
1. ARM Assembly
1.1. ADS vs GNU
- ADS랑 GNU는 둘 다 ARM 컴파일러를 제공한다.
- 두 컴파일러를 통해 나온 어셈블리는 문법과 구조가 거의 동일하지만, directive 등 세부적인 부분이 다르게 표현된다.
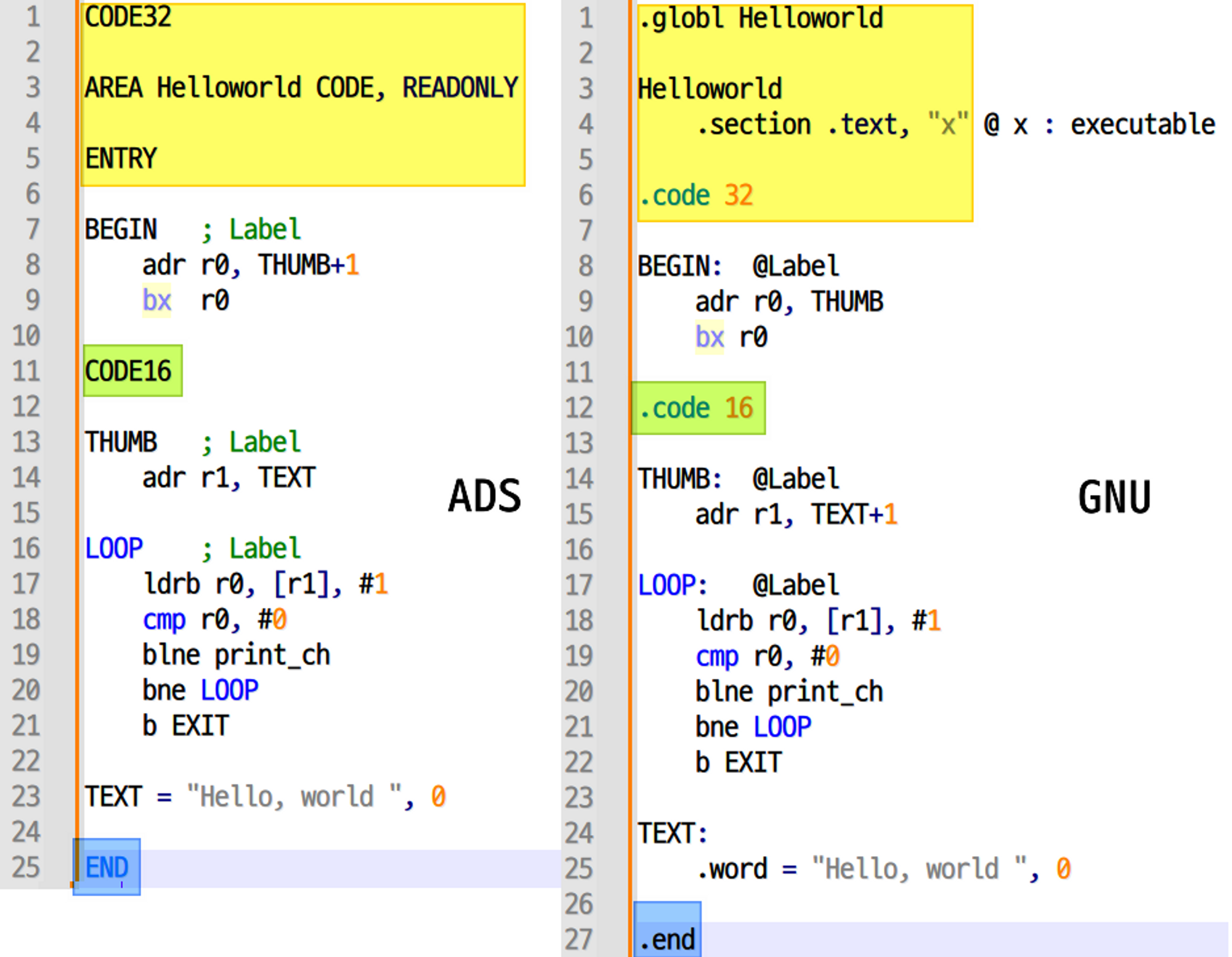
- 위 코드는 "Hello, world "라는 문자열을 출력하는 어셈블리 코드로, 왼쪽은 ADS를 오른쪽은 GNU 형식이다.
- 위 코드의 동작과정은 다음과 같다.
- R0에 THUMB symbol 시작주소 load한 뒤 jump한다. (bx 명령어니까 ARM -> THUMB로 바뀜)
- TEXT symbol 시작주소 + 1을 R1에 load한다.
- ARM은 THUMB instruction이든 ARM instruction이든 2Bytes 아니면 4bytes로 짝수로 align된다.
- 따라서 target address의 끝자리를 의도적으로 1을 더해 홀수로 만들어줘서
- ARM core에게 'Branch 할 target 주소의 끝이 홀수니까 THUMB mode로 branch 해줘'라고 전달할 수 있다.
- R1이 가리키는 주소에서 1-Byte를 읽어(한 글자를 읽어) R0에 load한다.
- R0값이 white space(공백)인지 비교한다.
- 아니라면, condition flag 'ne'에 해당하므로
- 'print_ch' 표준함수로 jump 후 한 글자 출력하고 돌아온다.
