1. Abstraction in Software Design
Assembly-level abstraction
- 프로세서가 동작하는 방식을 그대로 표현해야해서 사람이 쉽게 이해할 수 있는 표현이 아님
⇒ 효율적인 코딩 가능 - 프로세서에 대한 상당한 지식이 필요하고 개발 시간도 길다
High-level languages
- 컴파일러가 코드를 얼마나 효과적으로 어셈블리 레벨로 바꿨는지가 성능을 결정
⇒ 프로세서의 최대 성능을 끌어내기 어렵 - 프로세서와 관계 없이 언어의 syntax가 같다
⇒ 다른 프로세서에서도 같은 code로 실행 가능(어셈블리는 프로세서마다 코드가 달라짐)
★ 빠른 coding 및 debugging 가능
전체적으로 high level 코딩 후 maximum performance가 필요한 부분만 assembly code를 사용해야함
2. Data Types
ARM의 data type
-
Number ranges : 0 ~ FFFFFFFF
- unsigned integer의 경우 c flag가 wrong result인지 아닌지를 보여줌
- signed integer의 경우 2's complement(-2^31 ~ 2^31-1 : 80000000 ~ 7FFFFFFF)
- signed int의 경우 V flag가 overflow 됐는지 안 됐는지 보여줌
-
Other number sizes
- signed/unsigned bytes
- double word using SW
- 64bit addition(r3:r2 = r3:r2 + r1:r0)
ADDS r2, r2, r0 ;아래 word 먼저 더하기 (carry도 set해주기) ADC r3, r3, r1 ;위 word 더하기 (carry와 함께) -
Real number
- coprocessor를 이용해서 계산(Floating Point arithmetic unit)
- SW emulation (함수 만들어 → UIT 이용)
-
ASCII code
- 7bit standard code, printable characters + control codes(LF, CR)
- 8 bit : Extended ASCII : 그래픽이랑 특별한 characters
- 16 bit : 다양한 언어 표현 가능
- ARM은 ASCII code와 같은 character를 unsigned byte 형태로 지원함.
ANSI C basic data types
- signed and unsigned characters (>=8)
- signed and unsigned short integers (>=16), integers(>16, 32 for ARM), long integers(>= 32)
- Floating point(32bit), double(64bit), long double(128bit) → 프로세서와 컴파일러에 따라 다름
ANSI C derived data types
- array : 같은 타입의 데이터가 모여 있는 것
- function : 특정 타입의 데이터를 return
- 각각의 모든 data type에 대해 메모리 따로 따로 지정
- pointer : unsigned int와 다른 data type
- Unions : 다양한 data type 모을 수 있음. (메모리 할당은 data size가 가장 큰 data type을 기준으로 함.)
ARM C
- character : byte boundary → addr 제한 없음
- short int : even addr
- 그 외 : word boundary → addr 4의 배수
- 구조 : word boundary로 시작 → closely packed
ARM Architecture Support for C data types
- ARM integer code는 아래의 data type들을 지원함
- Signed 32 bit integers(80000000 ~ 7FFFFFFF)- Unsigned 32 bit integers(0 ~ FFFFFFFF)
- Unsigned bytes ⇒ C의 integer, long integer, unsigned character types 표현 가능
- C and V flag ⇒ unsigned와 signed의 연산 오류 확인
- Multiple words operation : 64 bit 덧셈 ⇒ 2개의 32 bit 연산과 C flag 연산
- Pointer 표현 ⇒ native ARM addr
- ARM addressing modes ⇒ array and structure 표현 가능
- ★Floating-point : UIT or Coprocessor 사용하면 표현 가능
3. Floating point data types
Single precision format

Special values in IEEE754
