시작하기 전... 🤔
하이퍼파라미터란 무엇일까? 그리고 그 값은 누가, 어떻게 정하는 것일까?
매번 다른 사람들이 올린 코드에 주로 등장하는 튜닝 방법을 별 생각 없이 사용하거나, 때로는 무지성(...)으로 숫자를 바꿔가며 모델의 성능을 조금이라도 더 올리려고 아등바등했었는데, 좀 더 똑똑한 방법으로 튜닝하는 방법은 없을까 고민이 되었다.
캐글 노트북으로 하이퍼파라미터 튜닝 이론과 기법에 대해 공부해보았다.
1. Hyperparameter vs. Parameter
먼저 헷갈리는 하이퍼파라미터와 파라미터 구분부터 하자.
| Hyperparameter | Parameter | |
|---|---|---|
| 설명 | 초매개변수 모델 학습 과정에 반영되는 값 학습 시작 전에 미리 조정 | 매개변수 모델 내부에서 결정되는 변수 데이터로부터 학습 또는 예측되는 값 |
| 예시 | 학습률 손실 함수 배치 사이즈 | 정규분포의 평균, 표준편차 선형 회귀 계수 가중치, 편향 |
| 직접 조정 가능 | O | X |
한국어로 번역된 명칭도 별 도움이 안 된다... 우리가 직접 조정할 수 있는지의 여부를 기준으로 구분할 수 있겠다.
2. 하이퍼파라미터의 종류
- 학습률
- 은닉층 개수
- 배치 사이즈
- 모멘텀
- 에폭 횟수
- 손실 함수 종류
- knn의 k값
이외에도 SVM의 C와 감마, 랜덤포레스트의 가지 개수 등 모델에서 우리가 직접 설정해야 하는 변수들을 통칭해 '하이퍼파라미터'라고 한다.
3. 왜 하이퍼파라미터 튜닝이 필요할까?
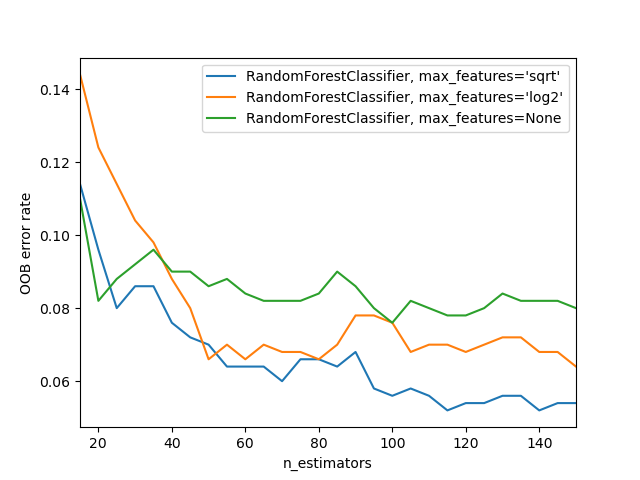
위 그래프를 보면 모델은 모두 랜덤포레스트로 동일하지만 max_features 변수을 다르게 설정함에 따라 OOB error이 모두 다르다.
