[산업분석] How analog in-memory computing can solve power challenges of edge AI inference
반도체 산업분석 기사요약
요약
서론
머신러닝(ML)과 딥러닝(DL)을 포함한 AI는 이미 우리 삶 깊숙이 자리 잡았다. 자연어 처리(NLP), 이미지 분류(classification) 그리고 객체 인식(object detection)은 우리가 사용하는 많은 디바이스 속에 하나의 기술로 내장돼있다. 하지만, 시간이 흐름에 따라 AI 학습 데이터의 양(volume)과 크기(size)는 비례해서 증가하고 있다. 메모리는 더 많이 요구되고 더 낮은 레이턴시를 구현하기 위해서는 폰 노이만 구조의 전형적인 병목(bottleneck)현상을 해소해야만 한다. 이러한 발전양상에 따라 현대 AI는 ⓐ 사생활(Privacy), ⓑ 전력 소비(Power Dissipation), ⓒ 비용(Cost) 위주로 도전과제를 안고 있다.
본론 1 :: 클라우드(Cloud) 컴퓨팅의 도전과제
현대 클라우드 컴퓨팅은 [데이터 업로드 (edge to cloud) → 클라우드 컴퓨팅 → 예측 결과 반환 (cloud to edge) → 기능 수행] 순서로 이뤄지고 있다. 이 과정에서 파생되는 문제점은 다음과 같다.
- 프라이버시 및 보안 문제
- 클라우드 컴퓨팅을 이용하는 많은 디바이스는 'always-on, always-aware'을 지향하는 IoT 디바이스이므로 personal data 또는 confidential information을 가지고 있는 경우가 많다.
- 업로드 및 다운로드 과정에서 정보가 유출돼 악용될 여지가 있다.
- 불필요한 전력 소비
- 엣지 디바이스는 클라우드와 항시 연결돼 정보를 주고받는다.
- 의도치 않은 전력 낭비가 생길 수 있으며 IoT 디바이스에서 이는 치명적이다.
- 레이턴시
- 네트워크 상황 또는 과부하로 인해 클라우드 서버로부터 레이턴시가 발생할 수 있다.
- 사람은 100ms 이상의 레이턴시는 감지할 수 있기 때문에 불편함을 일으킬 수 있다.
- 과도한 정보 처리
- 클라우드는 엣지 디바이스로부터 전송되는 데이터는 '의미가 있는' 정보로 간주하고 약속된 컴퓨팅을 수행한다.
- 센서로부터 unaffordable 데이터가 전송될 때 클라우드는 구분할 능력이 없다.
- 따라서 클라우드는 예상보다 과도한 정보를 처리할 가능성이 있다.
위 문제들을 해결하기 위한 한 가지 방법으로 추론(interference) 연산의 주체를 클라우드로부터 local로 바꿔야 한다는 의견이 지배적이다. 결과적으로, 학습 부분은 로컬 GPU/FPGA/TPU/NPU 또는 클라우드에서 진행하고, 생성된 모델을 작은 컴퓨팅 디바이스에서도 동작할 수 있게끔 최적화를 수행한 뒤 엣지 디바이스에서 추론을 진행하게 된다.
본론 2 :: Neural Network Model 구조에 대한 소개
더 깊은 내용을 진행하기 전, CNN, DNN과 같은 model 속 공통 구조에 대한 소개를 먼저 진행한다.
