
[※] Chapter 5의 아래 부분은 요약 및 정리에서 생략하도록 합니다.
- [※] Context와 AAPCS (Chapter 2에서 이미 설명했습니다.)
- [※] Pointer와 배열은 ~ Stack과 heap에 대한 소고 (p.365~385) (기초 CS 내용입니다.)
- [※] 함수가 불렸을 때 일어나는 일(p.395) (기초 CS 내용이고 본문에 설명이 잘 돼있습니다.)
1. Stack
1.1. Stack의 구현과 종류
- 임베디드 시스템에서는 stack도 heap도 모두 초기화 되지 않은 (전역)변수의 array로 돼있다.
- 메모리 상에 연속적인 영역(
.bss)에 위치해있으며 array의 이름을 알고 있으니 디버깅 때 언제든 접근할 수 있다.
- 메모리 상에 연속적인 영역(
- 일반적으로 stack은 높은주소(상위주소)에서 낮은주소(하위주소)로, 아래로 쌓이는 구조를 가지고 있다.
- 하지만, 장담할 수 없으며 어떻게 쌓이는지는 그 구현에 따라 다르므로 사용하는 MCU의 datasheet를 잘 봐야 한다.
- Stack과 stack pointer(SP)는 디버깅에서 굉장히 중요한 요소다. SP가 특정시점에 어떻게 갱신돼있는지를 파악하는게 ‘stack backtracing’ 디버깅법의 핵심이므로 잘 배워두자.
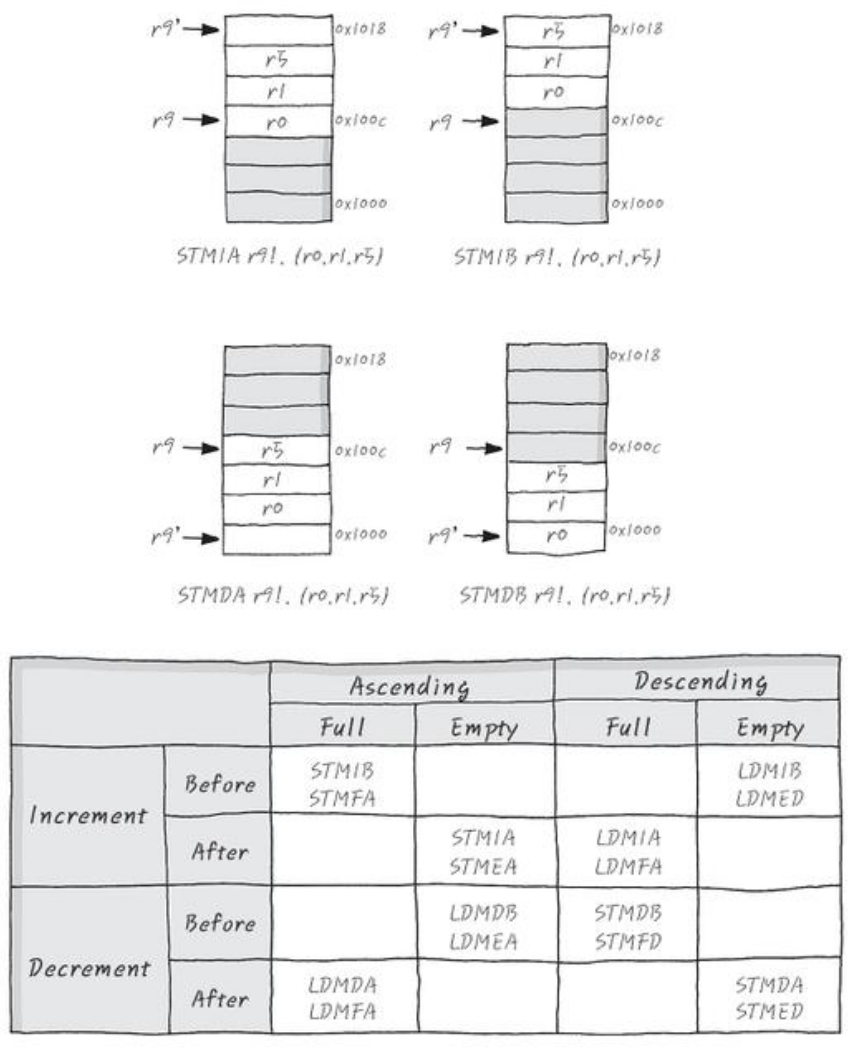
- Stack은 위로(하위 → 상위주소) 쌓이는지, 밑으로(상위 → 하위주소) 쌓이는지에 따라, 스택포인터(SP)가 유효한 데이터값을 가리키는지, 그 윗칸(또는 밑칸)을 가리키는지에 따라 경우의 수가 나뉘며 위 그림과 도표와 같다.
