Zookeeper, Hadoop & yarn, Spark Cluster & PySpark 실행 확인(WEB UI로 확인)
전체 시작,종료 Script 작성하여 장애대응을 할 수 있도록 준비할 예정이다.
🎈Zookeeper 실행
1. Zookeeper myid 파일 편집
- 해당 내용은 추후 전체 시작 스크립트에서 수정 가능하도록 반영할 예정
# nn2 서버로 이동
ssh nn2
sudo vim /usr/local/zookeeper/data/myid
# 아래 내용으로 수정 후 저장
2
# nn1으로 이동
exit
# dn1 서버로 이동
ssh dn1
sudo vim /usr/local/zookeeper/data/myid
# 아래 내용으로 수정 후 저장
3
# nn1으로 이동
exit2. Zookeeper 실행 및 상태 확인
# nn1 zookeeper 시작
sudo /usr/local/zookeeper/bin/zkServer.sh start
sudo /usr/local/zookeeper/bin/zkServer.sh status
# nn2 zookeeper 시작
ssh nn2
sudo /usr/local/zookeeper/bin/zkServer.sh start
sudo /usr/local/zookeeper/bin/zkServer.sh status
exit
# dn1 zookeeper 시작
ssh dn1
sudo /usr/local/zookeeper/bin/zkServer.sh start
sudo /usr/local/zookeeper/bin/zkServer.sh status
exit🎈HADOOP 실행
1. HDFS ZKFC 초기화
# nn1에서 실행
# zkfc 초기화
hdfs zkfc -formatZK2. HDFS ZKFC 초기화 확인
# nn1에서 실행
# zkCli 실행
cd /usr/local/zookeeper
./bin/zkCli.sh
# Hadoop 클러스터 확인
ls /hadoop-ha
# [my-hadoop-cluster] 확인 후 quit 명령으로 종료
# 종료
quit3. Journalnode 실행
- hdfs 변경사항을 기록하는 node
- jps 시 journalnode 실행
# nn1에서 실행
hdfs --daemon start journalnode
# nn2에서 실행
ssh nn2
hdfs --daemon start journalnode
exit
# dn1에서 실행
ssh dn1
hdfs --daemon start journalnode
exit4. Namenode 초기화 & 실행
- jps 시 namenode 실행
# nn1에서 실행
hdfs namenode -format
# hdfs namenode 실행
hdfs --daemon start namenode5. Standby Namenode 실행
- Failover에 대비하기 위한 Namenode 실행
- 아직 jps 시 출력 X