- 'LOOP' symbol 시작주소로 jump해서 3~5를 반복한다.
- 마침내 공백을 만났을 때
bEXIT로 프로그램을 종료한다.
- Label을 포함해 전체 구조는 동일한 것을 한 눈에 알 수 있고, directive나 comment 등 세부적인 문법이 다르다.
- 일단 ADS랑 GNU로 컴파일 된 어셈블리가 서로 다르게 생겼구나 정도만 알고 넘어가자.
- [※] 참고로 GNU ARM GCC로 위 어셈블리를 어셈블링하면 오류 납니다! 오류 해결 과정은 이 링크에서 설명했습니다.
1.2. ARM vs THUMB
- ARM assembly는 뼈대 명령어 뒤에 조건자/덧붙임 명령어를 더 붙여서 활용한다.
- ARM mode 명령어는 항상 조건부 실행이 가능하다. (∵ Branch 사용을 줄여 pipeline의 cancel 횟수를 줄여 CPU time을 증가시킬 수 있기 때문이다.)
- ARM mode 명령어는 조건자를 붙혀 CPSR의 flag bits를 보고 조건에 따라 명령 수행 여부를 결정한다.
- 조건자 리스트는 이 글의 맨마지막 부분에 그림으로 넣어놨다.
- 따로 조건자를 지정하지 않으면 'AL(Always)'로 조건 관계없이 무조건 실행한다.
- 예제
- BEQ LABEL = Z flag(=zero)가 1이면 LABEL symbol로 branch 한다.
- MOVCS R3, R5 = C flag(=carry)가 1이면 R3 ← R5 값을 옮긴다.
- MOVNE R2, R4 = Z flag가 0이면 R4 ← R2 값을 옮긴다.
- ADDVS R0, R1, R2 = V flag(=overflow)가 1이면 R0 ← R1 + R2 한다.
- 어셈블리가 다 그렇듯
명령어 Rd, {operands}구조로 뒤에서 앞으로 읽어서 연산을 수행한 결과를 Rd (Destination register)에 저장한다. (STR 명령어만 반대로 Rd가 뒤에 있다.) - 명령어는 Branch 관련(B, BL, BX, BLX), 데이터 처리관련 (MOV, CMP, ADD, SUB, MUL …), RISC(LDR, STR), pseudo(LDR, ADR), PSR(MRS, MSR), SWI, DCD directive(DCB(D,W,Q)), MAP directive(+FIELD), 덧붙임 명령어(!, S, ^) 등이 있는데 아는것들 제외하고 새로 배운것들만 정리해보자.
- 의사(Pseudo) 명령어
- LDR, ADR은 특별한 주소의 값을 load할 때 사용된다. 편의를 위해 문법에는 포함되지만, 실제로 내부 처리과정은 다른 방법을 추가로 사용하는 명령어다. 무슨 뜻이냐면,
LDR R0, Label이라고 사용하면, Label은 실제 주소가 아니라 symbol이기 때문에 컴파일러에 의해LDR R0, [PC, offset]꼴로 변경되고, offset 만큼 떨어진 곳에는DCD명령어를 사용해서 메모리 영역을 할당해준 뒤에 비로소 R0에 주소를 load하는 작업을 수행한다. - 따라서, 어셈블리로는 한 줄이지만, 내부적으로는 여러 줄의 코드를 실행하기 때문에 적재적소에 사용해야 한다.
- 의사 명령어 사용하는 이유는 솔직히 이 부분 잘 이해가 안 되서 다음에 다시 한 번 읽어보고 정리해야겠다.
- LDR, ADR은 특별한 주소의 값을 load할 때 사용된다. 편의를 위해 문법에는 포함되지만, 실제로 내부 처리과정은 다른 방법을 추가로 사용하는 명령어다. 무슨 뜻이냐면,
- PSR 명령어
- PSR을 제어하는 ARM instruction은 MRS와 MSR 2개밖에 없고 뒤에서 앞으로 값을 옮긴다고 외우면 편하다.
- MSR은 R에서 S로, 즉 ARM register에서 PSR로 값을 옮기는거고,
- MRS는 S에서 R로, PSR에서 ARM register로 값을 옮기는 거다.
- 보통 PSR 전체를 수정할 일은 잘 없다보니까 PSR 4bytes를 1bytes씩 쪼개서 mask를 만들어놨다.
- CPSR_f(flag), CPSR_s, CPSR_x, CPSR_c(control)
- 근데 _s랑 _x는 (ARM 버전에 따라 다르겠지만) 잘 안 쓰이고 f랑 c는 CPSR_cf 등으로 자주 쓰인다.
- PSR을 제어하는 ARM instruction은 MRS와 MSR 2개밖에 없고 뒤에서 앞으로 값을 옮긴다고 외우면 편하다.
- DCD 명령어(Directive)
- 크기에 따라 DCB(1Byte), DCW(2Bytes), DCD(4Bytes), DCQ(8Bytes)로 나뉜다.
- 특정한 메모리 주소에 data를 위한 메모리를 할당해 data를 선언하는 용도로 사용된다. (.word랑 거의 같은듯)
- DCB는 '='라는 연산자로, DCD는 '&'라는 연산자랑 똑같다.