- 높은 주소를 향해 자라는 것은 ascending, 낮은 주소를 향해 자라는 것은 descending stack이라 부른다.
- SP가 방금 넣거나 뺀 data를 가리키면 full, 아니면 empty다.
- SP가 stack에 data를 넣거나 빼기 전에 먼저 변하면 before, 그 후에 변하면 after라고 부른다.
- 먼저, stack은 multiple register transfer addressing mode 명령어를 사용해 push, pop 한다.
- Push는 ‘ST’, pop은 ‘LD’ 2글자를 접두사로 쓴다.
- Multiple 이라는 뜻의 ‘M’을 쓴다.
- 위에서 봤던 경우의 수에 따라 접미사 2글자를 붙혀서 명령어를 완성한다.
- Increase - Before(IB), After(IA) : Data를 넣기 전/ 후에 SP를 증가. (하위 → 상위)
- Decrease - Before(DB), After(DA) : Data를 넣기 전/ 후에 SP를 감소. (상위 → 하위)
- Full - Ascending(FA), Descending(FD) : SP가 증가/ 감소하고 유효한 data를 가르킨다.
- Empty - Ascending(EA), Descending(ED) : SP가 증가/ 감소하고 빈칸을 가르킨다.
- 예시를 통해 명령어를 잘 이해해보자.
STMIA r9!, {r0, r1, r5}- R9가 가리키는 곳에 R0, R1, R5를 순서대로 push한다.
- Increase after이므로 stack이 하위 → 상위로 쌓이며 R0를 넣고 R9를 증가시키고, R1을 넣고 증가시키고, R5를 넣고 증가시킨다.
- 그러면 자연스럽게 R9는 빈칸을 가리키게 될 것이므로
STMIA == STMEA다. - 그래서 위 표에 두 명령어가 같은 칸에 있던 것이다.
STMDA r9!, {r0, r1, r5}- Decrease after이므로 이번에는 stack이 상위 → 하위로 쌓이며 R0를 넣고 R9가 감소하고, R1을 넣고 감소하고, R5를 넣고 감소한다.
- 자연스래 R9는 빈칸을 가리키므로
STMDA == STMED다.
- AAPCS에서는 full descending stack을 표준으로 정하고 있기 때문에
STMFD, LDMIA또는STMDB, LDMFA를 사용한다. - Stack의 LIFO 특성을 고려해
- push 할 때는 operand의 왼쪽부터 오른쪽으로 차례대로 넣고,
- pop 할 때는 operand의 오른쪽부터 왼쪽으로 차례대로 빼낸다.
1.2. Stack 실제 이용 - 메모리 덤프
- 메모리 덤프와 stack backtracing을 통해 실제로 어떤 방식으로 동작하는지 알아보자.
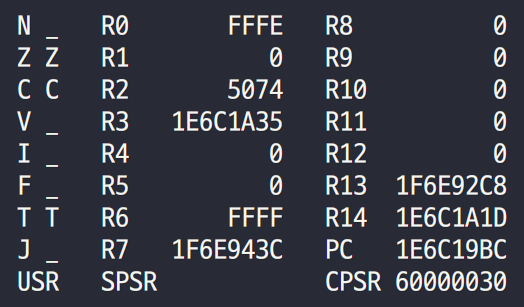
- 어느 순간에 ARM core를 halt 했을 때의 context가 위와 같다고 가정하자.
- CPSR의 LSB 5-bits가
10000이므로 USR mode고Tbit가 활성화된 것으로 보아 Thumb mode다.
- CPSR의 LSB 5-bits가
- PC가 가리키는 곳(
0x1E6C19BC)으로 이동해보자.
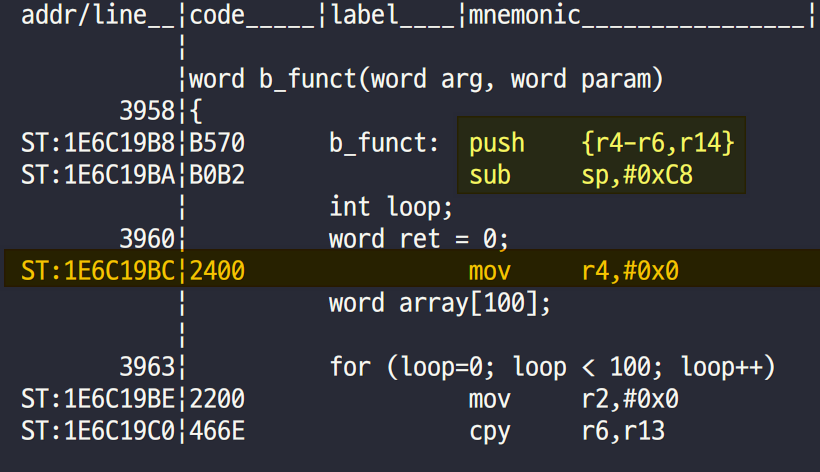
- ARM core는 MOV 명령어를 fetch 하고 있는 중이었음을 알 수 있다.