# hdfs standby namenode 실행
ssh nn2
hdfs namenode -bootstrapStandby6. Hadoop & Yarn 실행
# nn1에서 실행
# hadoop 실행
# 해당 단계에서 “DFSZKFailoverController” 프로세스가 실행
start-dfs.sh
# yarn 실행
# 해당 단계에서 “ResourceManager” 프로세스가 실행
# 나머지 DataNode 서버에서는 “NodeManager” 프로세스가 실행
start-yarn.sh
# mapred 실행
# 해당 단계에서 “JobHistoryServer” 프로세스가 실행
mapred --daemon start historyserver
# Namenode active standby 확인
hdfs haadmin -getServiceState namenode1
hdfs haadmin -getServiceState namenode2실행 결과 Jps
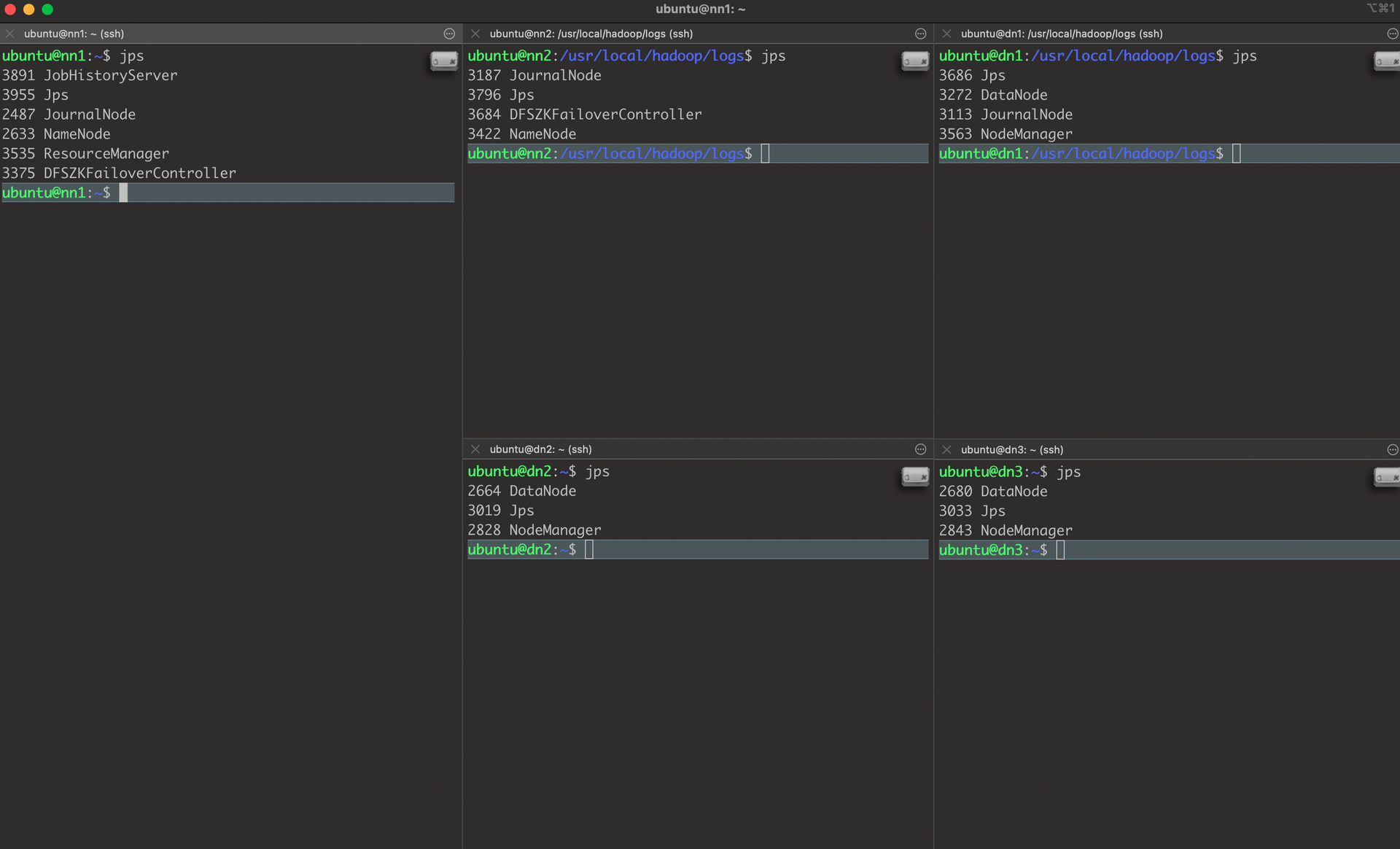
7. hadoop 실행 테스트 예제 - wordcount
# nn1에서 실행
# HDFS test 디렉토리 생성
hdfs dfs -mkdir /test
# HDFS LICENSE.txt 파일을 test 디렉토리에 삽입
hdfs dfs -put /usr/local/hadoop/LICENSE.txt /test/
# Word Count 예제 실행
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar wordcount hdfs:///test/LICENSE.txt /test/output
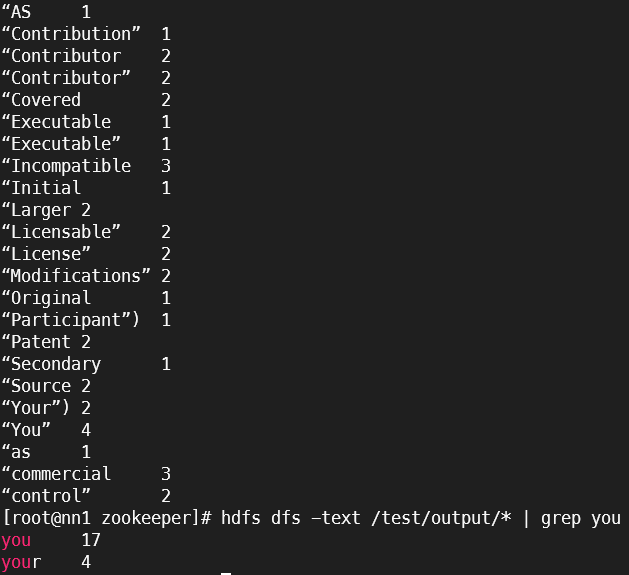
# Worn Count 결과 확인
hdfs dfs -text /test/output/*hdfs dfs -text /test/output/* 결과
🎈Spark 실행
1. Spark Cluster 및 예제 실행
# nn1 에서 실행
# Spark Cluster 시작
$SPARK_HOME/sbin/start-all.sh
# Spark 예제
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode cluster --driver-memory 512m \
--executor-memory 512m --executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.2.1.jar 5cluster 시작 결과
Spark 예제 결과
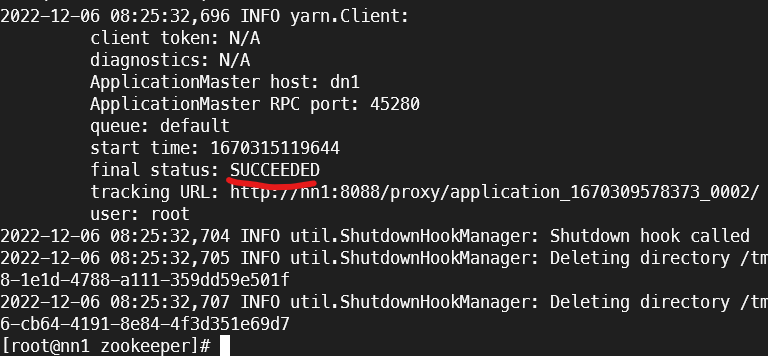
2. PySpark ex1) print 출력
# 폴더 만들기
mkdir ~/pyspark
cd ~/pyspark
# 스크립트 편집
vim pyspark_example.py
# pyspark_example.py 아래 내용 저장
from pyspark import SparkContext, SparkConf