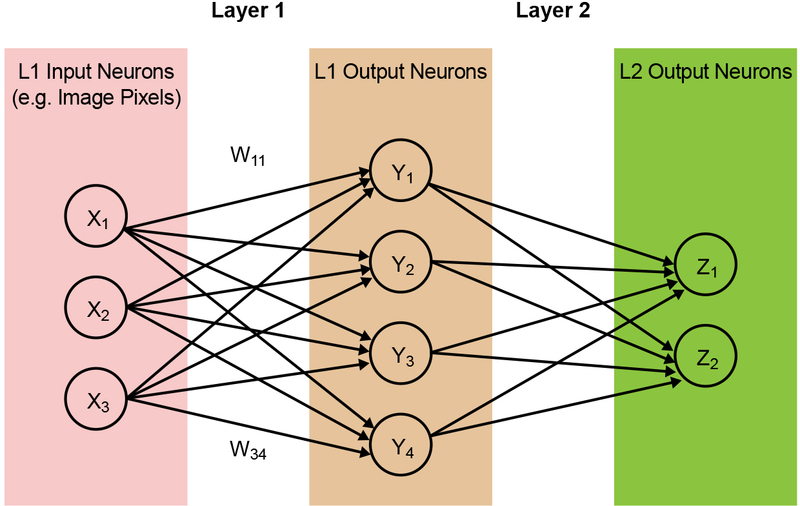
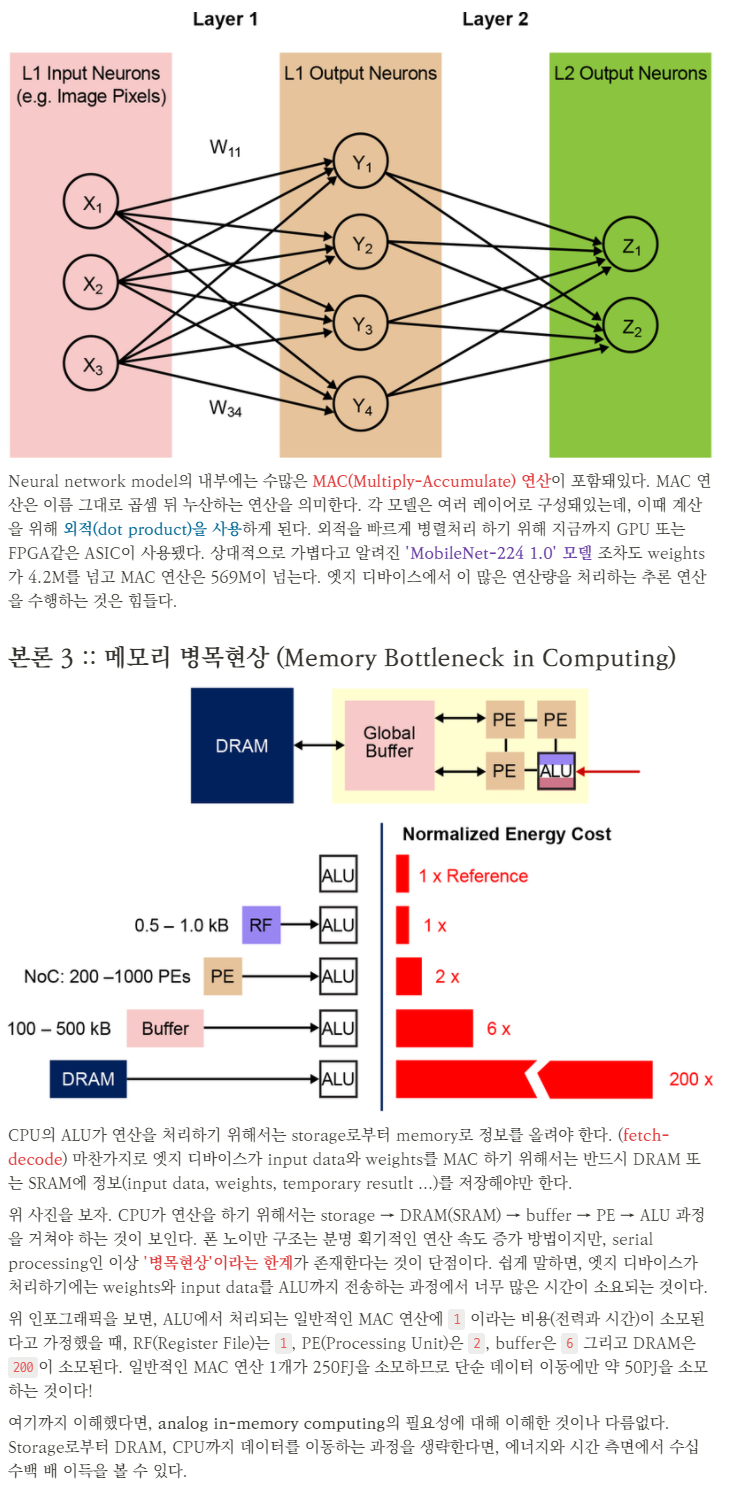
Neural network model의 내부에는 수많은 MAC(Multiply-Accumulate) 연산이 포함돼있다. MAC 연산은 이름 그대로 곱셈 뒤 누산하는 연산을 의미한다. 각 모델은 여러 레이어로 구성돼있는데, 이때 계산을 위해 외적(dot product)을 사용하게 된다. 외적을 빠르게 병렬처리 하기 위해 지금까지 GPU 또는 FPGA같은 ASIC이 사용됐다. 상대적으로 가볍다고 알려진 'MobileNet-224 1.0' 모델 조차도 weights가 4.2M를 넘고 MAC 연산은 569M이 넘는다. 엣지 디바이스에서 이 많은 연산량을 처리하는 추론 연산을 수행하는 것은 힘들다.
