

이번에는 Decision Tree를 Ensemble 하는 방법 중 Boosting 기법과 대표적인 모델들을 알아보도록 하자.
🍲🥣 soup → 숲 → forest 깔깔깔
🌲Boosting
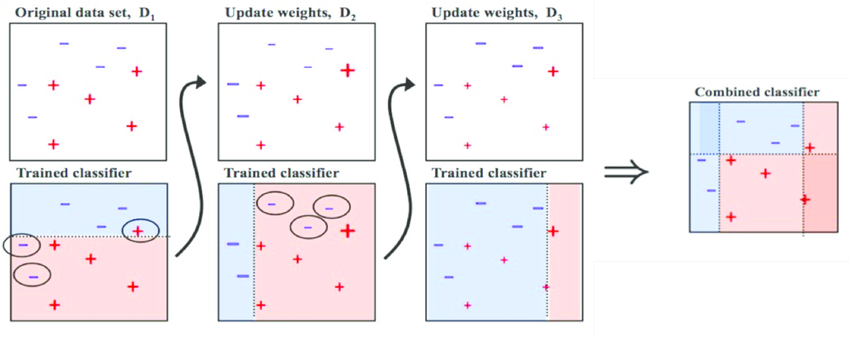
부스팅은 약한 학습 모델을 여러 개 붙여서 하나의 강한 학습 모델을 만드는 앙상블 기법이다. 순차적으로 학습을 시켜 이전 모델의 오답을 다음 모델에서 고치려고 하기 때문에, 이전 모델에 의존하게 된다.
부스팅은 오답에 집중해서 학습하기 때문에 성능이 좋지만, 그만큼 outlier에 취약하며 오버피팅의 우려가 있다.
Gradient Boosting
이어 소개할 세 개의 모델은 모두 gradient boosting 을 기반으로 하는 모델이다.
그러기 전에 Gradient Boosting이 뭔지부터 알고 가자.
Step 1.
먼저 각 데이터 포인트에 동일한 가중치를 부여하고, 성능이 그다지 좋지 않은 모델로 학습을 시킨다. 이때 모델은 50%를 간신히 넘는 정도의 미약한 성능을 보이는 모델이다. 그러면 제대로 예측되지 않은 데이터포인트가 존재할 것이다. (=오차)
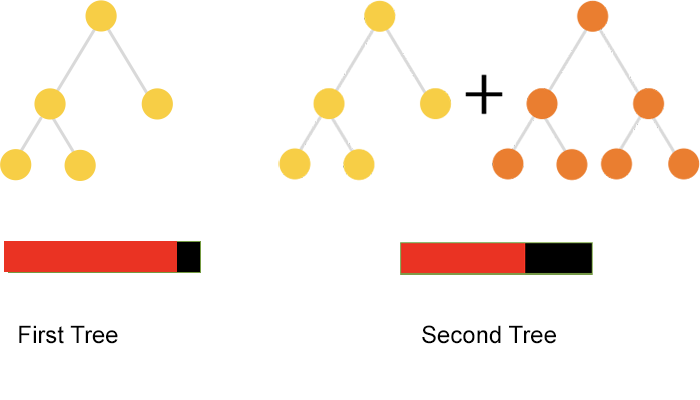
사진의 빨간색은 오차로, 빨간색 영역이 줄어들수록 예측 결과가 정확하다는 뜻이다.
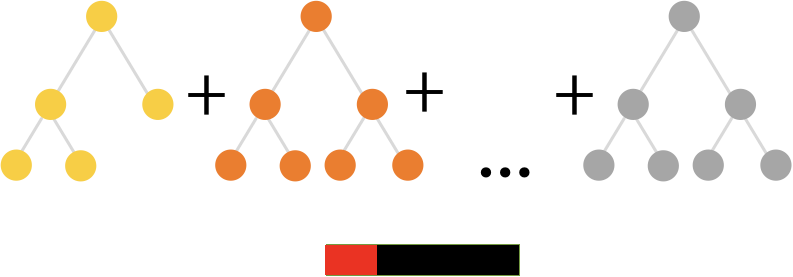
Step 2.
위에서 예측이 틀린 데이터포인트만을 가지고 다시 학습을 시킨다. 성능이 준수할 때까지 이 과정을 계속 반복하는 것!
🌿XGBoost
부스팅 방법 중 가장 많이 쓰이는 것은 단연 XGBoost일 것이다.