conf = SparkConf()
conf.setMaster("yarn")
conf.setAppName("wontak Test")
sc = SparkContext(conf=conf)
print("="*100, "\n")
print(sc)
print("="*100, "\n")
# 실행 명령어 client mode
# 로그 및 출력을 직접적으로 보고 싶을때
clear && spark-submit --master yarn --deploy-mode client pyspark_example.py
# 실행 명령어 cluster mode
# 분산처리로 처리해야 할 때
clear && spark-submit --master yarn --deploy-mode cluster pyspark_example.py2. PySpark ex2) 영화목록 출력
CSV파일 : KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv
# local(windows)에서 onpremise서버로
scp C:\Users\202203002\Downloads\KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv [user계정]@[서버ip]:~/
# docker에 파일 복사
docker cp KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv nn1:/root/pyspark
hdfs dfs -put KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv /test/
# HDFS 디렉토리 확인
hdfs dfs -ls /test
# 스크립트 편집
vim pyspark_example2.py
# pyspark_example2.py 아래 내용 저장
from pyspark.sql import SparkSession
sc = SparkSession.builder\
.master("yarn")\
.appName("Jmkim Test")\
.getOrCreate()
df = sc.read.csv("hdfs:///test/KC_KOBIS_BOX_OFFIC_MOVIE_INFO_202105.csv", header=True)
df.show()
# 실행 명령어
clear && spark-submit --master yarn --deploy-mode client pyspark_example2.py🎈 Web UI 확인
1. Spark Web UI
http://[nn1서버 Public IP]:18080
2. Yarn Web UI
http://[nn1서버 Public IP]:8088
3. Hadoop Web UI
http://[nn1서버 Public IP]:50070
http://[nn2서버 Public IP]:50070
- 둘중 하나는 Active, 나머지는 Standby이다.
[참고]

개발자입니다.