- zero : zero exponent and fraction, either sign(+0, -0)
- +-무한대 : maximum exponent, and zero fraction
- NaN : maximum exponent, and nonzero fraction
- Quiet NaN : fraction bit의 MSB가 1인 경우
⇒ 정상적인 표현 범위를 벗어나도 계속 연산을 진행하는 경우 - Signaling NaN : fraction bit의 MSB가 0인 경우
⇒ NaN이 발생하면 별도의 신호를 내보내주는 동작 진행하여 불필요한 연산을 막아줌
- Quiet NaN : fraction bit의 MSB가 1인 경우
- Deormalized number (작은 숫자를 표현하고 싶을 때)
- exponent가 -126인 경우
- 1.frac으로 표현할 수 있는 가장 작은 수 : 1.frac *2^(-125)
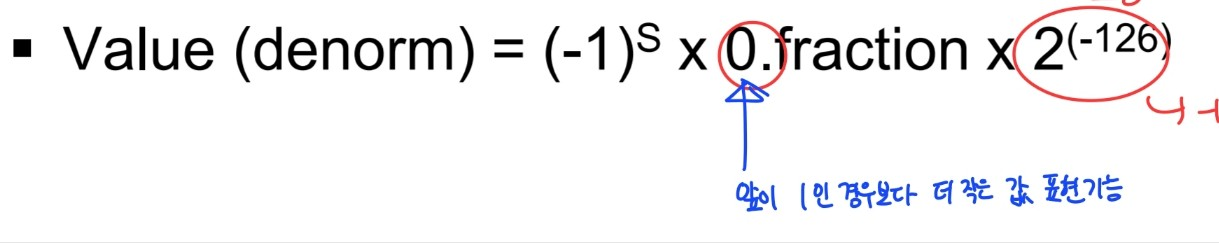
5. Expressions
- unsigned arithmetic on n-bit integer in C
- modulo 2^n operation : carry 무시 → overflow 없음
- 나눗셈과 나머지 연산의 경우 여러개의 ARM 명령어로 구성
- Register use : 아래의 register 개수와의 trade off 존재
- operand 값을 위한 register
- 중간값을 위한 register
- 주소 값을 위한 register
⇒ 이 register들을 어떤 비율로 잘 유지하느냐가 중요함
- 3-addr instruction format
- 어떻게 register를 재사용하고 유지할건지에 대해 flexibility를 줌
- operands 접근
- register : 즉시 접근 가능
- stack : single LDR(r13 + offset)
- constant : single LDR (pc relative addressing)
- local 변수 : stack (stack pointer relative LDR)
- global 변수 : static area (static base relative addressing)
- Pointer arithmetic
- 주소 1 word 증가 경우
int *p;
p = p + 1; //-> 주소 p는 4 증가ADD r0, r0, #4 ;pointer : r0- 주소 i word 증가 경우
int *p;
int i = 4;
p = p + i; //-> 주소 p는 i*4 증가ADD r0, r0, r1, LSL #2 ;scale r1 to int- Arrays : pointer로 표현 가능
- int a[10]; a는 array의 첫번째 원소의 주소
- a[i]를 가리키고 싶다면 *(a+i)
6. conditional statements
- If...else
if (a>b) c=a; else c=b;CMP r0, r1 ;if(a>b)
MOVGT r2, r0 ;c=a
MOVLE r2, r1 ;c=b- If...else 안에서 실행되는게 길다면 branch 이용
- branch는 3 cycles
CMP r0, r1 ;if(a>b)
BLE else ;a<=b라면 else로 넘어가
MOV r2, r0 ;c=a
B endif ;if끝나면 빠져나와
else MOV r2, r1 ;else c=b
endif ...- Switches
switch (a) {
case 0 : *b =0; break;
case 1 : if (c>100) *b=0;
else *b=3; break;
case 2 : *b =1; break;
case 3 : break;
case 4 : *b =2; break;
};on entry a1=0, a2=3, v2=switch expression(a)
CMP v2, #4 ;overrun 여부 판단
ADDLS pc, pc, v2, LSL #2 ;overrun 아니라면 add to r15 (+8)
LDMDB fp, {v1,v2,fp,sp,pc} ;if not ok, return
B L0 ;case 0
B L1 ;case 1
B L2 ;case 2
LDMDB fp, {v1,v2,fp,sp,pc} ;case 3 (return)
MOV a1, #2 ;case 4 메모리에 상수 저장하고 싶으면 레지스터 거쳐야함
STR a1, [v1] ;v1이 가리키는 주소에 2 넣어
LDMDB fp, {v1,v2,fp,sp,pc} ;return
L0 STR a1, [v1] ;v1이 가리키는 주소에 0 넣어
LDMDB fp, {v1,v2,fp,sp,pc} ;return
L1 LDR a3, c_addr ;a3에 c가 있는 주소 넣어
LDR a3, [a3] ;a3에 c 넣어
CMP a3, #&64 ;c>100?