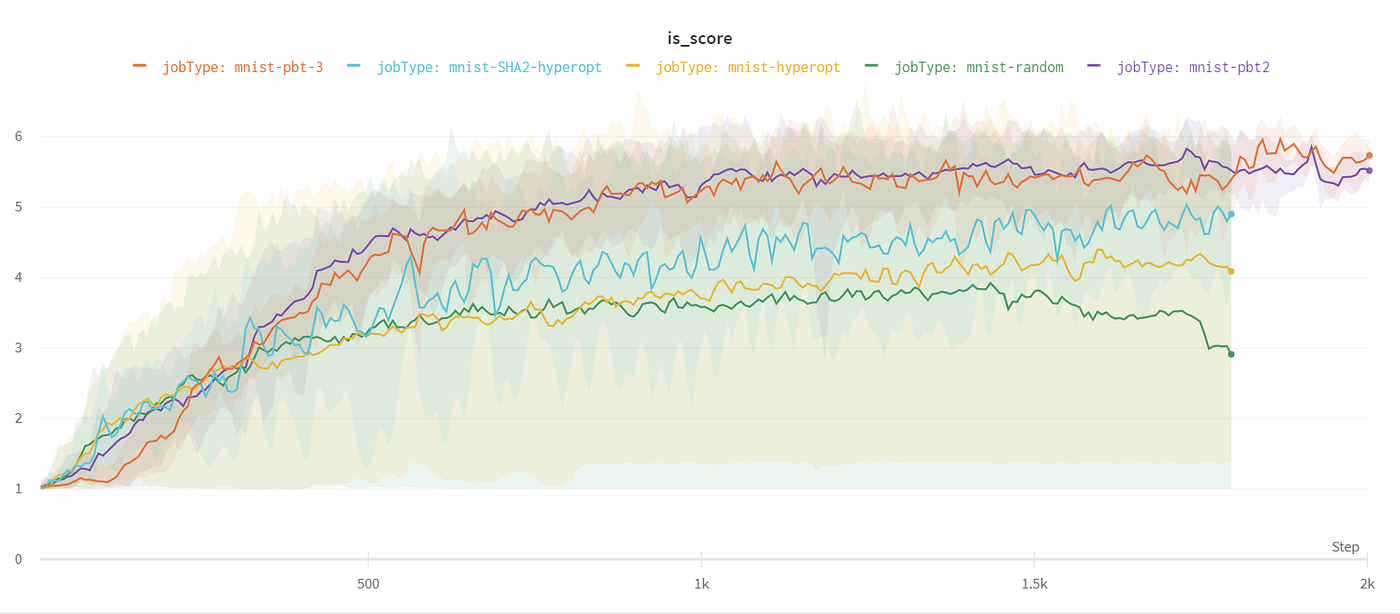
모두 MNIST 모델을 사용했지만 PBT, HyperOpt, random 등 하이퍼파라미터 튜닝 방법을 다르게 설정한 결과, Inception Score(*모델이 생성한 이미지의 퀄리티를 측정하는 지표)가 다르다.
이렇듯 하이퍼파라미터 설정에 따라 모델이 성능이 상이함을 알 수 있다.
즉 하이퍼파라미터 튜닝이란
모델을 최적화하기 위해 하이퍼파라미터를 조정하는 과정
‘hyperparameter optimization’이라고도 함
4. 하이퍼파라미터 튜닝의 종류
- Manual Search
- Grid Search
- Random Search
- Bayesian Optimization
- Non-Probabilistic
- Evolutionary Optimization
- Gradient-based Optimization
- Early Stopping
등의 튜닝 방법이 있다. (정말 많다 @_@)
이 중 manual을 제외한 나머지 방법을 'automated hyperparameter selection'이라 부른다.

이 글에서는 manual search, grid search, random search, bayesian optimization을 살펴보고자 한다.
🎛 Manual Search
‘rules of thumb’ 이라고도 하는데, 경험 또는 감으로 하이퍼파라미터 값을 설정하는 방법을 의미한다. (a.k.a 무지성)
사실 코드에서 조금만 바꾸면 되고, 대부분 성능이 잘 나오게 하는 값들이 흔히 알려져있기 때문에 그대로 따라가는게 편하기는 하다.
하지만 하이퍼파라미터 조합 별 성능을 비교하기 어렵다는 단점이 있다. 모델 돌릴 때마다 매번 바꿀 수는 없지 않은가. (그리고 귀찮다)
Manual Search in Kaggle notebook
이 노트북에서 쓰는 데이터는 Credit Card Fraud Detection Dataset이고, estimator로는 RandomForestClassifier 모델을 사용한다.
Random Forest Classifier 이 가지고 있는 변수:
- criterion = the function used to evaluate the quality of a split.
- max_depth = maximum number of levels allowed in each tree.
- max_features = maximum number of features considered when splitting a node.
