벌써 6월이라니! 믿기지 않아...2023년의 절반이나 왔다니 ㅎㅎ
2023년의 남은 6개월도 뒤돌아 봤을 때 후회하지 않고 웃을 수 있는 나날들이 가득했으면 좋겠다.
📝 오늘 공부한 내용
Classification Tree
Gini Index
- 데이터의 불순도 (impurities) 판별
- 다른 종류의 데이터들이 많이 섞여 있을 수록 불순도 높음
- 하나의 class만 있을 때는 순수
Gini Index in Decision Tree
- gini index가 가장 작은 값을 DT의 root로 설정한다.
- 모든 candidate에 대해서 Gini Index가 가장 작은 기준으로 데이터를 분할
- 이렇게 해야 numeric features를 기준으로 DT를 만들 수 있다.
Regression Tree
Sum of Squared Residual (Practice SSR)
매번 노드의 split되는 기준을 찾는 법
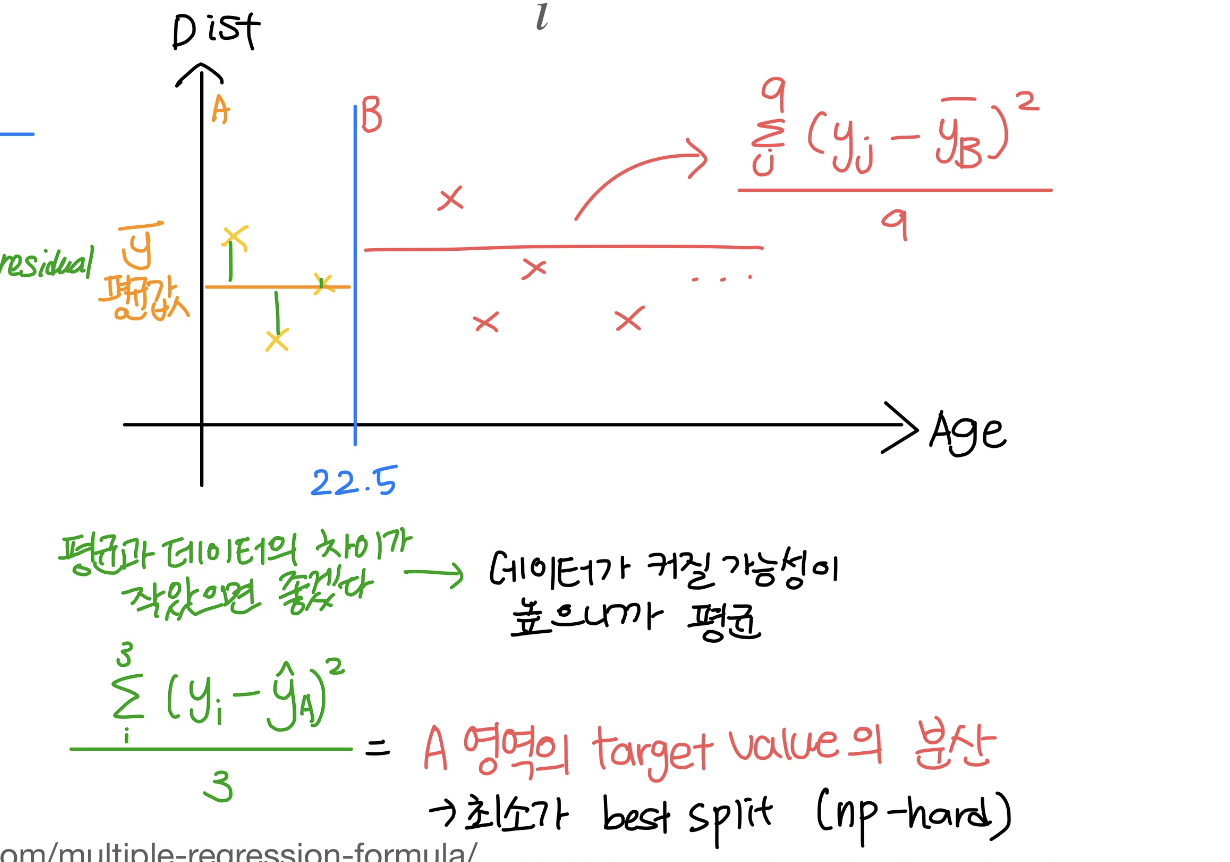
Procedure
- 영역을 나누고 (왼, 오)
- 왼, 오 분산 계산
- 작은걸 고르자~ (why? 우리는 평균과 데이터의 차이가 작았으면 좋겠어! 데이터가 커질 가능성이 높으니까)
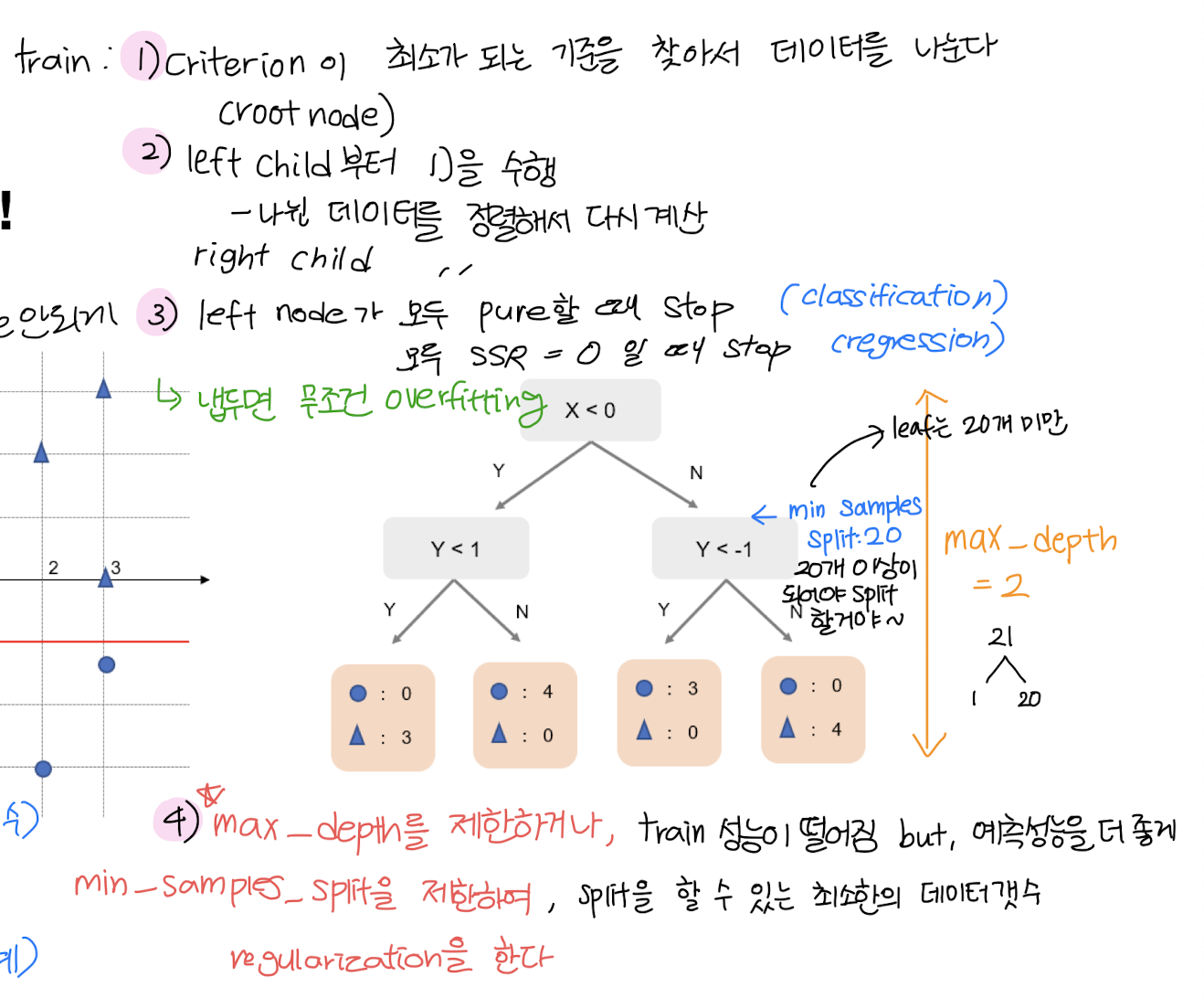
CART
꼭 Balanced Tree일 필요없다!