STRLE a2, [v1] ;no : v1이 가리키는 주소에 3 넣어
STRGT a1, [v1] ;yes : v1이 가리키는 주소에 0 넣어
LDMDB fp, {v1,v2,fp,sp,pc} ;return
c_addr DCD <c의 주소>
L2 MOV a1, #1 ;case 2 메모리에 상수 저장하고 싶으면 레지스터 거쳐야함
STR a1, [v1] ;v1이 가리키는 주소에 1 넣어
LDMDB fp, {v1,v2,fp,sp,pc} ;returnLoops
For문
for (int i=0; i<10; i++){a(i)=0} MOV r1, #0 ;a[i]에 넣을 값
ADR r2, a[0] ;r2 -> a[0]
MOV r0, #0 ;i=0
LOOP CMP r0, #10 ;i<10?
BGE EXIT ;i가 10보다 크거나 같으면 반복문 빠져나와
STR r1, [r2, r0, LSL #2] ;a[i]=0
ADD r0, r0, #1 ;i++
B LOOP
EXITWhile문

8. Functions and procedures
- 함수가 작아야 테스트 하기 좋아
- 함수는 계층적인 구조를 이루고 있어야 해
- Leaf routine
- 계층의 가장 낮은 함수- library나 system 함수의 경우 보이진 않지만 진짜 leaf임
