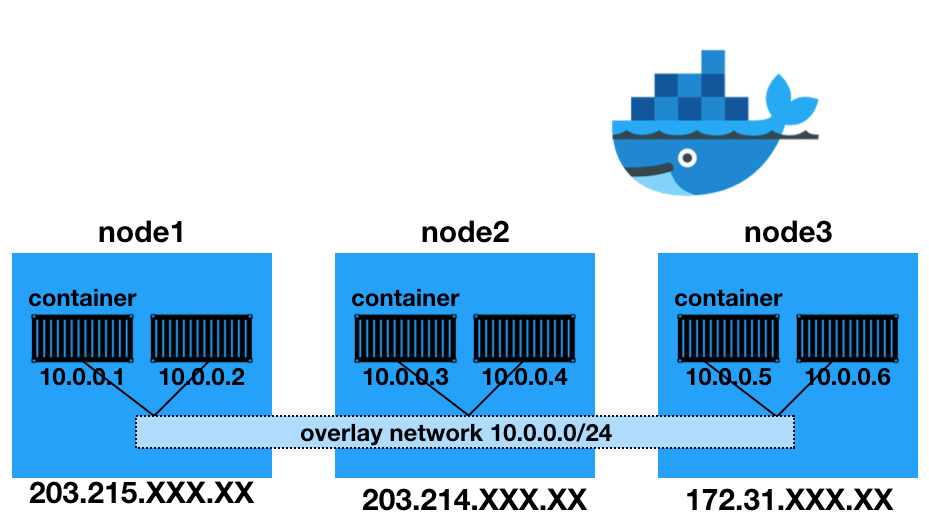
- 각 서버끼리 다른 대역대 안에서 통신 및 관리가 힘든 부분을 해소하기 위해 논리적으로 이를 해결하고자 Docker swarm Overlay Network를 사용할 예정
- Overlay network는 여러 서버의 Docker daemon hosts 간의 분산 네트워크이고
Overlay 네트워크를 통해 각기 다른 서버의 IP 주소와 상관없이 같은 subnet mask의 내부 주소를 부여받게 되고, 이를 통해 쉽게 Hadoop 클러스터를 구성 가능
1. docker swarm 세팅
- Overlay Network 세팅을 위한 Swarm cluster 구축
# docker swarm 초기화
# Master 서버(현 프로젝트에서는 NN1)에서 실행
# 문법 : docker swarm init --advertise-addr [HOST-IP]
docker swarm init
# 출력된 join 명령어를 node 서버에서 실행
# 이후 기존 서버 이외에 추가로 서버를 Cluster 할 경우 해당 명령어로 token값 출력
docker swarm join-token worker
# 출력된 token 명령어를 가지고 node 서버로 접속하여 실행
# [ip] 부분은 Master IP로 대체되어 출력됨
docker swarm join --token SWMTKN-1-4x0tosxigd4kzpltrefulopdhx29fljtnomxey4kcj65kyc4dp-3y2cfby45emgx8dtbxfbif4a0 [ip]:2377
# 모든 Node Join 완료 후 Node 목록 확인
docker node ls[docker node ls 결과]
명령어 결과에서 AVAILABILITY 값은 스케줄러(scheduler)가 Node에게 task를 부여할 수 있는지 확인할 수 있습니다.
- Active : scheduler가 task 할당이 가능한 상태입니다.
- Pause : 이미 존재하는 task는 실행 중이지만, scheduler가 새로운 task에 대해서는 할당할 수 없습니다.
- Drain : 이미 존재하는 task도 shutdown되며, 사용가능한 node로 스케줄링하게 됩니다. scheduler가 새로운 task에 대해서는 할당할 수 없습니다.
2. Overlay Network 생성
# 현재 docker network를 확인
sudo docker network ls
# docker swarm Overlay Network 생성
# 문법 sudo docker network create -d overlay --attachable --subnet=[SUBNET_MASK] [NETWORK_NAME]
docker network create -d overlay --attachable --subnet 10.11.11.0/24 centos-hadoop-net
# 도커 네트워크 리스트에서 centos-hadoop-net 생성 확인
docker network ls
# 생성된 네트워크 정보 보기
docker network inspect centos-hadoop-net🎈Container 실행
# master namenode(nn1) 서버에서 실행
sudo docker run -dit --name nn1 --hostname nn1 --network centos-hadoop-net --ip 10.11.11.2 -p 18080:18080 -p 50070:50070 -p 8088:8088 -p 18888:18888 --add-host=nn1:10.11.11.2 --add-host=nn2:10.11.11.3 --add-host=dn1:10.11.11.4 --add-host=dn2:10.11.11.5 ekdma7379/centos-hadoop-baseimage:0.2 /bin/bash
# standby namenode(nn2)서버에서 실행
sudo docker run -dit --name nn2 --hostname nn2 --network centos-hadoop-net --ip 10.11.11.3 -p 18080:18080 -p 50070:50070 -p 8088:8088 -p 18888:18888 --add-host=nn1:10.11.11.2 --add-host=nn2:10.11.11.3 --add-host=dn1:10.11.11.4 --add-host=dn2:10.11.11.5 ekdma7379/centos-hadoop-baseimage:0.2 /bin/bash
# datanode 1(dn1)서버에서 실행
sudo docker run -dit --name dn1 --hostname dn1 --network centos-hadoop-net --ip 10.11.11.4 --add-host=nn1:10.11.11.2 --add-host=nn2:10.11.11.3 --add-host=dn1:10.11.11.4 --add-host=dn2:10.11.11.5 ekdma7379/centos-hadoop-baseimage:0.2 /bin/bash
# datanode 2(dn2)서버에서 실행
sudo docker run -dit --name dn2 --hostname dn2 --network centos-hadoop-net --ip 10.11.11.5 --add-host=nn1:10.11.11.2 --add-host=nn2:10.11.11.3 --add-host=dn1:10.11.11.4 --add-host=dn2:10.11.11.5 ekdma7379/centos-hadoop-baseimage:0.2 /bin/bash
# 각 서버(nn1,nn2,dn1,dn2)에 exec 로 접속
# 현재 예제는 nn1 서버
docker exec -it nn1 /bin/bash
# ssh daemon 시작
service sshd start
# nn1,nn2,dn1,dn2
ssh nn1
fingerprint -> yes
exit
ssh nn2
fingerprint -> yes
exit
ssh dn1
fingerprint -> yes
exit
ssh dn2
fingerprint -> yes
exit이렇게 서로 컨테이너간 ssh 통신이 되는 환경 구축이 완료되었다.
다음 챕터에서는 Spark를 실행할 수 있도록 Hadoop Ecosystem 전반적으로 실행하는 실습을 진행해보도록 하겠다.
참조

개발자입니다.