- min_samples_leaf = minimum number of samples which can be stored in a tree leaf.
- min_samples_split = minimum number of samples necessary in a node to cause node splitting.
- n_estimators = number of trees in the ensemble.
(sklearn에 있는 변수 설명이다.)
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
df = pd.read_csv('creditcard.csv',na_values = '#NAME?')
X = df[['V17', 'V9', 'V6', 'V12']]
Y = df['Class']
X_Train, X_Test, Y_Train, Y_Test = train_test_split(X, Y, test_size = 0.30,random_state = 101)# manual 1
manual1 = RandomForestClassifier(random_state= 101).fit(X_Train,Y_Train)
predictionforest = manual1.predict(X_Test)
man1_acc = accuracy_score(Y_Test,predictionforest)
man1_acc
0.9994850368081645
# manual 2
manual2 = RandomForestClassifier(n_estimators=10, random_state= 101).fit(X_Train,Y_Train)
predictionforest2 = manual2.predict(X_Test)
man2_acc = accuracy_score(Y_Test,predictionforest2)
man2_acc0.9993914071369217
manual1에서는 random_state, manual2에서는 n_estimators, random_state 변수를 직접 설정해주었더니 정확도가 달리 나온다.
🎛 Grid Search
가장 기본적인 하이퍼파라미터 최적화 방법이다. 아마 대다수의 머신러닝 코드에서 grid 또는 random 방법을 많이 마주쳤을 것이다.
Grid Search는 가능한 모든 조합의 하이퍼파라미터로 훈련시켜서 최적의 조합을 찾는다. (영어로는 exhaustive searching 이라고 한다.)
어떤 하이퍼파라미터의 경우 범위가 없기 때문에 사용자가 경계 또는 분명한 값을 설정하는 것이 필요한 경우도 있다.
모든 가능성을 살펴보기에 하이퍼파라미터나 데이터가 많은 경우 시간이 매우 오래 걸린다는 단점이 있다.

여기서 찾는 하이퍼파라미터는 x1, x2이다. (0, 1) 범위 내에서 10개의 값을 사용하여 100가지의 조합이 가능하다. grid search라는 이름대로 조합이 좌표로 정렬되어있다.
파란색 경계선이 높은 성능, 붉은색 경계선이 낮은 성능을 보인 조합이다.
Grid Search in Kaggle notebook
from sklearn.model_selection import GridSearchCV
# 탐색 범위 정의
grid_search = {'criterion': ['entropy', 'gini'],
'max_depth': [2],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [4, 6, 8],
'min_samples_split': [5, 7,10],
'n_estimators': [20]}
clf = RandomForestClassifier()
grid = GridSearchCV(estimator = clf, param_grid = grid_search,
cv = 4, verbose= 5, n_jobs = -1)
grid.fit(X_Train,Y_Train)
grid_pf = grid.best_estimator_.predict(X_Test)
grid_acc = accuracy_score(Y_Test,grid_pf)
print(grid.best_params_)
print(grid_acc){'criterion': 'gini',
'max_depth': 2,
'max_features': 'auto',
'min_samples_leaf': 4,
'min_samples_split': 5,
'n_estimators': 20}
0.9992392589211521
grid_search 라는 변수는 grid search의 탐색 범위를 설정해주는 변수이다. grid search 이외에 다른 방법들도 탐색 범위 정의는 필요하다.
🎛 Random Search
Random Search는 경계 내에서 임의의 조합을 추출하여 최적의 조합을 찾는 방법이다. Grid Search 에 비해 시간 대비 성능이 좋다고 한다.
특히 적은 수의 하이퍼파라미터가 모델 성능의 영향을 미치는 경우에 좋은 결과를 낸다.
하지만 Grid Search와 마찬가지로 최적의 하이퍼파라미터를 찾기 위해 넓은 범위를 탐색하기 때문에 비효율적이다.
그 결과 Automated hyperparameter tuning이 등장하게 되었다.