- Pipeline에 따라 2-cycle(Thumb니까 0x4) 위를 보니 stack에 R4, R5, R6, R14를 push하는 모습을 볼 수 있다.
- 컴파일러는 이 함수
b_funct()에서 scratch 레지스터인 R0~R3 이외에도 R4~R6가 사용됨을 파악해 미리 백업하는 것이다. SUB sp, #0xC8하는 이유는word array[100]이라는 지역변수 때문이다. Thumb이므로 1-word는 2-bytes일 것이고, 배열은 총 200-bytes를 차지하므로 SP를0xC8, 즉 10진수로 200만큼 내려서 미리 공간을 할당해준 것이다.
- 컴파일러는 이 함수
- R13(SP)를 보니
0x1F6E92C8을 가리키고 있으니, 배열 공간을 할당해주기 전 주소인0xC8만큼 더한 주소로 가보자.

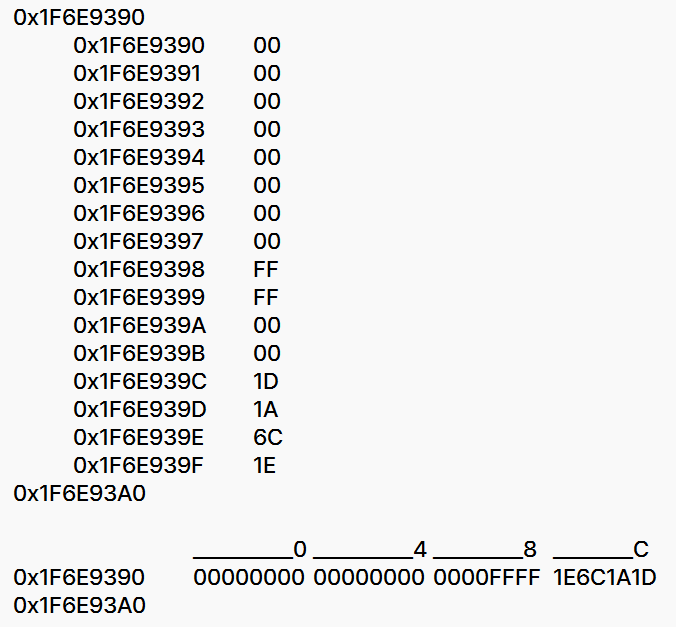
- 해당 주소로 이동하니, 순서대로 R4, R5, R6, LR이 저장돼있는 것을 확인할 수 있다.
- 물론 LR값은 context에서 확인할 수 있지만, 이렇게 stack backtracing을 하면 stack call history를 계속해서 탐색할 수 있기 때문에 다소 어렵게 돌아온 것이다.
- LR이
0x1E6C1A1D임을 확인했으므로 함수b_funct()를 호출한 line은 thumb 모드니까0x1을 빼주면0x1E6C1A1C라는 걸 알 수 있다. ([※] 이 부분이 조금 햇갈렸는데, ARM core는 홀수 주소 align을 Thumb, 짝수주소 align을 ARM mode로 구분한다고 이전부터 배우긴 했습니다.) - 이동해보니 함수
a_funct()에서b_funct()를 호출해서b명령어로 branch 했음을 확인할 수 있다. - 조금 위 line들을 보니
a_funct()진입 때push {r4, r14}를 하는 것을 확인할 수 있다.

- 앞에서 두 요소 R4와 R14를 push 했으므로 스택포인터 + 0x08를 덤프해보면 함수
a_funct()의 복귀주소 R14 ==0x1E6C1A59를 찾을 수 있다. - 이런 방식으로 계속 call history를 추적할 수 있다.
- 일반적으로 stack의 크기는 여러 시뮬레이션을 통해 프로그램을 실행할 때 가장 많이 스택을 사용하는 경우를 구한 뒤 그것보다 25% 크기를 추가한 값을 stack size로 설정하면 stack overflow를 예방할 수 있다.