XGBoost는 Extreme Gradient Boosting의 약자로,
'Gradient Boosting Decision Tree' (GBDT) 알고리즘을 기반으로 하고 있고 정형, 태뷸러 데이터의 분류/예측 태스크에 많이 쓰인다.
Level-wise vs. Leaf-wise

XGBoost는 트리가 수평으로 자란다. 즉 'Level-wise' 인 반면 LGBM은 'Leaf-wise'로, leaf 하나에서 트리가 수직으로 자란다. 'Level-wise' 는 다른 말로 'depth-first'라고도 부르고, 'Leaf-wise'는 'Leaf-wise'라고 한다.
용어 정리
XGBoost: 층이 늘어남 (수평 성장) = Level-wise = Depth-first
LGBM: 리프가 늘어남 (수직 성장) = Leaf-wise = Best-first
XGBoost는 설정한 max_depth 값까지 다 한 뒤 backward pruning을 통해 gain이 음수가 될 때까지 만든다. 여기서 gain 은 위 level loss에서 왼쪽 가지의 loss와 오른쪽 가지의 loss를 뺀 값이다.
gain = loss(father instances) - (loss(left branch)+loss(right branch))
gain이 양수일 때 계속 가지를 내리고, 음수가 되면 성장을 멈춘다.
Parameters
- max_depth
- learning_rate(=eta): 각 스텝에서 가중치의 'shrinkage' (축소)를 설정함으로써 모델이 더 robust 해지도록 한다. 주로 0.01~0.2 사이의 값이 쓰인다고 함.
- n_estimators: 결정 트리 갯수
- reg_alpha, reg_lambda: L1, L2 규제 정도를 조절. 값을 높일수록 모델이 보수적으로 예측할 것이다.
- min_child_weight: 한 데이터포인트 당 부여할 가중치의 최소값
🌱LGBM
Light Gradient Boosting Machine
LGBM은 XGBoost보다 빠르다. 그래서 "Light"이다.
위에서 설명했듯이 'leaf-wise' 성장을 하기 때문에 loss가 큰 리프를 골라서 손실을 줄이는 성장을 함으로써 오차를 좁혀나간다. 그렇기 때문에 데이터 규모가 작을 경우 오버피팅의 우려가 있다. 그래서 주로 만 개 이상의 열(=데이터 포인트)을 가지는 데이터에 사용하기를 권장한다고 한다.
Parameters
- num_leaves: 모델의 복잡도를 좌우하는 파라미터로, 각 트리가 몇 개의 노드를 가질지 결정한다.
[10, 100]이 권장됨.
2^(max_depth)로 설정할 수도 있으나, 그렇게 되면 트리가 너무 깊어지고 오버피팅이 되기 때문에 depth-wise보다 성능이 좋지 못하게 된다. - min_data_in_leaf: 각 리프가 처리할 데이터의 최솟값. 이 값을 높게 잡을수록 언더피팅이 됨. 100 또는 1000이 적당.
- max_depth: 각 트리가 가질 최대 깊이. 주로 3~8의 값을 가짐.
- num_iterations: 반복 횟수
- early_stopping_rounds: validation 데이터셋으로 성능이 더이상 발전하지 않는다는걸 증명하면 'early-stopping'을 하게 되는데, 몇 번 검증해보고 그만둘지 결정하는 파라미터. 주로
num_iterations의 10% 로 잡는다고 함.
🐈CatBoost
Category Boosting 이라는 의미로, Yandex 에서 개발한 새로운 머신러닝 알고리즘이다.
