PCA
t-SNE
📘Kaggle
코로나가 빠르게 확산되는 바람에, 의학계가 최신 연구를 따라가기가 매우 어려워졌다. 그래서 이 노트북에서는 논문들을 클러스터링해서 시각하는 작업을 하고 있다. 차원 축소와 토픽 모델링을 사용해서 클러스터링을 하고, Bokeh 라이브러리로 interactive plot을 만들었다.
workflow
- 문서 (논문) 전처리
- TF-IDF로 각 문서를 벡터화
- PCA로 차원 축소
- t-SNE로 이차원 공간에 유사한 논문을 클러스터
- k-means clustering
- LDA
전처리
- 13310 → null 값 제거 후 8879개로 줄임
- 8879개 중 영어로 쓰인 논문이 8587개라서 영어 논문만 남김 (번역하기에는 API의 한계가 있고, 의미 정보를 충분히 살리지 못할 것으로 판단)
- spaCy를 활용해서 불용어 제거, parsing
- TfidfVectorizer로 vectorization
🪐spaCy?
자연어처리를 위한 오픈소스 라이브러리로, 연구보다는 산업 목적의 사용에 맞춰져 있다고 한다. 그래서 여러 초이스를 주기보다는 개발자들이 사용하기 쉬운 단 하나의 기능만 제공한다고.
속도가 빠르고, 사용하기 쉽고, 딥러닝 프레임워크와 호환이 좋다고 한다.
근데 아직 한국어는 지원이 안 된다....
PCA
from sklearn.decomposition import PCA
# 95%의 분산을 유지하는 선에서 PCA를 진행
pca = PCA(n_components=0.95, random_state=42)
X_reduced= pca.fit_transform(X.toarray())
X_reduced.shape(8587, 2305)
K-Means Clustering
from sklearn.cluster import MiniBatchKMeans
from sklearn.cluster import KMeans
from sklearn import metrics
from scipy.spatial.distance import cdist
# run kmeans with many different k
distortions = []
K = range(2, 30)
for k in K:
k_means = KMeans(n_clusters=k, random_state=42).fit(X_reduced)
k_means.fit(X_reduced)
distortions.append(sum(np.min(cdist(X_reduced, k_means.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])
#print('Found distortion for {} clusters'.format(k))X_line = [K[0], K[-1]]
Y_line = [distortions[0], distortions[-1]]
# Plot the elbow
plt.plot(K, distortions, 'b-')
plt.plot(X_line, Y_line, 'r')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('The Elbow Method showing the optimal k')
plt.show()k = 20
kmeans = KMeans(n_clusters=k, random_state=42)
y_pred = kmeans.fit_predict(X_reduced)
df['y'] = y_predt-SNE
고차원의 벡터 클러스터를 2차원에 표현해서 시각화할 수 있도록 하는 단계
from sklearn.manifold import TSNE
tsne = TSNE(verbose=1, perplexity=50) # Changed perplexity from 100 to 50 per FAQ
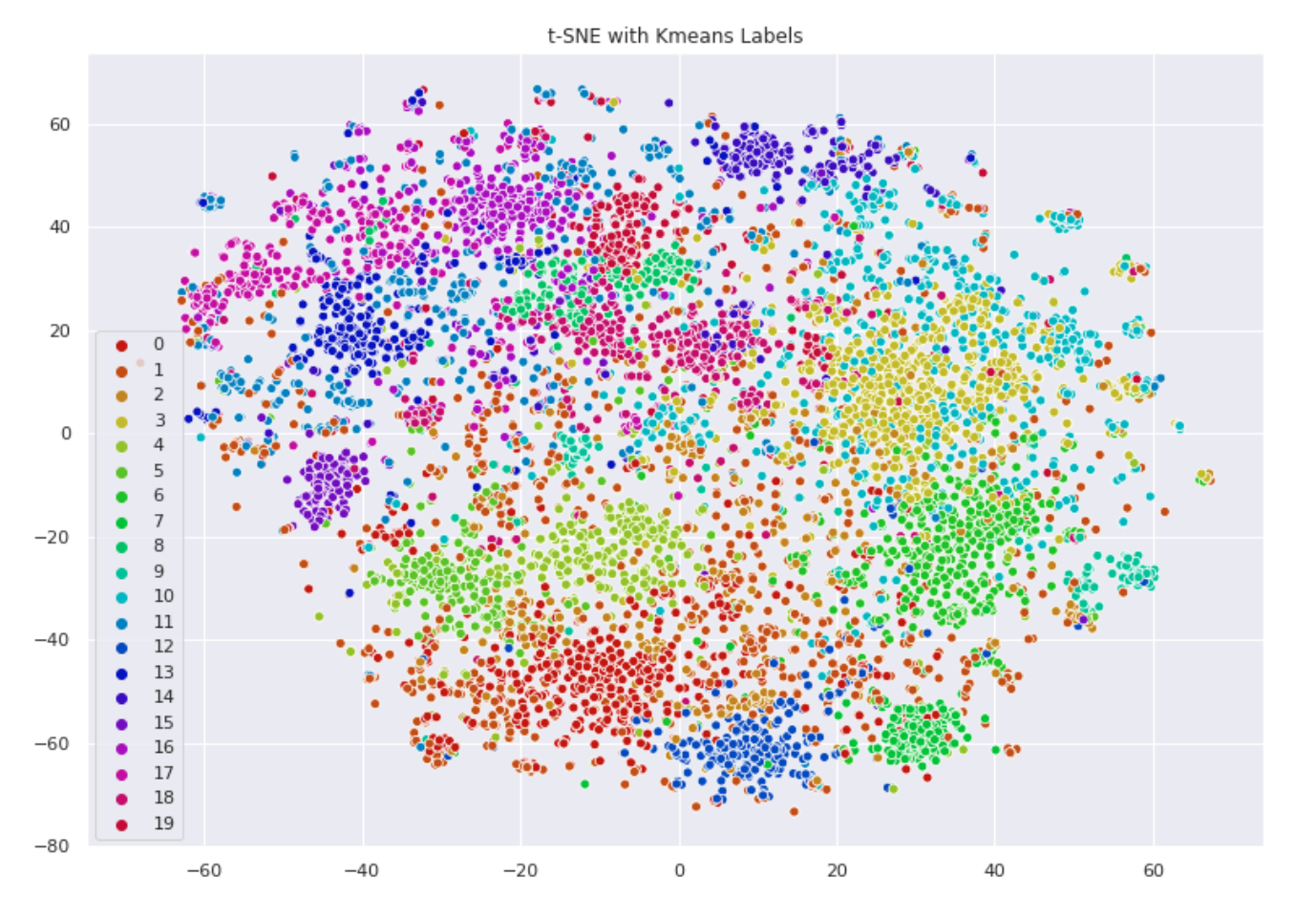
X_embedded = tsne.fit_transform(X.toarray())❗️환공포증 유발 주의❗️
t-SNE로 시각화한 플롯에 클러스터별 색깔을 입혔더니 이렇게 나왔다. 이제 여기다 토픽, 키워드 추출만 하면 됨!
LDA
클러스터에 라벨 부여 + 토픽 별 키워드 추출
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.feature_extraction.text import CountVectorizer