본론 3 :: 메모리 병목현상 (Memory Bottleneck in Computing)
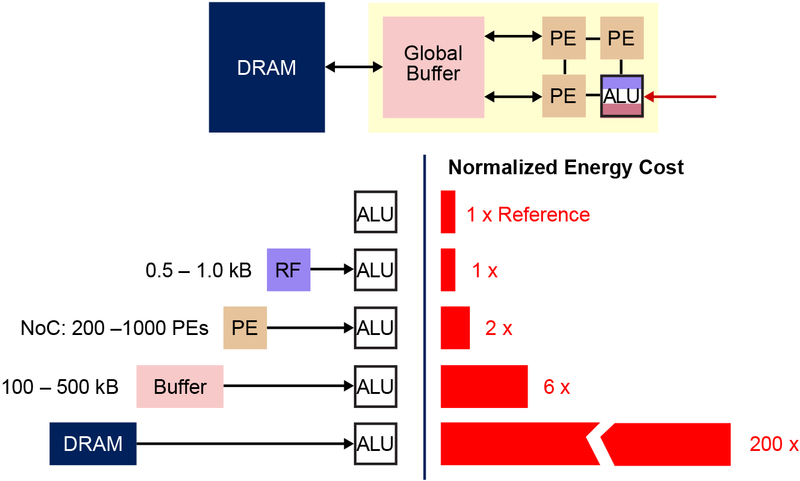
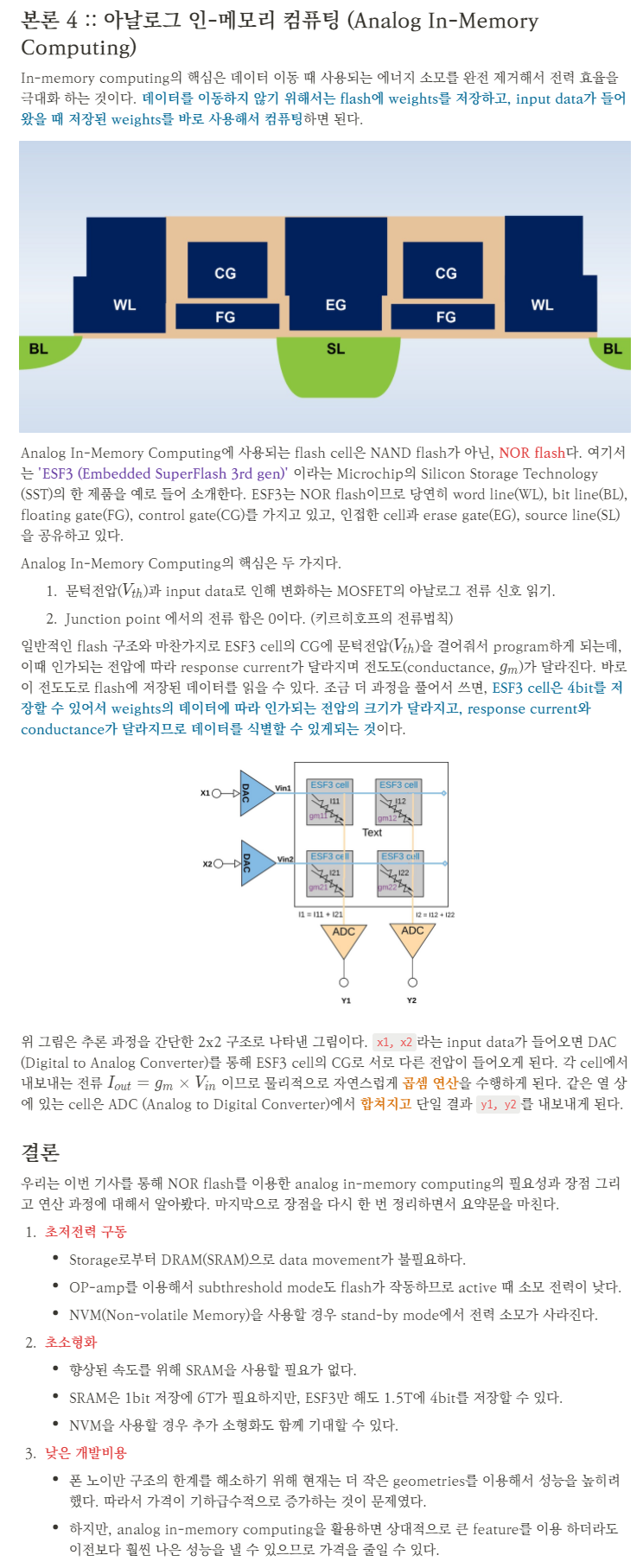
CPU의 ALU가 연산을 처리하기 위해서는 storage로부터 memory로 정보를 올려야 한다. (fetch-decode) 마찬가지로 엣지 디바이스가 input data와 weights를 MAC 하기 위해서는 반드시 DRAM 또는 SRAM에 정보(input data, weights, temporary resutlt ...)를 저장해야만 한다.