Grid Search와 비슷한 그림이지만, 차이점이라면 Random Search는 특정값이 정해지지 않은 범위 내에서 100개의 조합을 무작위로 추출한다. 때문에 x가 산발적으로 분포되어있다.
그래프 테두리의 초록색 선은 선택된 값을 의미하는 것으로, x1은 0.4 근처, x2는 0.6 근처의 값이 많이 추출된 것을 볼 수 있다.
Random Search in Kaggle notebook
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import cross_val_score
random_search = {'criterion': ['entropy', 'gini'],
'max_depth': [2],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [4, 6, 8],
'min_samples_split': [5, 7,10],
'n_estimators': [20]}
clf = RandomForestClassifier()
random = RandomizedSearchCV(estimator = clf, param_distributions = random_search, n_iter = 10,
cv = 4, verbose= 1, random_state= 101, n_jobs = -1)
random.fit(X_Train,Y_Train)
random_pf = random.best_estimator_.predict(X_Test)
random_acc = accuracy_score(Y_Test,random_pf)
print(random.best_params_)
print(random_acc){'n_estimators': 20,
'min_samples_split': 10,
'min_samples_leaf': 4,
'max_features': 'auto',
'max_depth': 2,
'criterion': 'gini'}
0.9992509626300574
grid search와 코드는 거의 똑같다.
🎛 Bayesian Optimization
베이지안 최적화는 목적함수를 최대 또는 최소로 하는 최적해를 찾는 방법이다.