- 덧붙임 명령어
- '!' : Write back 연산자라고 부르며 값을 갱신(update)하라는 명령어다.
- LDR Rd, [Rn, offset]! == Rn 값 + offset이 가리키는 주소에 있는 data를 Rd로 load하는 명령어다. '!' 연산자에 의해 Rn은 Rn + offset으로 갱신된다. (Rn += offset) 이를 pre-index 방식이라고 부른다.
- LDR Rd, Rn, offset == 위 예제와 똑같이 Rd에 Rn값 + offset 주소 내부 data를 load하고 Rn += offset으로 갱신된다. 이를 post-index 방식이라고 부르고 특이하게도
!연산자 없어도 Rn이 갱신된다.
- 'S' 와 '^' : 해당 명령어를 수행한 뒤 SPSR 값을 CPSR에 복사하는 명령어다. Previliege mode와 user mode 사이를 오고갈 때 MSR 명령어 쓰기 귀찮으니까 PC 복귀할 때 자동으로 CPSR도 복귀되도록 만들기 위한 용도로 사용한다.
- '!' : Write back 연산자라고 부르며 값을 갱신(update)하라는 명령어다.
- 의사(Pseudo) 명령어
1.3. Vaneer
- ARM은 ARM mode 명령어와 THUMB mode 명령어를 혼합해서 사용할 수 있다.
- Mode 간의 변경은
bx명령어를 사용하는게 대표적이다. (Branch 할 때 destination 주소가 홀수면 ARM→Thumb, 짝수면 Thumb → ARM으로 mode bit를 변경한다.) - 하지만, 개발자 입장에서는 현재 작성하는 소스코드가 메모리에 올라가서 어디에 어떤 주소가 할당될지 알 수 없기 때문에 목표 주소의 LSB는 커녕 bx 명령어도 제대로 사용할 수 없다.
- 'Vaneer(배니어)' 는 컴파일러가 자동으로 알아서 mode 전환이 필요할 때 mode 전환 코드를 삽입하는 기능을 말한다.
- 이 기능 덕분에 개발자는 ARM mode, Thumb mode 구분 없이 편하게 개발할 수 있다.
- (LDR, ADR 기능을 대신하는 역할도 한다고 하는데 나중에 좀 더 자세히 알아보자.)
1.4. Inline assembly
- 인라인 어셈블리를 사용하는 경우는 대표적으로 2가지다.
- ARM을 직접 다룰 때 (PSR 수정, CP15의 CR 수정 등)
- Register를 직접 다뤄 작업을 더 효율적으로 하고 싶을 때
- 인라인 어셈블리에서 C언어의 지역변수를 symbol처럼 직접 참조할 수 있다.
- AAPCS에 따르면 함수의 argument는 순서대로 r0, r1, r2...에 할당된다. 그러나 인라인 내부에서 사용되는 R0, R1과는 완전 별개로 관리할 수 있도록 미리 stack에 백업해둔 뒤 인라인 어셈블리 끝나면 복구해준다. 그러므로 인라인 어셈블리는 AAPCS랑은 상관이 없다.
- 인라인 어셈블리에는 여러 제약이 있다.
- 의사명령어(LDR, ADR) 사용 불가
- Label 및 branch 관련 명령어들 사용 불가
- PSR, CP15의 CR 등을 변경할 수는 있지만, 이로써 생기는 모든 문제는 개발자가 책임진다.
1.5. Co-processor assembly
- Co-processor 관련 명령어 종류는 세 가지로 분류할 수 있다.
- Co-processor 내부 register ↔ Co-processor 내부 register
- CDP (Co-processor Data oPeration) 명령어를 사용한다.
- CDP Co-processor번호, Co-processor명령어, CRd, CRn
- Co-proceesor 내부 register ↔ ARM register
- MRC, MCR 명령어
- 얘네 둘은 특이하게 뒤에 오는 operand에 고정된게 많다.
- MCR Co-processor번호, 0 고정, Rd, Cn, C0 고정, 0 고정 꼴이다.
- Co-proceesor 내부 register ↔ Memory
- LDC, STC 명령어
- Co-processor 내부 register ↔ Co-processor 내부 register
2. Exception
2.1. Return after handling exception
[※] <임베디드 스케치> 요약 자료 중 이 링크의 3.3절에서 다룬 내용입니다. 본문은 Thumb 까지 포함해서 좀 더 내용이 많습니다. 위 링크의 글과 함께 보시면 공부에 더 도움이 될 것입니다.
- 각 exception 및 abortion이 pipeline 상에서 발생하는 타이밍은 다음과 같다.
- Undefined exception은 decode 단계
- SWI는 decode 단계
- Prefetch abort는 fetch 단계
- Data abort는 execution 단계
- IRQ/FIQ는 execution 단계
- 이 타이밍을 이해하는 것이 디버깅할 때 중요하므로 꼭 알아두고 외워두자.