# 한 클러스터당 하나씩, 20개의 벡터라이저 생성
vectorizers = []
for ii in range(0, 20):
# Creating a vectorizer
vectorizers.append(CountVectorizer(min_df=5, max_df=0.9, stop_words='english', lowercase=True, token_pattern='[a-zA-Z\-][a-zA-Z\-]{2,}'))각 클러스터를 벡터화
vectorized_data = []
for current_cluster, cvec in enumerate(vectorizers):
try:
vectorized_data.append(cvec.fit_transform(df.loc[df['y'] == current_cluster, 'processed_text']))
except Exception as e:
print("Not enough instances in cluster: " + str(current_cluster))
vectorized_data.append(None)LDA 모델 생성
# number of topics per cluster
NUM_TOPICS_PER_CLUSTER = 20
lda_models = []
for ii in range(0, 20):
# Latent Dirichlet Allocation Model
lda = LatentDirichletAllocation(n_components=NUM_TOPICS_PER_CLUSTER, max_iter=10, learning_method='online',verbose=False, random_state=42)
lda_models.append(lda)각 클러스터 벡터에 LDA 모델 fit
clusters_lda_data = []
for current_cluster, lda in enumerate(lda_models):
print("Current Cluster: " + str(current_cluster))
if vectorized_data[current_cluster] != None:
clusters_lda_data.append((lda.fit_transform(vectorized_data[current_cluster])))클러스터별 키워드 추출
# Functions for printing keywords for each topic
def selected_topics(model, vectorizer, top_n=3):
current_words = []
keywords = []
for idx, topic in enumerate(model.components_):
words = [(vectorizer.get_feature_names()[i], topic[i]) for i in topic.argsort()[:-top_n - 1:-1]]
for word in words:
if word[0] not in current_words:
keywords.append(word)
current_words.append(word[0])
keywords.sort(key = lambda x: x[1])
keywords.reverse()
return_values = []
for ii in keywords:
return_values.append(ii[0])
return return_values
# Append list of keywords for a single cluster to 2D list of length NUM_TOPICS_PER_CLUSTER
all_keywords = []
for current_vectorizer, lda in enumerate(lda_models):
print("Current Cluster: " + str(current_vectorizer))
if vectorized_data[current_vectorizer] != None:
all_keywords.append(selected_topics(lda, vectorizers[current_vectorizer]))
all_keywords[0][:10] ['disease', 'covid-', 'research', 'food', 'community','datum', 'company', 'case', 'social', 'technology']
시각화
코드가 길어서 첨부는 하지 않았지만, 이 노트북에서는 Bokeh를 사용해서 시각화하였다.
🎨Bokeh

공부 중