베이지안 최적화를 이해하려면 다음의 개념을 이해하는 것이 중요하다.
- Surrogate model: 목적 함수에 대한 확률적인 추정을 하는 모델. 우리가 추정한 목적함수
- Acquisition function: Surrogate model이 확률적으로 추정한 결과를 바탕으로 다음 입력 데이터(하이퍼파라미터 조합)를 추천하는 함수
여기서의 목적함수는 loss, accuracy 등 우리가 구하고자 하는 지표를 의미한다.
베이지안 최적화는 목적함수와 하이퍼파라미터의 조합을 대상으로 Surrogate model을 만들어 평가하고 Acquisition Function이 다음 인풋으로 사용할 조합을 추천하는 과정을 반복하면서 순차적으로 업데이트하여 최적의 조합을 찾아낸다.
주로 DL보다는 ML에서 사용한다고 한다.
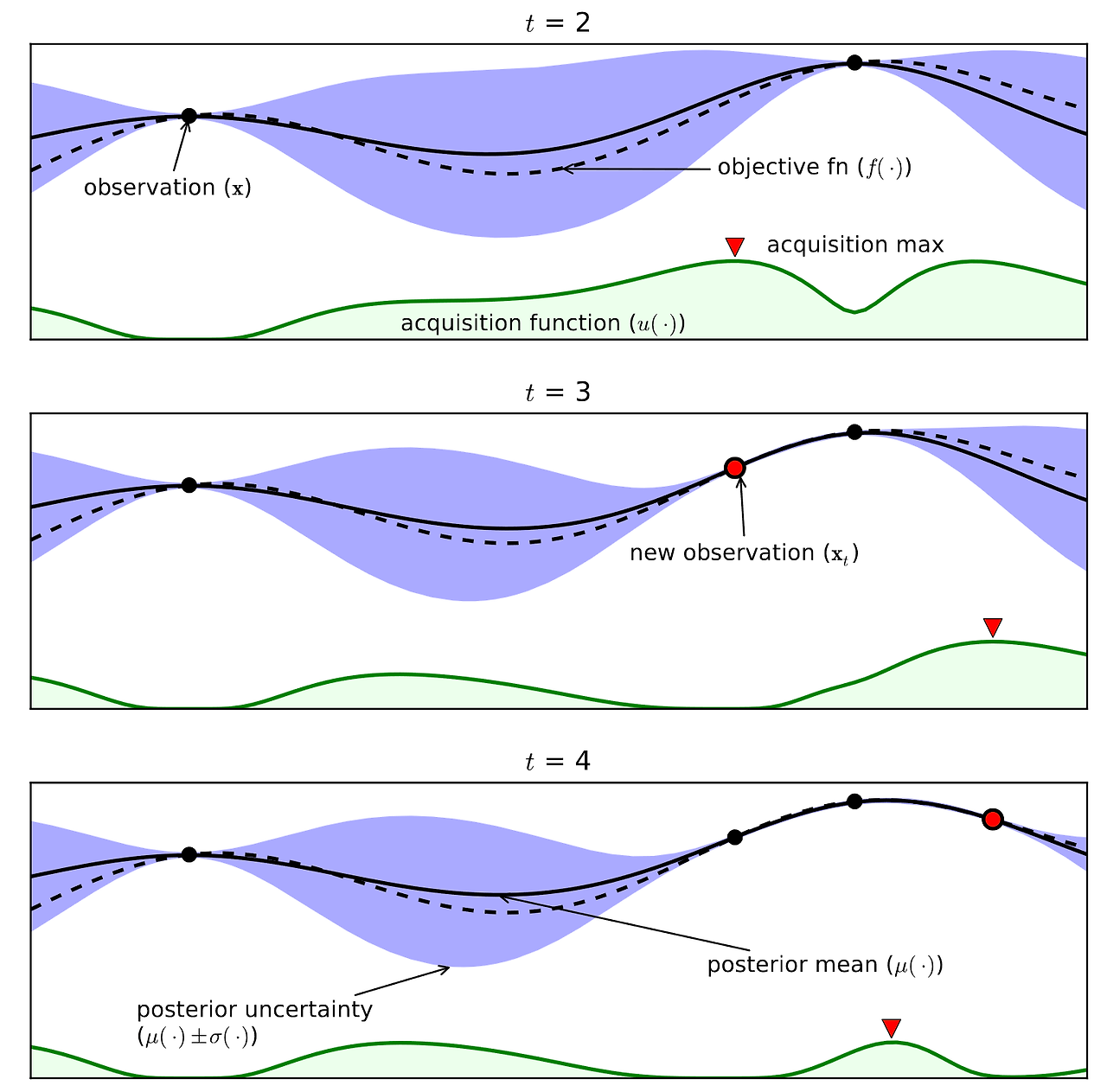
위 그림은 베이지안 최적화 과정을 도식화한 그림이다.
파란색 범위는 불확실한 범위, 즉 오차이고, 점은 각 스텝에서의 관찰, 점선은 Objective function, 실선은 Surrogate model, 초록색 선은 Acquisition function, 그리고 빨간색 세모는 Acquisition function의 최댓값으로 다음 관찰지점이 되는 곳이다.
t=2 시점에서 관찰을 한 결과 빨간색 세모 지점에서 최댓값이 나왔다. 이 부근이 다음 시점인 t=3에서의 관찰지점이 되는 것이다. 그 부근에 파란색이 사라진 것으로 보아 불확실성이 사라진 지점이라고 해석할 수 있다. 새로운 최댓값의 등장으로 다음 관찰 지점이 옮겨간다.
이런 과정을 반복하면서 하이퍼파라미터 조합을 최적화해나간다.
HyperOpt
캐글 노트북에서는 베이지안 최적화 모델을 기반으로 하는 HyperOpt라는 프레임워크를 소개하고 있다.
HyperOpt는 자동화된 하이퍼파라미터 튜닝 프레임워크로서, fmin()이라는 함수 안에는 3가지의 파라미터가 있다:
- Objective Function: 최소화할 손실 함수
- Domain Space: 탐색 범위. 베이지안 최적화에서는 이 범위가 각 하이퍼파라미터에 대해 통계 분포를 만들어낸다.