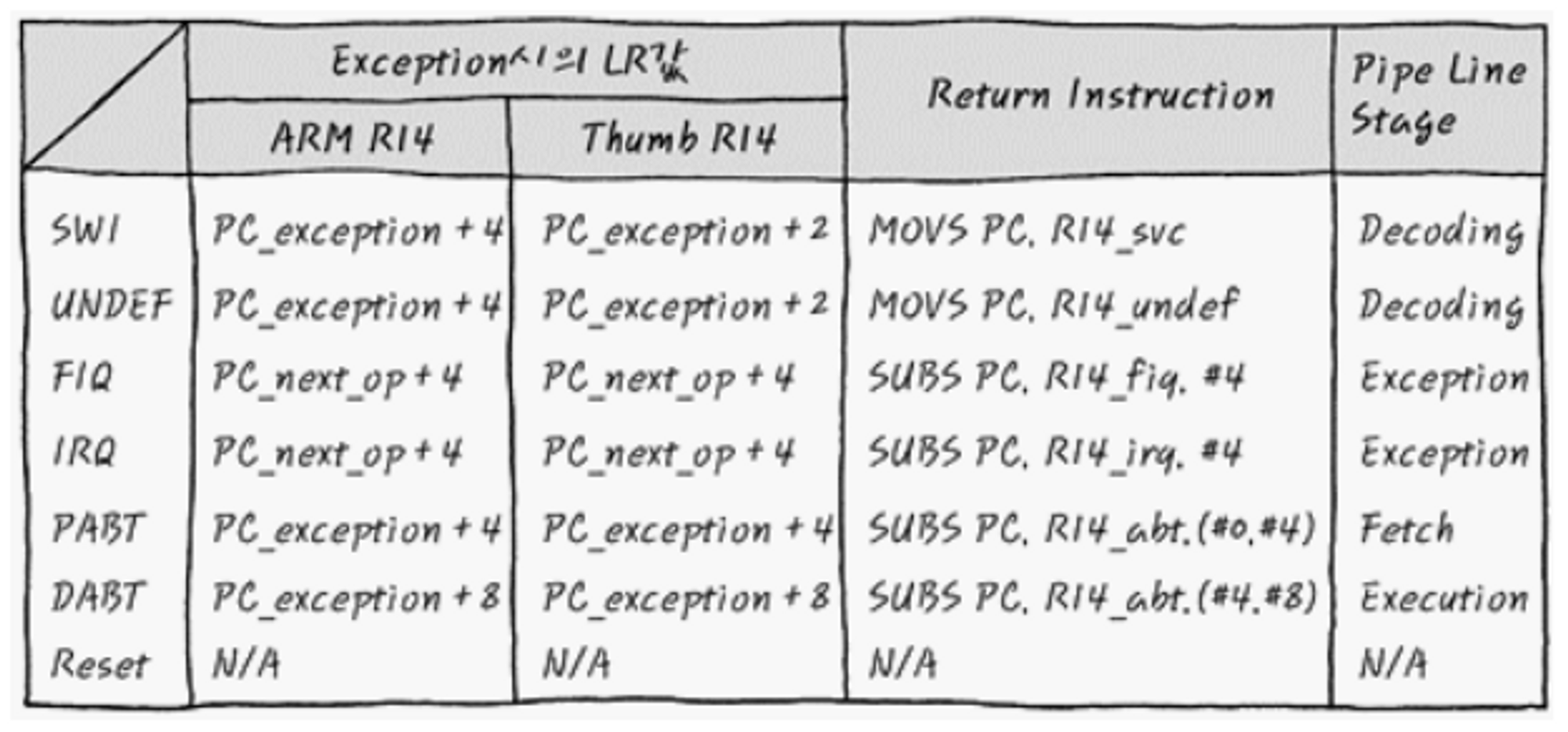
- Exception이 발생한 뒤 handler로 처리해줬다고 가정하자. 복귀 주소는 어떻게 결정해야 할까?
- Reset Exception (Reset Handler)
- Reset은 HW적인 원인으로 reset이 되는 경우가 많다.
- 이런 경우 실행중인 SW와는 연관이 없기 때문에 언제든지 발생할 수 있고, SW 및 context의 상황을 봐가면서 reset이 발생하지 않는다. 즉, 현재 context에 대한 정보는 얼마든지 사라질 수 있어서 디버깅이 매우 어렵다.
- Undefined exception (UND handler)
- 어떤 instruction의 opcode가 ARM core는 이해할 수 없는 것이라는 걸 알 수 있는 단계는 decode 단계다.
- UND exception은 decode 단계에서 발생하므로 이때 PC는 한 개 명령어 밑인
+0x4주소를 가리키고 있으며 fetch 단계를 수행하고 있을 것이다. (Thumb 모드라면+0x2겠다.) - 따라서 복귀할 주소 R14에는 PC값을 그대로 집어넣으면 된다. (왜냐하면, Handler 수행 후 복귀할 주소는 exception이 발생한 주소의 다음 주소부터 시작해야 이어서 실행 가능하니까.)
- Prefetch abortion (PABT Handler)
- Prefetch는 이름대로 fetch 단계에서 발생하기 때문에 PC는 abortion이 발생한 명령어의 주소를 가리킨다.
- 이때 ARM은 친절 서비스를 발휘해 R14에 PC + 1-cycle 주소를 저장해준다.
- [※] <임베디드 스케치>에서는 PABT가 fetch와 decode 사이 단계에서 발생하기 때문에 PC가 +1-cycle 아래를 가리키고 있다고 설명하고 있습니다. 결과적으로는 R14에 들어가는 값이 똑같기는 하지만, 두 전문가의 설명하는 방식이 다르니 이 부분은 주의해서 받아들입시다.
