📝 오늘 공부한 내용
Clustering: 비슷한 데이터끼리 묶는 방법
- unsupervised learning
- 데이터에 정답이 필요 없다. (학습할 때 사용하지 않는다.)
💡 clustering과 classification은 다르다!
classification은 사과, 복숭아, 오렌지, 토마토, 배추, 청경채라는 데이터가 있을 때 '과일', '야채'로 분류하는 것이고,
clustering은 레이블이 존재 하지 않는 상태에서 데이터들의 특성을 파악하여 군집을 형성하는 것이다. 몇 개의 군집이 형성될지 모르고 학습 시작!
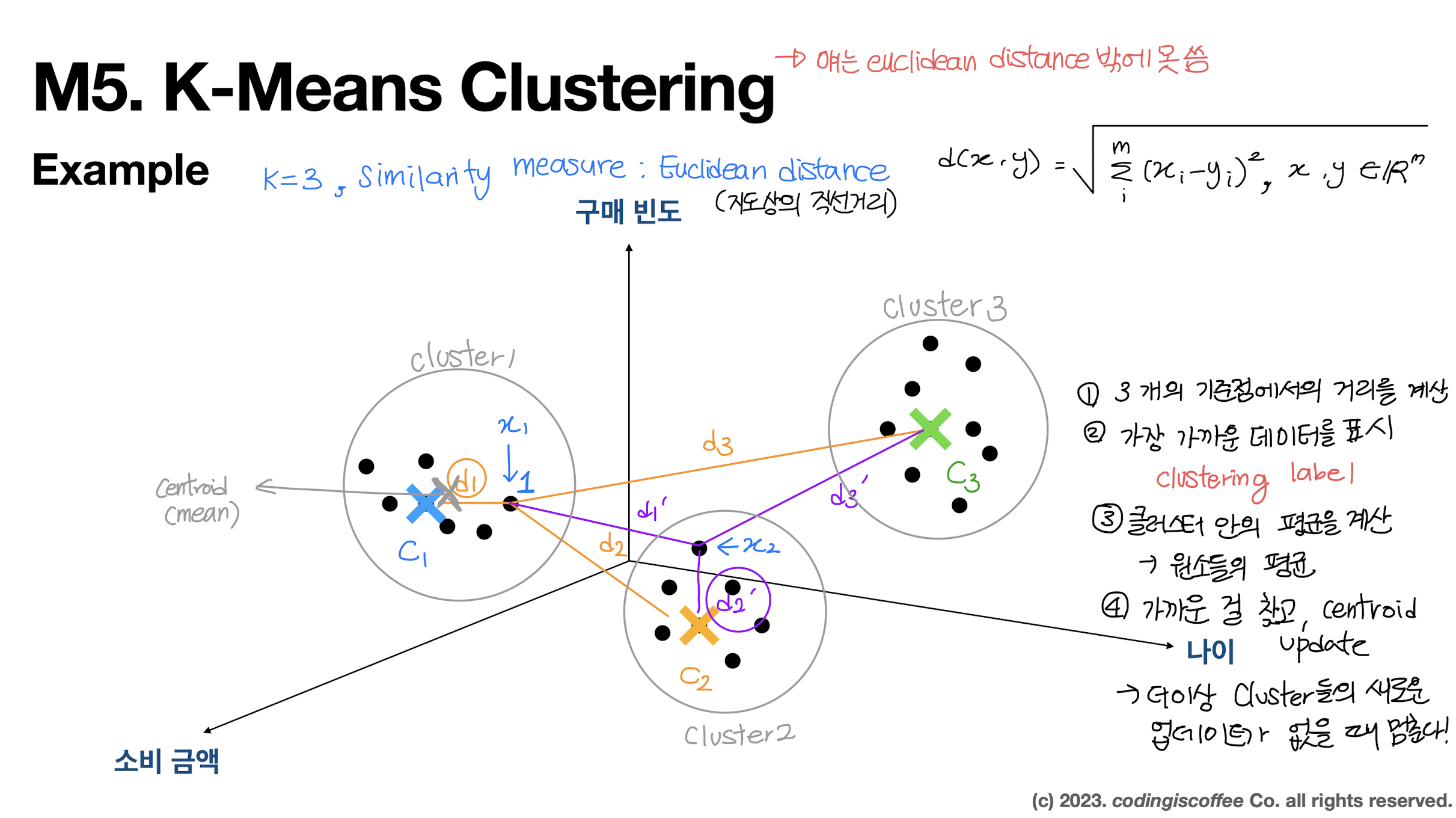
K-Means Clustering
- 클러스터링 방법 중 가장 대표적인 방법
- K-평균 알고리즘
- 매우 빠른 속도
K-Means Clustering Procedure
- 랜덤하게 K개의 데이터 선택
- centroid에 assign되지 않은 데이터에 대해 K개의 데이터 중 가장 가까운 데이터를 찾는다.