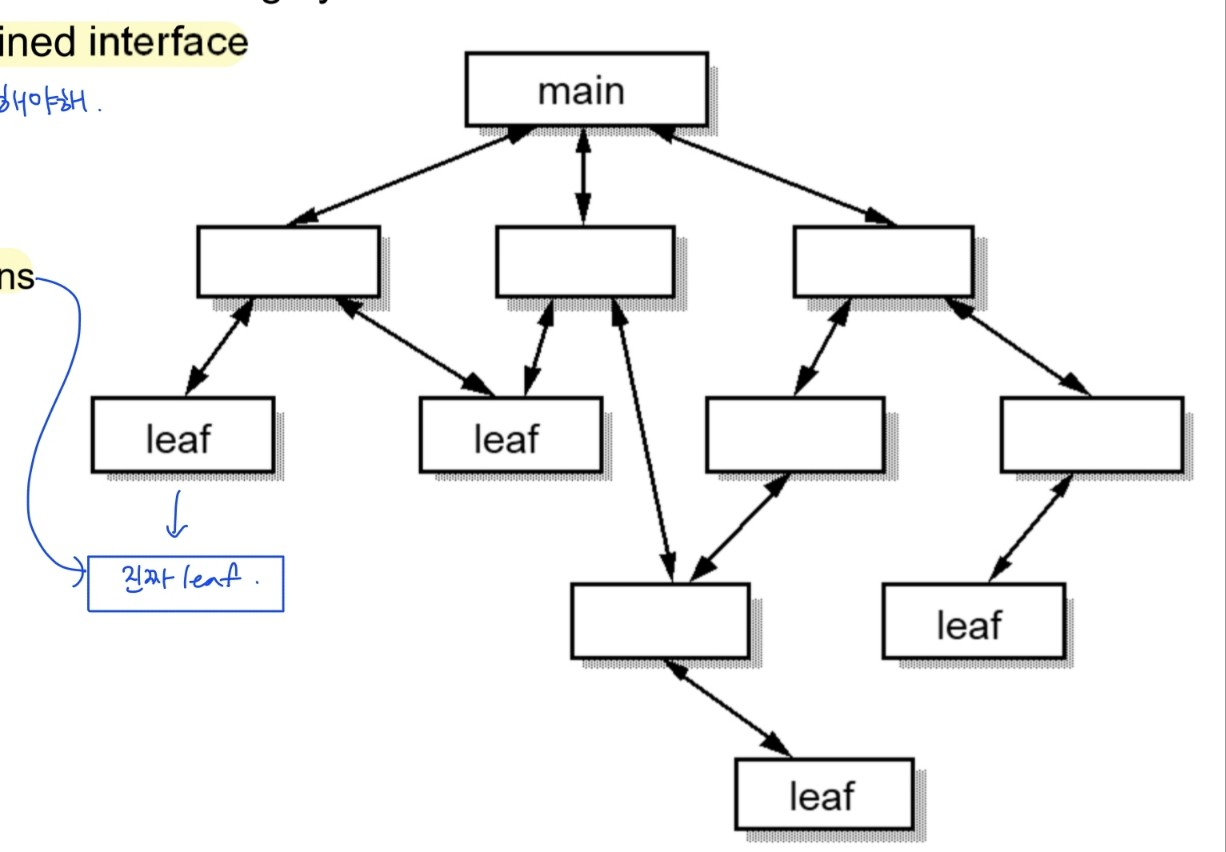
- library나 system 함수의 경우 보이진 않지만 진짜 leaf임
용어
- subroutine : higher level routine에서 부르는 routine
- function : 이름을 통하여 특정 값을 내보내는 것
- c = max(a,b);
- procedure : specified data를 이용한 operation
- printf("Hello World\n")
★ C : 모든 subroutine들이 functions
⇒ returned type이 void면 procedure
Arguments and parameters
- argument : 함수를 부를 때 넘겨주는 값
- parameter : 함수 정의할 때 입력이 들어오는 변수
- argument와 parameter는 일대일 대응됨
- ex)
- c = max(a,b); → a,b는 argument- int max(in1,in2); → in1,in2는 parameter
- C언어는 call by value형식
- 함수를 부를 때마다 각 argument를 복사해서 사용
⇒ parameter가 바껴도 argument에 영향 ㄴㄴ
- 함수를 부를 때마다 각 argument를 복사해서 사용