- 따라서 개발자는 다시 PABT line부터 재실행하고 싶으면 LR - 1-cycle로 돌아가면 되고, PABT line 다음 명령어부터 실행하고 싶다면 UND 때처럼 그냥 LR로 돌아가면 된다.
- Data abortion (DABT Handler)
- Data abortion은 execute 단계에서 발생하므로 PC는 +2-cycle 밑을 가리킨다.
- 이번에는 ARM이 친절 서비스를 발휘하지 않는다!
- 따라서 R14에는 PC값, abortion이 발생한 곳 + 2-cycle이 저장된다.
- 그러므로 재실행하고 싶다면 LR - 2-cycle로 돌아가야 하고, 이어서 실행하고 싶다면 LR - 1-cycle로 돌아가야 한다.
- SWI
- SWI는 system call 같이 의도적으로 kernel 및 system 자원을 활용하기 위해 의도적으로 SW적으로 발생시키는 interrupt이므로 decode 단계에서 ARM core가 인식하자마자 SVC mode로 진입하게 된다.
- 따라서 UND와 똑같이 PC는 + 1-cycle 주소가 들어있어서 복귀할 때는 LR로 그대로 가면 된다.
- IRQ & FIQ
- IRQ와 FIQ는 SWI와 달리 HW적으로 발생하는 interrupt다.
- Abortion이나 reset 같은 오류라기 보다는 이미 처리할 준비가 된 exception이므로 현재 실행하던 명령어 까지는 수행하도록 해준다.
- 따라서 execute 단계에서 발생한다고 봐도 과언이 아니며 PC는 +
0x8아래를 가리킨다. - 이번에도 ARM은 친절서비스를 발휘하지 않으므로 handler 처리 이후에 복귀할 때는 LR - 0x4을 해주면 이어서 명령어를 수행할 수 있다.
- 주의할 점! 이번에는 위와 다르게 ‘cycle’로 표현하지 않고
0x4, 0x8같은 구체적인 byte를 사용했다. 왜냐하면, ARM mode든 Thumb 모드는 무조건 LR에abortion 발생 주소 + #4 + 1-cycle을 저장하기 때문이다! 정리하자면,- ARM mode는 LR에 abortion 발생 주소 +
0x8이 저장되고, - Thumb mode는 LR에 abortion 발생 주소 +
0x6이 저장된다. - 따라서 둘 다 복귀 후 이어서 실행하고 싶다면
LR - 0x4를 해줘야 하는 것이다.
- ARM mode는 LR에 abortion 발생 주소 +
- Reset Exception (Reset Handler)
- 복귀할 때는 S 접미사를 적극 활용하자. (S 접미사 못 쓰는 multiple register transfer 명령어는 ^ 접미사를 사용하자.)
SUBS PC, R14, #4== LR값 - 0x4한 값을 PC에 넣고, SPSR을 CPSR에 넣는다.
2.2. Handling exception (+SWI)

- Exception이 발생하면 exception vector table로 branch한 후 대응하는 handler로 jump 한다.
- Exception vector table에서 FIQ가 가장 밑에 있는 이유
- FIQ는 빠르게 처리해줘야 하는 interrupt이므로 branch도 사치다.
- 따라서 vector table 가장 밑에 위치한 뒤 바로 이어서 (0x1C) handler를 작성해주면, branch 연산 할 시간을 아끼고 바로 처리해줄 수 있기 때문에 가장 아래에 있다.
- Exception vector table에서 FIQ가 가장 밑에 있는 이유
- 각 handler에는 어떤 내용이 포함돼있을까?
- Reset handler는 이후 더 자세하게 다루니까 일단 스킵한다.
- Undefined handler
- Undefined exception이 나오는 원인은 크게 두 가지겠다. 하나는 실제로 code 영역에 corruption이 발생헀거나 다른 하나는 의도적으로 개발자가 어떤 목적을 위해 exception을 발생시켰거나.
- Co-processor를 제어하고 싶을 때나 HW디버거의 어떤 명령을 사용하고 싶거나 등등
- UND 모드는 R13, R14, SPSR 3개만 갖고 있으니까 나중에 복귀하기 위해서 R0~R12랑 PC값을 백업해둬야 한다.
- Prefetch abort handler
- Demand loading(애플리케이션 전체를 메모리에 올리기에는 메모리 또는 NOR 플래시 용량이 작을 때 프로그램에 필요한 일정 부분만 로드하는 방식)에 문제가 생겨서 발생하기도 한다.
- 개발자가 필요한 정보를 얻을 수 있도록 최대한 요란하게 많은 정보를 제공하고, 디버깅용 코드를 삽입한다.
- ABT 모드도 R13, R14, SPSR 3개만 갖고 있으니까 나중에 복귀하기 위해서 R0~R12랑 PC값을 백업해둬야 한다.
- Data abort handler
- alignment fault, permission fault 등으로 발생할 수 있으며 오류를 수정해주는 코드를 삽입한다.
- Data abort도 ABT 모드니까 위 prefetch abort 때처럼 R0~R12, PC 백업해야 한다.