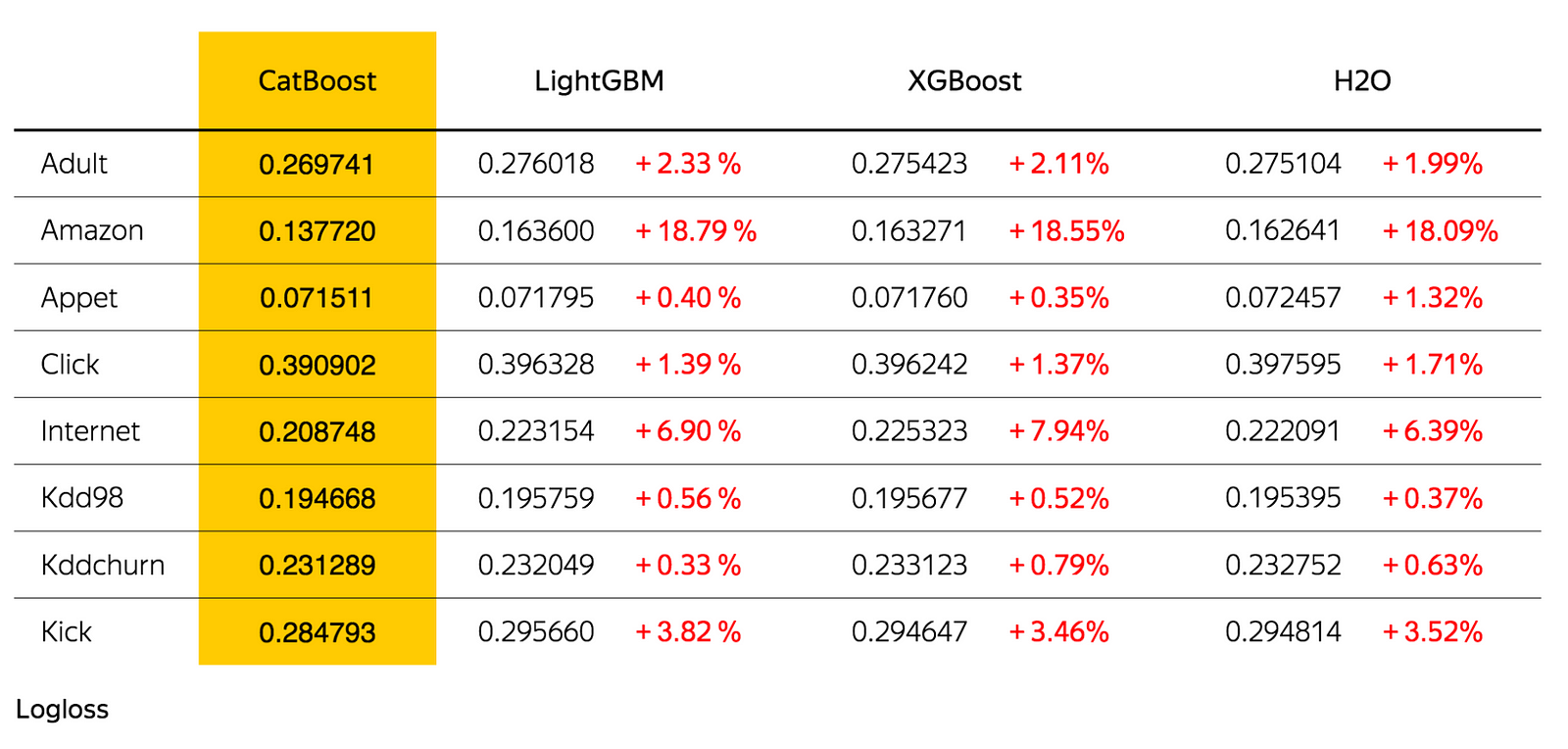
딱 봐도 성능이 매우 우수하다.
기존 알고리즘의 경우 categorical data는 one-hot encoding으로 추가적인 전처리 프로세스를 거쳐야 했지만, CatBoost는 그런거 없이 모델이 자동으로 처리를 해준다.
학습 시간은 느리지만 예측 시간은 빠르다고 한다. 그리고 hyperparameter tuning을 거치지 않고 기본값만으로도 좋은 성능을 낼 수 있는 장점이 있다.
📘Kaggle
XGBoost
from xgboost import XGBRegressor
XGB = XGBRegressor(max_depth=2,learning_rate=0.1,n_estimators=1000,reg_alpha=0.001,reg_lambda=0.000001,n_jobs=-1,min_child_weight=3)
XGB.fit(X_train,y_train)XGBRegressor(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
importance_type='gain', learning_rate=0.1, max_delta_step=0,
max_depth=2, min_child_weight=3, missing=None, n_estimators=1000,
n_jobs=-1, nthread=None, objective='reg:linear', random_state=0,
reg_alpha=0.001, reg_lambda=1e-06, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)
LGBM
from lightgbm import LGBMRegressor
LGBM = LGBMRegressor(n_estimators = 1000)
LGBM.fit(X_train,y_train)LGBMRegressor(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=1000, n_jobs=-1, num_leaves=31, objective=None,
random_state=None, reg_alpha=0.0, reg_lambda=0.0, silent=True,
subsample=1.0, subsample_for_bin=200000, subsample_freq=0)
Score
Training score: 0.9878463275679412 Test Score: 0.930856175748829
Training score: 0.9999557727264998 Test Score: 0.9101390980189892
참고