- Optimization Algorithm : 최적의 조합을 찾기 위한 알고리즘
HyperOpt in Kaggle notebook
from hyperopt import hp, fmin, tpe, STATUS_OK, Trials
# space: 알고리즘이 탐색할 범위를 정의한다.
# hp.choice: 리스트 내의 값을 무작위로 추출
# hp.uniform: 정의된 범위 내에서 임의의 숫자를 무작위 추출
# hp.quniform: 정의된 범위 내에서 마지막 숫자만큼의 간격을 두어 숫자를 추출
space = {'criterion': hp.choice('criterion', ['entropy', 'gini']),
'max_depth': hp.quniform('max_depth', 10, 12, 10),
'max_features': hp.choice('max_features', ['auto', 'sqrt','log2', None]),
'min_samples_leaf': hp.uniform ('min_samples_leaf', 0, 0.5),
'min_samples_split' : hp.uniform ('min_samples_split', 0, 1),
'n_estimators' : hp.choice('n_estimators', [10, 50])
}
def objective(space):
hopt = RandomForestClassifier(criterion = space['criterion'],
max_depth = space['max_depth'],
max_features = space['max_features'],
min_samples_leaf = space['min_samples_leaf'],
min_samples_split = space['min_samples_split'],
n_estimators = space['n_estimators'],
)
accuracy = cross_val_score(hopt, X_Train, Y_Train, cv = 4).mean()
# We aim to maximize accuracy, therefore we return it as a negative value
return {'loss': -accuracy, 'status': STATUS_OK }
trials = Trials()
best = fmin(fn= objective,
space= space,
algo= tpe.suggest,
max_evals = 20,
trials= trials)
# 최적의 하이퍼파라미터 조합
best{'criterion': 1,
'max_depth': 10.0,
'max_features': 3,
'min_samples_leaf': 0.017342284266195274,
'min_samples_split': 0.2509860841981386,
'n_estimators': 1}
# best를 통해 최적의 조합이 도출되었으니, 이를 바탕으로 모델을 학습시켜야 한다. 그러기 위해서는 변수들이 가진 element에 인덱스를 부여한다.
# hp.uniform은 숫자를 무작위로 추출하기에 우리가 알 수 없으므로, choice, quniform을 메소드로 가진 변수들만 딕셔너리로 만들어준다.
crit = {0: 'entropy', 1: 'gini'}
feat = {0: 'auto', 1: 'sqrt', 2: 'log2', 3: None}
est = {0: 10, 1: 50, 2: 75, 3: 100, 4: 125}
trainedforest = RandomForestClassifier(criterion = crit[best['criterion']],
max_depth = best['max_depth'],
max_features = feat[best['max_features']],
min_samples_leaf = best['min_samples_leaf'],
min_samples_split = best['min_samples_split'],
n_estimators = est[best['n_estimators']]
).fit(X_Train,Y_Train)
hopt_acc = accuracy_score(Y_Test,hopt_pf)
print(hopt_acc)
0.9983146659176293
약 99.8% 의 정확도를 보인다.
이 캐글 노트북에서는 HyperOpt라는 자동화 프레임워크를 소개하고 있지만, BayesianOptimization이라는 라이브러리도 존재한다.
🎛 Optuna
하이퍼파라미터 튜닝을 공부하기 위해 캐글을 뒤지다보니, 상당수의 노트북이 'Optuna'라는 프레임워크를 사용하는 것을 발견했다. 실제로 외국 블로그에도 HyperOpt와 Optuna 비교, Optuna를 많이 쓰는 이유에 대한 고찰 등의 글이 많았다. 따라서 Optuna가 무엇인지도 공부해보기로 했다.
Optuna란 하이퍼파라미터 최적화 태스크를 자동화해주는 프레임워크로, 다음과 같은 장점이 있다.
- 거의 모든 ML/DL 프레임워크에서 사용 가능한 넓은 범용성을 가지고 있다.
- 간단하고 빠르다.
- 최신 동향의 다양한 최적화 알고리즘을 갖추고 있다.
- 병렬 처리가 가능하다.
- 간단한 메소드로 시각화가 가능하다.
이러한 이유로 하이퍼파라미터 튜닝 자동화 프레임워크인 HyperOpt와 비교했을 때 비교적 많이 쓰이고 있다.