- IRQ/FIQ handler
- IRQ는 R0~R12, PC 백업해야 하고, FIQ는 R8~R14가 자기꺼라 R0~R7, PC만 백업하면 된다.
- SWI handler
- SWI는 UND랑 똑같이 처리해주면 된다.
- 근데 사실 interrupt 라는게 언제 터질지 알 수 없는건데 SWI가 정확히 뭐길래 아무때나 interrupt를 건다는걸까?
- SW적으로 exception을 걸 수 있다는 건 넓은 뜻에서 하는 말이고 주 사용목적은 USR 모드에서 SVC 모드로 바뀌어 시스템 자원을 사용하기 위해 사용한다.
- System call
- Semi-hosting (For debugging?)
- SWI는 이름 그대로
SWI라는 명령어가 있다. SWI라는 opcode를 발견 즉시 USR에서 SVC로 바뀌고 vector table로 넘어가서 SWI handler로 jump하게 된다.SWI명령어의 구조를 MSB부터 살펴보면,- [31:28]의 4-bit (condition bits): EQ, NE 같은 조건자를 삽입하는 곳이다.
- [27:24]의 4-bit (opcode): SWI의 opcode를 나타내며
0x1111이다. - 나머지 24-bit: Handler에 parameter로 넘겨줄 값으로 사용할 수 있는 곳이다.
- 우리는 SWI instruction의 위치가
LR - 1-cycle이라는 것을 알고 있다. - 이 정보를 활용하면 정말 재밌게도 AAPCS를 활용해서 handler의 parameter로 값을 넘겨줄 수 있다!
- 그리고 switch-case문을 사용해서 하나의 handler로 다양한 일을 할 수 있다!
- 예를 들어
SWI 0x123456이라는 명령어를 ARM core가 decode 했다고 가정하자.- 시스템적으로 약속된 절차를 수행한다. (CPSR값 SPSR에 백업, 레지스터 백업, PC값 LR에 백업 등)
LDR R0, [R14, #-4]== SWI가 등장한 line의 instruction을 R0에 저장한다.BIC R0, R0, #0xFF000000==BIC는 operand의 보수값이랑 AND 연산하는 명령어다. 따라서R0 & 0x00FFFFFF를 수행한다.- R0에는 SWI instruction의 LSB 24-bit가 저장된다.
- AAPCS에 의해 handler의 parameter는 R0부터 할당되므로 SWI handler의 parameter는 R0, 즉 LSB 24bits 값인 0x123456을 가지게 된다.
- Switch-case 문을 활용하면, 하나의 handler에서 parameter 값에 따라 다양한 일을 수행할 수 있게된다.
- 예를 들어
- SWI handler의 parameter를 전달하는 방법을 아래 코드에서 살펴볼 수 있다.
- SW적으로 exception을 걸 수 있다는 건 넓은 뜻에서 하는 말이고 주 사용목적은 USR 모드에서 SVC 모드로 바뀌어 시스템 자원을 사용하기 위해 사용한다.
// test1.c
void SWI_func() {
SWI_Exception();
}
// test2.s
...
SWI_Excpetion: @label
SWI 0x123456
...
// startup.s
...
SWI_Handler
STMFD SP!, {LR}
LDR R0, [LR, #-4]
BIC R0, R0, 0xFF000000
BL SWI_C_Handler
LDMFD SP!, {LR}
...
// test1.c
...
__swi(0x121212) void UART_OUT(void);
__swi(0x987654) void BUTTON_OUT(void);
void SWI_C_Handler(int option) {
switch(option) {
case 0x121212:
UART_MESSAGE("UART Interrupt! 0x121212");
break;
case 0x123456:
LCD_MESSAGE("LCD Interrupt! 0x123456");
break;
case 0x987654;
BUTTON_MESSAGE("Button pushed! 0x987654");
break;
}
}
...3. Bootloader
3.1. Memory map
- 우리는 앞서([※] Chapter 3의 마지막 절 scatter loading(linker script) 부분이요!) ELF를 load view, execution view로 나눠서 각 메모리 영역이 ROM과 RAM에 어떻게 배치돼 저장되는지 배웠다.
- NOR 플래시를 사용한다면, RO & RW는 NOR에, RW & ZI는 메모리에 저장돼야 하니까 RW를 로드해주는 작업이 필요하고
- NAND 플래시를 사용한다면 RO & RW & ZI 모두 메모리에 저장돼야 하니까 RO & RW를 로드해주는 작업이 필요하다.
- 이번에는 bootloader의 관점에서 두 가지 경우의 memory model에서 bootloader가 어떤 작업을 수행하는지 알아보자.
- Default memory model
- 소형/단순 임베디드 시스템의 경우 scatter loading이 필요하지 않거나 사용하지 않는다.
- 이 경우 memory map을 링커가 자동으로 생성하며 이를 ‘default memory model’이라고 부른다.
- 링커가 각 영역(RO → RW → ZI)의 시작주소와 마지막주소에 대한 symbol을 자동으로 생성한다.
image$$RO$$base,image$$RO$$limit,image$$ZI$$base등 symbol이 생성된다.
- 반복해서 말하지만, symbol은 링커가 식별할 수 있는, 절대주소를 가지는 최소 단위를 의미한다.