위 사진을 보자. CPU가 연산을 하기 위해서는 storage → DRAM(SRAM) → buffer → PE → ALU 과정을 거쳐야 하는 것이 보인다. 폰 노이만 구조는 분명 획기적인 연산 속도 증가 방법이지만, serial processing인 이상 '병목현상'이라는 한계가 존재한다는 것이 단점이다. 쉽게 말하면, 엣지 디바이스가 처리하기에는 weights와 input data를 ALU까지 전송하는 과정에서 너무 많은 시간이 소요되는 것이다.
위 인포그래픽을 보면, ALU에서 처리되는 일반적인 MAC 연산에 1 이라는 비용(전력과 시간)이 소모된다고 가정했을 때, RF(Register File)는 1, PE(Processing Unit)은 2, buffer은 6 그리고 DRAM은 200이 소모된다. 일반적인 MAC 연산 1개가 250FJ을 소모하므로 단순 데이터 이동에만 약 50PJ을 소모하는 것이다!
여기까지 이해했다면, analog in-memory computing의 필요성에 대해 이해한 것이나 다름없다. Storage로부터 DRAM, CPU까지 데이터를 이동하는 과정을 생략한다면, 에너지와 시간 측면에서 수십 수백 배 이득을 볼 수 있다.
본론 4 :: 아날로그 인-메모리 컴퓨팅 (Analog In-Memory Computing)
In-memory computing의 핵심은 데이터 이동 때 사용되는 에너지 소모를 완전 제거해서 전력 효율을 극대화 하는 것이다. 데이터를 이동하지 않기 위해서는 flash에 weights를 저장하고, input data가 들어왔을 때 저장된 weights를 바로 사용해서 컴퓨팅하면 된다.