- 가깝다고 정해진 데이터끼리 묶어서 새로운 클러스터를 만들고
- 새로운 클러스터 안에서 데이터들의 평균을 구한다.
- 새로 계산한 평균을 K개의 기준으로 정한다.
- 2번 과정부터 반복
- 더이상 centroid가 업데이트 되지 않는다면 종료한다.
K-Means의 한계점
- 초기에 선택되는 K개의 데이터 (initial centroid)에 따라 성능 편차가 크다.
- 평균이 의미 없는 데이터에는 효과 없음
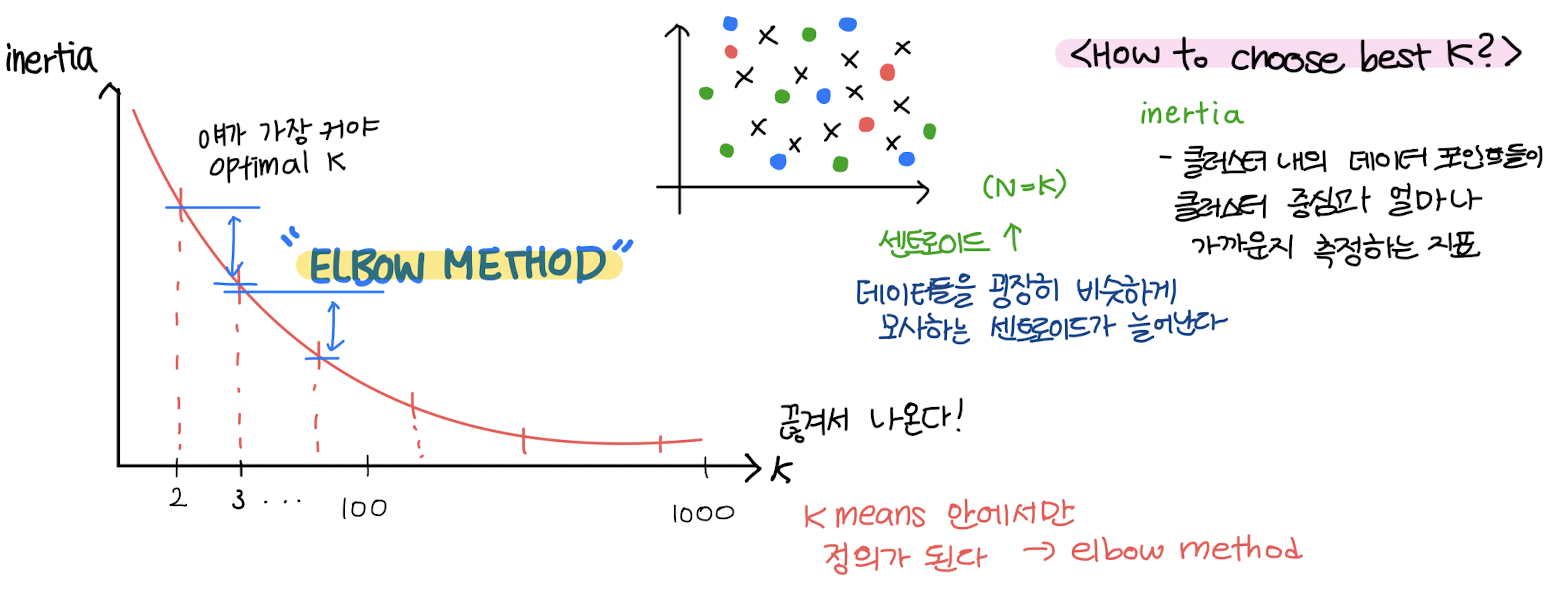
Choose Best K
Inertia
- 클러스터 내의 데이터 포인트들이 클러스터 중심과 얼마나 가까운지 측정하는 지표
Hierarchical Agglomerative Clustering
- 데이터의 계층 구조를 파악하는 클러스터링 방법
- 비슷한 데이터들끼리 서로 묶어가면서 모든 클러스터들을 묶어가는 방법
- 묶어가면서 큰 것 하나 가져간다.