- Bootloader는 링커가 자동으로 잡아준 ‘ZI영역’의 시작주소(base)와 크기(limit 또는 length) 정보를 위 symbol을 참조해서 알 수 있다. ZI영역 0 초기화 과정은 다음과 같다.
- Default memory model
r0, = |image$$ZI$$Base|
r1, = |image$$ZI$$Limit|
r2, = 0
BEGIN:
str r2, [r0], #4 ; post-index, r0 += 4 해가면서 0으로 write함.
cmp r0, r1 ; Base부터 Limit까지
bne BEGIN ; 반복-
User memory model
- 상용 임베디드 시스템의 경우 개발자가 scatter loading을 작성해서 link할 때 사용한다.
- ADS manual의 scatter loading 예제를 살펴보며 링커와 bootloader가 어떤 작업을 수행하는지 살펴보자.
ROM_1 0x0000 { ROM_1 0x0000 { object1.o (+RO) } DRAM 0x18000 { object1.o (+RW) object2.o (+ZI) } } ROM_2 0x4000 { ROM_2 0x4000 { object2.o (+RO) } SRAM 0x8000 { object1.o (+ZI) object2.o (+RW) } }- 두 가지 object file에 대해 load view 2개와 각각에 대한 execution view가 정의된 것을 확인할 수 있다.
- 링커는 위 scatter loading file을 보면 아래와 같은 symbol을 자동으로 생성해준다. (Default memory model 때와 같지만, 생성되는 symbol의 이름에 개발자가 명시한 이름이 포함되는 것을 확인할 수 있다.)
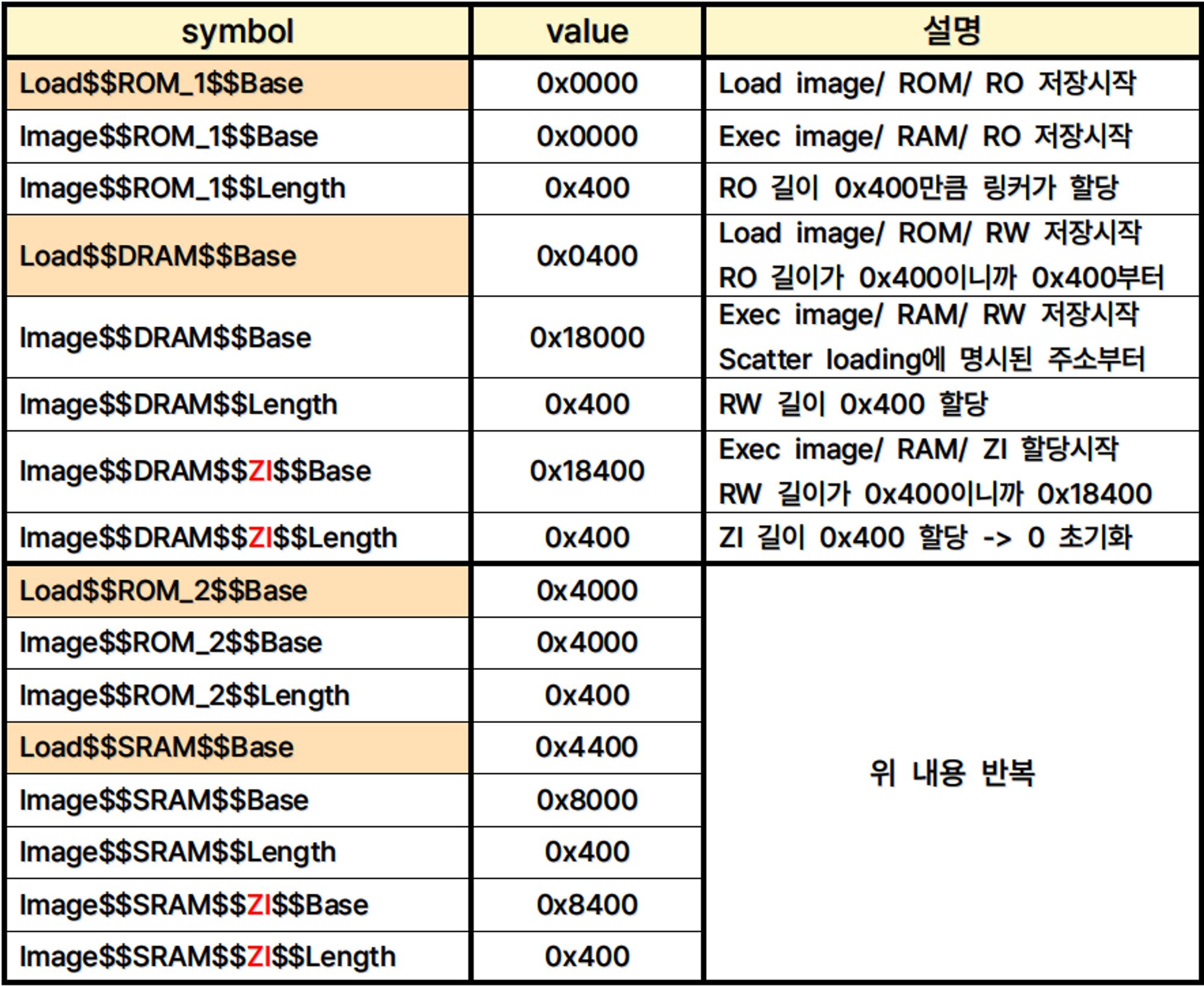
- Q. Load view에는 ‘Base’만 있고 ‘Length’가 없는 이유
- Load view든, execution view든 저장되는 장소(ROW vs RAM)와 시작주소가 달라질 뿐이지, 크기 정보는 같다.