- min samples를 건드리면 Balance가 됮 않는다!
- 왜 unbalanced tree? -> 데이터를 하나씩 가질 때까지 (pure leaf) 쪼개면 overfitting이 나온다.
Procedure)
Random Forest
DT는 학습을 했는데 예측 성능이 높게 나오지 않아 -> 여러 DT를 모아서 집단 지성으로 쓰자!
Ensemble
강력한 하나의 모델을 사용하는대신 보다 약한 모델 여러개를 조합하여 더 정확한 예측에 도움
Random Forest = Bagging + Random Subspace method
- Random: weak learners들을 모우자~
Bagging (Bootstrap Aggregating)
Data Sampling
1. 데이터를 N개 뽑는다
2. 복원 추출 방식 (여러 개의 학습데이터 추출)
예측모델 판별
- 분류: majority vote
- 회귀: mean
🌷 느낀점
첫 앙상블 모델을 배웠다. 내일은 어떤 앙상블 모델을 배울까 기대가 많이 된다.
머신러닝을 배우면서 이론을 얼마나 깊게 공부해야 하는지에 대한 고민이 많다.
정말 깊게 들어가면 흐름을 놓칠까봐 걱정도 되고... 그래도 수업이 끝나고 나서 부족한 부분을 채워넣고 완벽하게는 아니더라도 충분히 만족할 수 있을만큼 공부를 하고싶다. 화이팅!