2. 기타
[※] 이제 Chapter 5의 기타 내용인 ‘함수포인터’와 ‘Queue(큐)’만 간단하게 다루고 마무리 하겠습니다!
2.1. 함수 포인터
- 함수의 이름은 symbol이다. 계속 반복하지만, symbol은 링커가 인식 가능한 최소단위이며 고유주소를 가진다.
- 따라서 함수의 이름은 그 함수의 시작주소를 의미한다.
- 함수 포인터를 사용하면 같은 지점에서 언제든지 그때 그때 사정에 따라 다른 함수를 실행시킬 수 있다.
2.1.1. 함수 포인터 정의
- 함수 포인터는
자료형 (*함수 포인터 이름) (arguments)로 구성된다.- 이때 함수 포인터 이름을 감싸는 소괄호는 반드시 필요하다.
- 예를 들어
int *pFoo()와int (*pFoo)()가 있다고 생각해보자.- 전자는 그저 int형 포인터를 반환형으로 가지는 pFoo 함수일 뿐이고,
- 후자는 int형을 반환형으로 하는 pFoo 함수포인터다.
- 의미가 완전히 달라진다.
- 함수 포인터의 초기화는
=연산자와 함께 함수의 이름을 써주면 된다. 이때 소괄호는 절대 사용하지 않는다.pFoo = funct1이면 된다.pFoo = funct1()을 쓰면 funct1 함수를 호출하는 바보짓이 돼버린다.
2.1.2. 함수 포인터 배열
- [※] ‘함수 포인터’를 하나의 자료형이라고 자연스럽게 받아들이면 배열로도 활용할 수 있다는 걸 알 수 있습니다.
int (*pFoo[4]) (int, int) = { plus, minus, mul, div }라고 선언했다고 가정하자.pFoo[2](3, 5);라고 호출하면, 2번 index에 있는 함수 ‘mul’이 호출돼 3과 5의 곱인 15가 반환될 것이라 예상할 수 있다.for (int i = 0; i < 4; ++i) printf("%d\n", pFoo[i] (a, b));라고 쓰면 a와 b에 대한 사칙연산 결과를 알 수 있다.- 이런 기능을 활용하면 더더욱 아름답고 flexible한 SW를 개발할 수 있다.
2.1.3. 함수 포인터 응용 - Device driver
- 함수 포인터는 같은 기능을 하는 여러 가지 vendor의 device를 한꺼번에 지원하는 device driver를 개발할 때 특히 유용하다.
- Read & write이 가능한 어떤 device에 대한 구조체를 다음과 같이 정의 및 선언했다고 가정하자.
typedef struct {
const char *name;
void (*read) (byte *buffer, int count);
void (*write) (byte *buffer, int count);
} deviceType;
deviceType device1 = {"Device 1", device_read, device_write};
deviceType device2 = {"Device 2", device_read, device_write};
deviceType *deviceTarget;
// Vendor A에서 만든 device 사용자
deviceTarget = &device1;
(*deviceTarget->read)(buffer, count);
// Vendor B에서 만든 device 사용자
deviceTarget = &device2;
(*deviceTarget->read)(buffer, count); // 똑같이 쓸 수 있다!- 위와 같이 사용자 입장에서는 그저 ‘deviceTarget’에 자신이 사용하는 device의 주소만 넣어주면, vendor에 상관없이 똑같은 API를 사용할 수 있어서 편리하다.
2.1.4. 함수 포인터 완전 응용 - 원하는 주소로 branch
- 임베디드 SW를 개발할 때 우리는 특정 주소로 branch 해야 할 때가 생긴다. 이를 C언어로 어떻게 구현할 수 있을까?
- void형을 반환하는 함수 포인터를 사용하면 가능하다.
void (*pFoo)(void);
pFoo = (void (*)())0x7777;
(*pFoo)(); // 0x7777번지로 실행 flow가 옮겨간다 = branch
(*(void(*)()) 0x7777)(); // 이렇게 한 번에 쓸 수도 있다.- 이렇게 하면 억지로 PC값을 특정 주소로 바꿔 branch 하는 게 가능하다.
2.2. 큐(Queue)
[※] 기본적인 CS의 자료구조 내용이라 대부분의 내용은 생략하겠습니다. 중요한 점 두 가지만 정리하겠습니다.
- Kernel 또는 RTOS 속에서 사용되는 queue는 linked list로 구현되며 자주 사용된다.
- Doubly linked list를 이용해 queue를 구현하는 법을 알고있자.

임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.