- 따라서 execution view에서 명시되는 length가 곧 load view의 length와 같다.
- Q. Load view에서 ‘ZI영역’을 명시하지 않는 이유
- ZI영역은 초기값이 없는 global symbol을 위한 공간이다.
- 따라서 ROM에 저장할 필요가 없이 시작주소, 길이정보만 가지고 RAM에 영역을 할당한 뒤 위에서 했듯 0으로 초기화하는 작업만 해주면 되기 때문에 load view에는 따로 명시하지 않는다.
- 이때 bootloader는 load view에서 execution view로 각 영역을 copy한 후 initialize 해주는 작업을 수행한다.
- 링커가 생성해주는 symbol들은 ‘C 소스파일’에서는 접근할 수 없으나 어셈블리에서는 접근할 수 있다.
- 따라서 어셈블리 파일에서 DCD 명령어와 label을 활용해 주소를 할당한 뒤 C 파일에서 extern 선언해 사용한다.
// startup.s -- DCD 명령어와 label을 사용해서 주소를 할당해준다.
...
LOAD__SRAM__BASE: @label
DCD |Load$$SRAM$$Base|
IMAGE__SRAM__BASE:
DCD |Image$$SRAM$$Base|
IMAGE__SRAM__LENGTH:
DCD |Image$$SRAM$$Length|
IMAGE__SRAM__ZI__BASE:
DCD |Image$$SRAM$$ZI$$Base|
IMAGE__SRAM__ZI__LENGTH:
DCD |Image$$SRAM$$ZI$$Length|
...
// bootloader.c
extern byte *LOAD__SRAM__BASE;
extern byte *IMAGE__SRAM__BASE;
extern byte *IMAGE__SRAM__LENGTH;
extern byte *IMAGE__SRAM__ZI_BASE;
extern byte *IMAGE__SRAM__ZI_BASE; // 이렇게 Label을 extern으로 가져올 수 있다.
void copy_RW_area() {
dword *end_point = (dword *) ((dword)IMAGE__SRAM__BASE + (dword)IMAGE_SRAM_LENGTH);
for (src = (dword *)LOAD__SRAM__BASE,
dst = (dword *)IMAGE__SRAM__BASE; dst < end_point; src++, dst++) *dst = *src;
} // Load view의 RW영역을 Execution view의 RW영역으로 붙혀넣고 있다.3.2. Reset handler ~ main
- ARM core가 탑재된 임베디드 시스템은 전원 인가됨과 즉시 reset exception이 발생해 SVC mode로 exception vector로 jump해 reset handler로 이동한다.
- [※] Reset handler가 하는 일은 bootloader와 거의 같습니다. 실제로 둘이 같은건지 아닌지는 설명돼있지 않아 모르겠습니다. Bootloader는 internal-RAM에 있으니까, vector table의 reset handler가 iRAM에 있는 bootloader의 시작주소를 가리키고 있다고 가정하면 말이 되는거 같기도 합니다 ㅎㅎㅎ…
- Reset handler가 하는 일은 다음과 같다.
- IRQ/FIQ disable
- PLL setting (Watchdog timer, System clock 등 HW block들의 clock 설정)
- MCU의 pin들 setting
- Memory controller 초기화
- 각 mode의 stack setting 및 초기화
- Memory map setting - NOR의 경우 RW load, NAND의 경우 RO & RW load하고 ZI영역 할당 및 0 초기화
main()함수 호출하기 위한__rt_entry()호출
__rt_entry()에서는 C 라이브러리에서 사용하는 stack과 heap 영역을 잡고, 라이브러리 함수 및 내부에서 사용하는 static data들을 초기화한 뒤 main() 함수를 호출한다.- 모든 애플리케이션은 __main()에서 시작하는 게 약속이다. 하지만, 우리의 ARM 임베디드 시스템은 reset handler가 가장 먼저 실행돼 bootloader가 작업을 하도록 만들어야 하므로 reset handler를 entry point 즉 __main() 역할을 하게끔 만들어야 한다. 따라서
EXPORT __main과EXPORT _main두 문장을 가장 먼저 쓴 뒤 vector table을__main과_mainLabel로 씌워__main()역할을 대신하는 entry point로 지정한다.
EXPORT __main
EXPORT _main
AREA INIT_VECTOR, CODE, READONLY
CODE32
__main ; __main symbol을 label로 만들어준다.
_main ; __main symbol이 없으면 _main을 찾기 때문에 label 2개 쓴다.
ENTRY
B Reset_handler
B Undefined_handler
...
임베디드 시스템 공학자를 지망하는 컴퓨터공학+전자공학 복수전공 학부생입니다. 타인의 피드백을 수용하고 숙고하고 대응하며 자극과 반응 사이의 간격을 늘리며 스스로 반응을 컨트롤 할 수 있는 주도적인 사람이 되는 것이 저의 20대의 목표입니다.