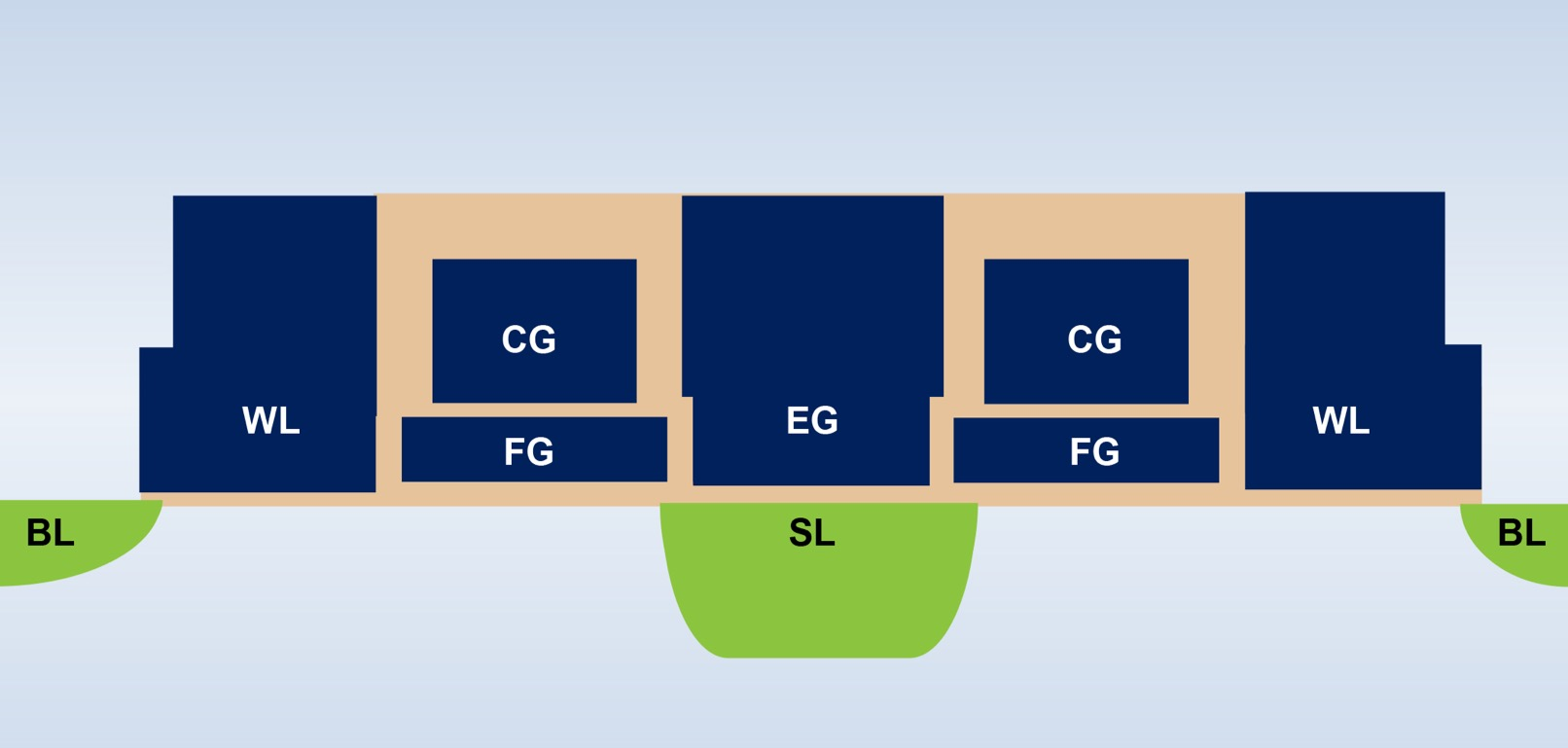
Analog In-Memory Computing에 사용되는 flash cell은 NAND flash가 아닌, NOR flash다. 여기서는 'ESF3 (Embedded SuperFlash 3rd gen)' 이라는 Microchip의 Silicon Storage Technology (SST)의 한 제품을 예로 들어 소개한다. ESF3는 NOR flash이므로 당연히 word line(WL), bit line(BL), floating gate(FG), control gate(CG)를 가지고 있고, 인접한 cell과 erase gate(EG), source line(SL)을 공유하고 있다.
Analog In-Memory Computing의 핵심은 두 가지다.
- 문턱전압()과 input data로 인해 변화하는 MOSFET의 아날로그 전류 신호 읽기.
- Junction point 에서의 전류 합은 0이다. (키르히호프의 전류법칙)
일반적인 flash 구조와 마찬가지로 ESF3 cell의 CG에 문턱전압()을 걸어줘서 program하게 되는데, 이때 인가되는 전압에 따라 response current가 달라지며 전도도(conductance, )가 달라진다. 바로 이 전도도로 flash에 저장된 데이터를 읽을 수 있다. 조금 더 과정을 풀어서 쓰면, ESF3 cell은 4bit를 저장할 수 있어서 weights의 데이터에 따라 인가되는 전압의 크기가 달라지고, response current와 conductance가 달라지므로 데이터를 식별할 수 있게되는 것이다.