- call by reference
- parameter가 바꼈을 때 argument에 영향 있음
- C에서 넘겨주는 것이 value가 아니라 pointer라면 함수에서 argument에 직접 접근하여 argument가 변함
9. Use of memory
Dynamic data area
- Stack : backtrace record, local variable 등 저장
- Heap : malloc()함수로 만든 새로운 data structure를 위한 memory → 저장한 data가 더이상 필요하지 않으면 지움(heap에만 해당)
Address space model
- Memory management unit
- memory를 page라는 단위로 나누는데 여기에 데이터 할당하는 장치
- 얘네가 메모리 관리함
- physical memory = DRAM / virtual memory
- virtual memory를 사용하면 성능이 안 좋아져
- ★여러개의 프로그램이 사용되는 경우 혹은 메모리 사이즈가 충분히 크지 않은 경우에 전체 program을 다 load 못 할 수도 있음
→ 전체 코드에서 일정 시간동안은 실행되고 있는 코드 주변에 머물러 있음
→ 현재 실행할 부분의 명령어만 메모리에 저장함 (이것도 mmu가 관리)
★ stack의 바닥과 heap의 맨 위가 만나면 memory out이 일어나
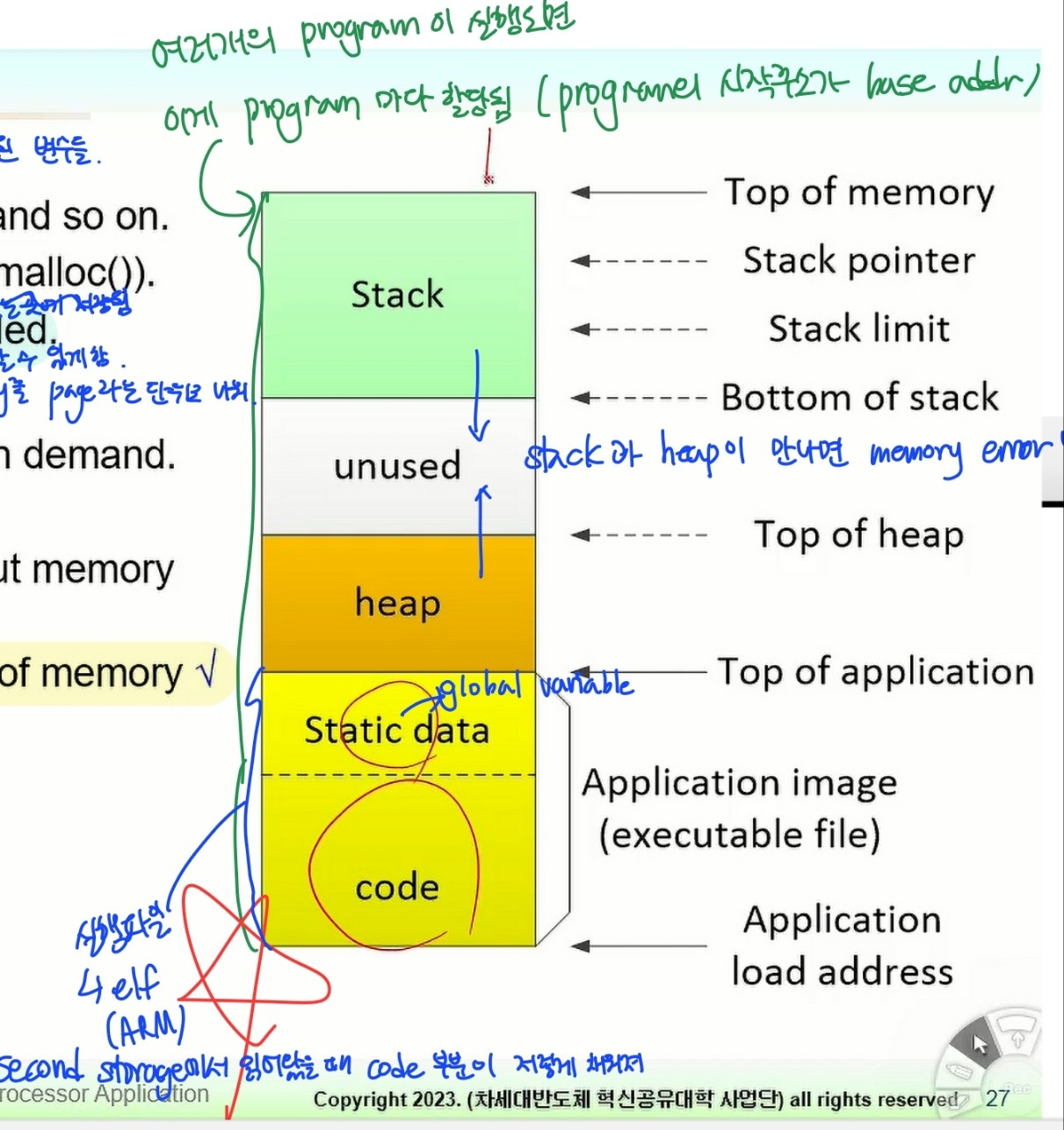
- static data에는 global variable이 들어감
- code + static data = elf (실행파일)
- 여러 개의 program이 실행되면 저 구조가 program마다 할당됨
⇒ program의 시작주소가 base addr - 아래는 저 구조의 예시
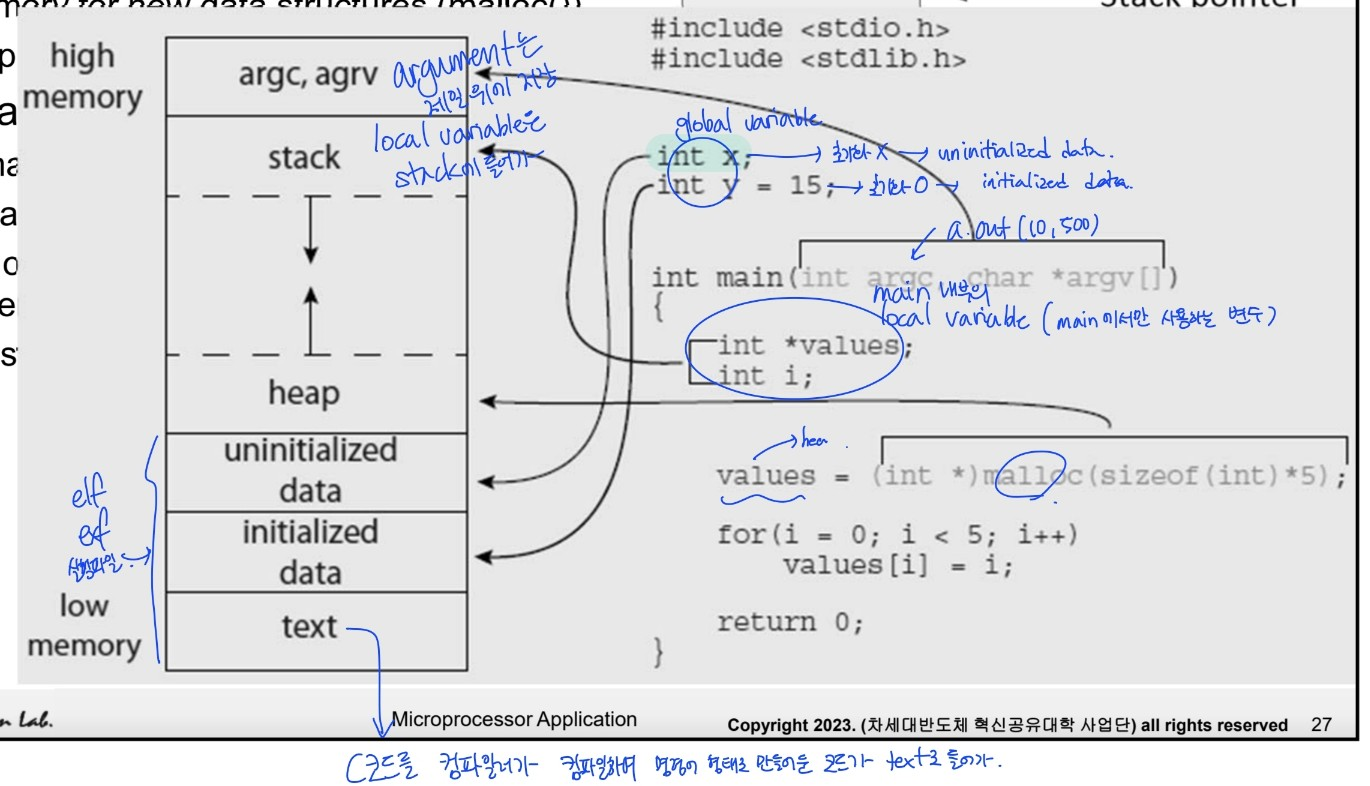
- 맨 위에 argument 들어가
- local variable은 stack에 들어가
- malloc으로 생성한 structure는 heap에 들어감
- 초기화 되지 않은 global variable은 static data의 윗 부분에 들어감
- 초기화 된 global variable은 static data의 아래 부분에 들어감
- ★ C코드를 컴파일러가 컴파일하여 instruction 형태로 만들어둔 코드가 text로 들어감
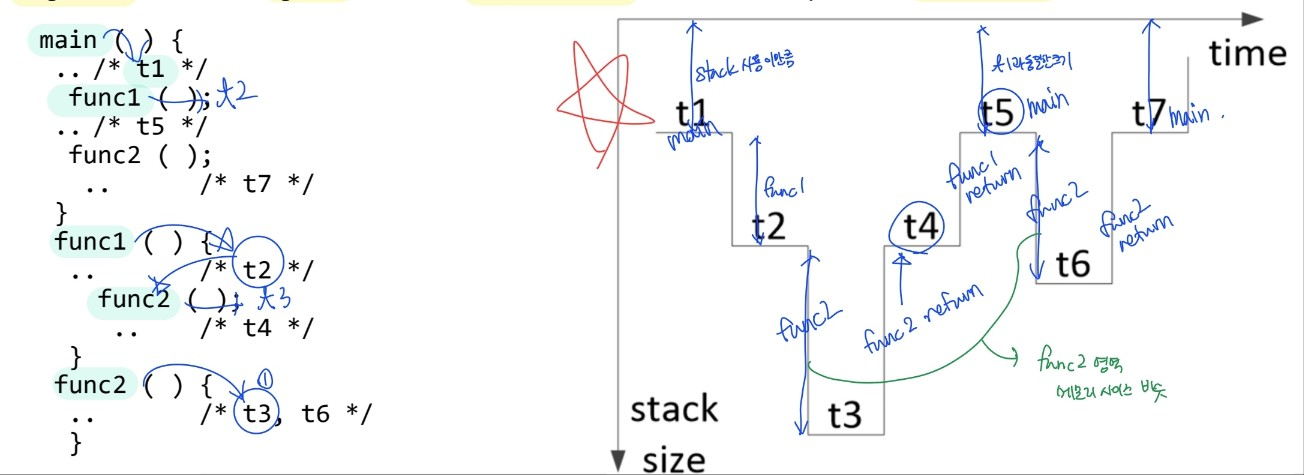
Stack behavior
- memory space가 충분치 않을 때 Chunked stack model 사용
- arguments, saving registers, saving return address, old stack pointer, local variables을 스택에 저장
Data storage
- byte → char
- half-word → short int
- word → int, real
- multiple word → long, double
- multiple of bytes → struct, array, union
- 효율적으로 load/store하려면 memory에 aligned해야해
- non-word aligned address에서 word 읽어오기 → 7개의 instruction 필요
- byte 단위로 data load → load만 4번- 두번째로 loadㅎㄴ data를 다른 레지스터에 load했다가 원래 레지스터에 자리에 맞춰서 옮겨줘야해

- 두번째로 loadㅎㄴ data를 다른 레지스터에 load했다가 원래 레지스터에 자리에 맞춰서 옮겨줘야해
Data alignment
- byte : byte / half-word : even / word : four
- 필요시 padding
- ex. struct S1 {char c; int x; short s;}인 경우 메모리에 아래와 같이 저장됨.
