처음 loffe and Szegedy (https://arxiv.org/abs/1502.03167)에 의해서 제안된
신경망 학습단계에서 활성화 값이 평균이 0, 분산이 1인 표준정규분포를 갖도록 강제하는 기법인 배치정규화(Batch Normalization) 기법은 그동안 골칫거리였던 초기화 문제의 상당부분을 해소화 해주었습니다.
여기서 사용한 정규화 기법이 단순 미분 가능한 연산이였기에 신경망 사이에 적용이 가능했습니다.
배치 정규화의 역전파 유도는 Frederik Kratzert의 블로그에 소개되어 있습니다.
(https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html)
실제 구현에서는 배치 정규화 레이어를 FC(Fully-Connected) 레이어 혹은 Convolution 레이어 다음, 비선형 연산 이전에 위치 시키는 방법으로 이 기법을 신경망에 적용하고 있습니다
배치 정규화의 이점은 다음과 같습니다
- 학습 속도 개선 (가중치의 고른 분포 강제로 인한 학습 속도 증가)
- 초깃값에 크게 의존하지 않음
- 오버피팅을 억제 (드롭아웃 등의 필요성 감소)
배치 정규화는 그 이름과 같이 학습 시 미니배치를 단위로 정규화합니다.

미니배치 β라는 m개의 입력 데이터의 집합에 대해 평균 μβ 와 분산 σ²β를 구합니다.
그리고 입력 데이터를 평균이 0. 분산이 1 (적절한 분포가 되도록)이 되게 정규화 합니다.
정규화하는 과정에서는 분모를 0으로 나누는 상황을 방지하기 위해 충분히 작은 수 ε를 추가합니다.
또한, 배치 정규화 계층마다 정규화된 데이터에 고유한 확대(scale)와 이동(shift) 변환을 수행합니다.
확대를 담당하는 γ(초깃값 1), 이동을 담당하는 β(초깃값 0) 부터 시작하여 적합한 값으로 조정해가며 학습을 진행하고, 테스트할 경우에는 고정된 값을 주고 테스트를 진행해야 합니다.
이러한 연산으로 인해 ReLU같은 경우 활성화 값이 0아래로 내려가 뉴런이 비활성화 된다 하더라도
배치 정규화의 확대 및 이동 연산으로 인해 다시 살아나 적절한 학습이 일어날 수도 있습니다.
Tensorflow에서 제공되는 함수(tf.contrib.layers.batch_norm)를 사용하여 배치 정규화를 적용하는 간단한 코드는 아래와 같습니다

- center : 이동을 담당하는 β값의 유무를 설정합니다
- scale : 확대를 담당하는 γ값의 유무를 설정합니다
- is_training : 위에서 설명했듯 train과 test상황에서 다르게 동작하므로 알려줍니다
(tensorflow version별로 세부 내용은 다를 수 있습니다)

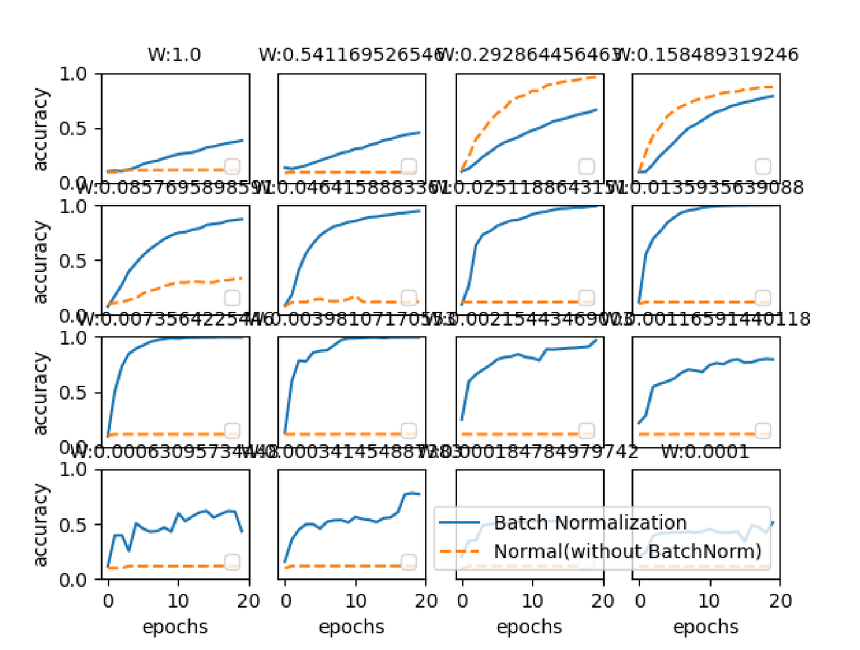
서로 다른 초깃값 표준편차별 배치 정규화를 사용하였을 때와 사용하지 않았을 때의 정확도 차이입니다.
거의 모든 상황에서 배치 정규화를 사용한 신경망의 정확도가 높게 나왔습니다.
앞으로도 각 신경망에서 사용한다면 좋은 결과를 낼 수 있을 것으로 기대됩니다.