Optuna를 이해하기 위해서는 다음의 용어에 익숙해져야 한다.
- Study: 목적 함수에 기반한 최적화
- Trial: 목적함수 시행
쉽게 말해 study는 최적화를 하는 과정이고, trial은 다양한 조합으로 목적함수를 시행하는 횟수를 뜻한다.
Study의 목적은 여러 번의 trial을 거쳐 최적의 하이퍼파라미터 조합을 찾는 것이라고 할 수 있겠다.
Optuna in Kaggle notebook
import optuna
# 1. 최소화/최대화할 목적함수 정의
def objective(trial):
iris = sklearn.datasets.load_iris()
x, y = iris.data, iris.target
# 2. trial object로 하이퍼파라미터 값 추천
# 다양한 분류모델을 설정해서 비교할 수 있다.
classifier_name = trial.suggest_categorical('classifier', ['SVC', 'RandomForest'])
#분류 모델이 SVC일 때
if classifier_name == 'SVC':
svc_c = trial.suggest_loguniform('svc_c', 1e-10, 1e10)
classifier_obj = sklearn.svm.SVC(C=svc_c, gamma='auto')
#분류모델이 랜덤포레스트일 때
else:
rf_max_depth = int(trial.suggest_loguniform('rf_max_depth', 2, 32))
classifier_obj = sklearn.ensemble.RandomForestClassifier(max_depth=rf_max_depth, n_estimators=10)
accuracy = cross_val_score(classifier_obj, x, y, cv = 4).mean()
return accuracy
# 3. study 오브젝트 생성하고 목적함수 최적화하는 단계
# 여기서는 목적함수를 정확도로 설정했기 때문에 최대화를 목표로 하고 있지만, 손실함수의 경우 direction='minimize'로 설정
study = optuna.create_study(direction='maximize')
# 반복 시행 횟수(trial)는 200번으로
study.optimize(objective, n_trials=200)# 시행된 trial 중 최적의 하이퍼파라미터 반환하는 메소드
print(study.best_trial.params)
# 시행된 trial 중 가장 높은 값 반환하는 메소드
optuna_acc = study.best_trial.value
print(optuna_acc){'classifier': 'SVC', 'svc_c': 5.8796966956898995}
0.9735064011379801
Optuna 내장 시각화 코드
# 하이퍼파라미터별 중요도를 확인할 수 있는 그래프
optuna.visualization.plot_param_importances(study)
# 하이퍼파라미터 최적화 과정을 확인
optuna.visualization.plot_optimization_history(study)내장된 메소드로 최적의 조합, 정확도, 하이퍼파라미터별 중요도와 과정까지 시각화할 수 있다는 점이 매우 편리한 것 같다.
글에서 소개한 방법 이외에도 정말 다양한 방법이 존재한다. 다음 머신러닝 태스크에서는 무지성보다 이러한 방법을 토대로 하이퍼파라미터 튜닝을 하는 것도 재밌을 것 같다.
사실 세션 발제 때문에 이렇게 열심히 찾아본건데 방대한 자료가 존재할 줄이야....
성능 소수점 네다섯 자리 더 올리는게 미미해보이지만 그래도 실제로 해보면 꽤나 어렵다.
별 생각 없이 썼던 모듈들에 이렇게나 다양한 알고리즘과 파라미터가 존재한다는게 새삼 신기했다. 사이킷런 공식 도큐먼트 정독한 것도 거의 처음인 듯 하다.
재미있는 공부였다!
참고
참고한 자료들
하이퍼파라미터 vs. 파라미터
하이퍼파라미터 튜닝 위키피디아
캐글 노트북
베이지안 최적화
HyperOPt vs. Optuna
왜 캐글에서는 Optuna를 많이 쓸까?



그동안 gridsearch만 써왔었는데 optuna랑 hyperOpt 좋은 거 얻어갑니다,,,총총
왜 그동안 저런 프레임워크들을 모르고 안썼을까 ...