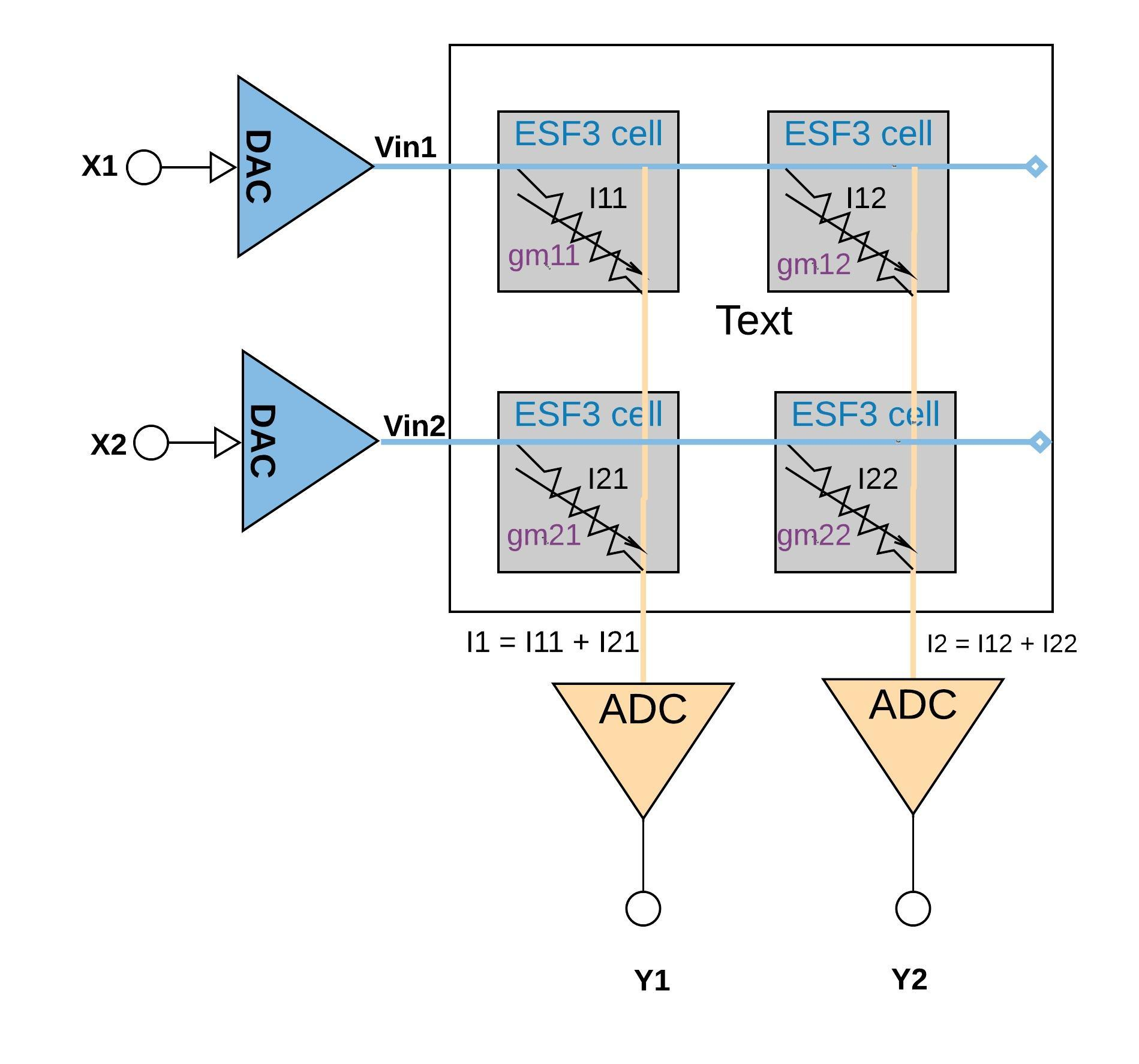
위 그림은 추론 과정을 간단한 2x2 구조로 나타낸 그림이다. x1, x2라는 input data가 들어오면 DAC (Digital to Analog Converter)를 통해 ESF3 cell의 CG로 서로 다른 전압이 들어오게 된다. 각 cell에서 내보내는 전류 이므로 물리적으로 자연스럽게 곱셈 연산을 수행하게 된다. 같은 열 상에 있는 cell은 ADC (Analog to Digital Converter)에서 합쳐지고 단일 결과 y1, y2를 내보내게 된다.
결론
우리는 이번 기사를 통해 NOR flash를 이용한 analog in-memory computing의 필요성과 장점 그리고 연산 과정에 대해서 알아봤다. 마지막으로 장점을 다시 한 번 정리하면서 요약문을 마친다.
- 초저전력 구동
- Storage로부터 DRAM(SRAM)으로 data movement가 불필요하다.
- OP-amp를 이용해서 subthreshold mode도 flash가 작동하므로 active 때 소모 전력이 낮다.
- NVM(Non-volatile Memory)을 사용할 경우 stand-by mode에서 전력 소모가 사라진다.
- 초소형화
- 향상된 속도를 위해 SRAM을 사용할 필요가 없다.
- SRAM은 1bit 저장에 6T가 필요하지만, ESF3만 해도 1.5T에 4bit를 저장할 수 있다.
- NVM을 사용할 경우 추가 소형화도 함께 기대할 수 있다.
- 낮은 개발비용
- 폰 노이만 구조의 한계를 해소하기 위해 현재는 더 작은 geometries를 이용해서 성능을 높히려했다. 따라서 가격이 기하급수적으로 증가하는 것이 문제였다.
- 하지만, analog in-memory computing을 활용하면 상대적으로 큰 feature를 이용 하더라도 이전보다 훨씬 나은 성능을 낼 수 있으므로 가격을 줄일 수 있다.