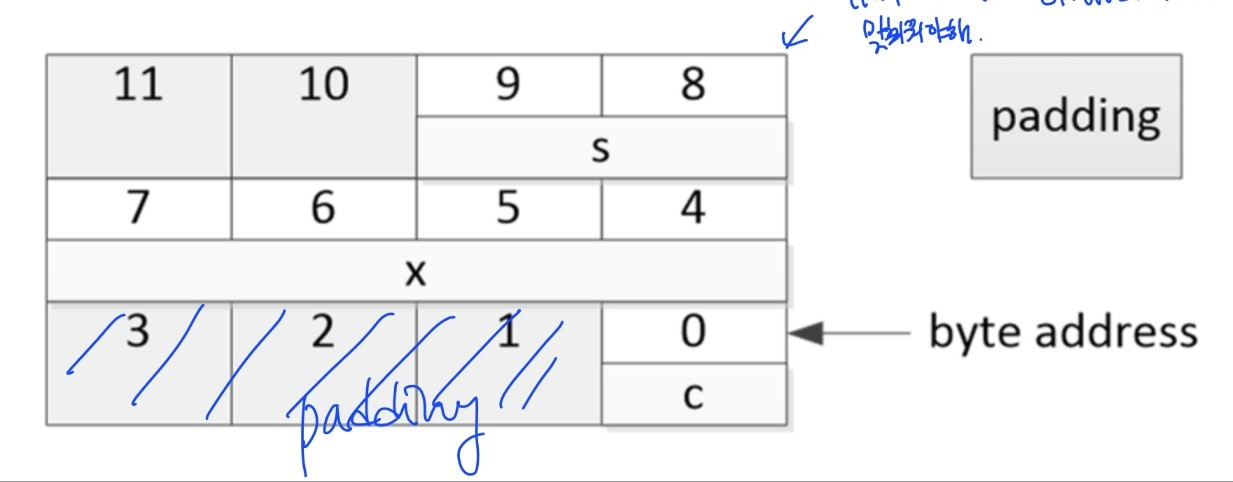
- struct의 시작 주소는 4의 배수여야해서 맨 뒤에도 패딩 해줘야헤
- memory를 효율적으로 쓰려면 padding을 최대한 줄여야해
- structure의 elements들의 순서를 바꿔주면 줄일 수 있어

- Packed struct
- 다른 컴퓨터랑 정보를 교환하거나 메모리 사용량을 최소화하기 위해 data를 pack할 수 있음
- 비효율적인 메모리 접근을 해야함
- __packed struct S3 {char c; int x; short s;}
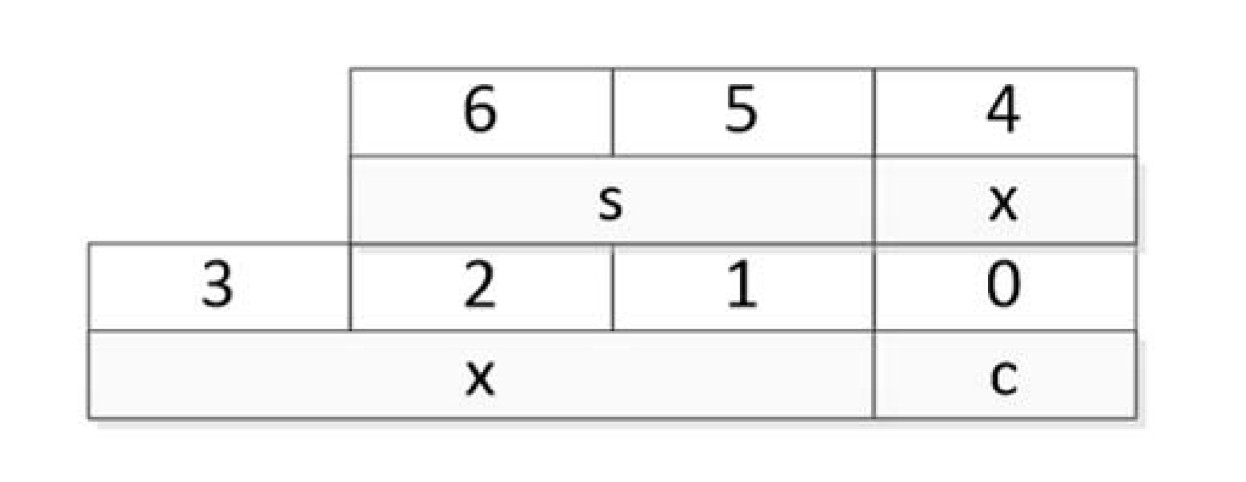
10. Run-time environment
- runtime library 때문에 내가 쓴 코드의 용량보다 실행파일의 크기가 더 커 (736B정도)

