
LLM(Large Language Model) 이란
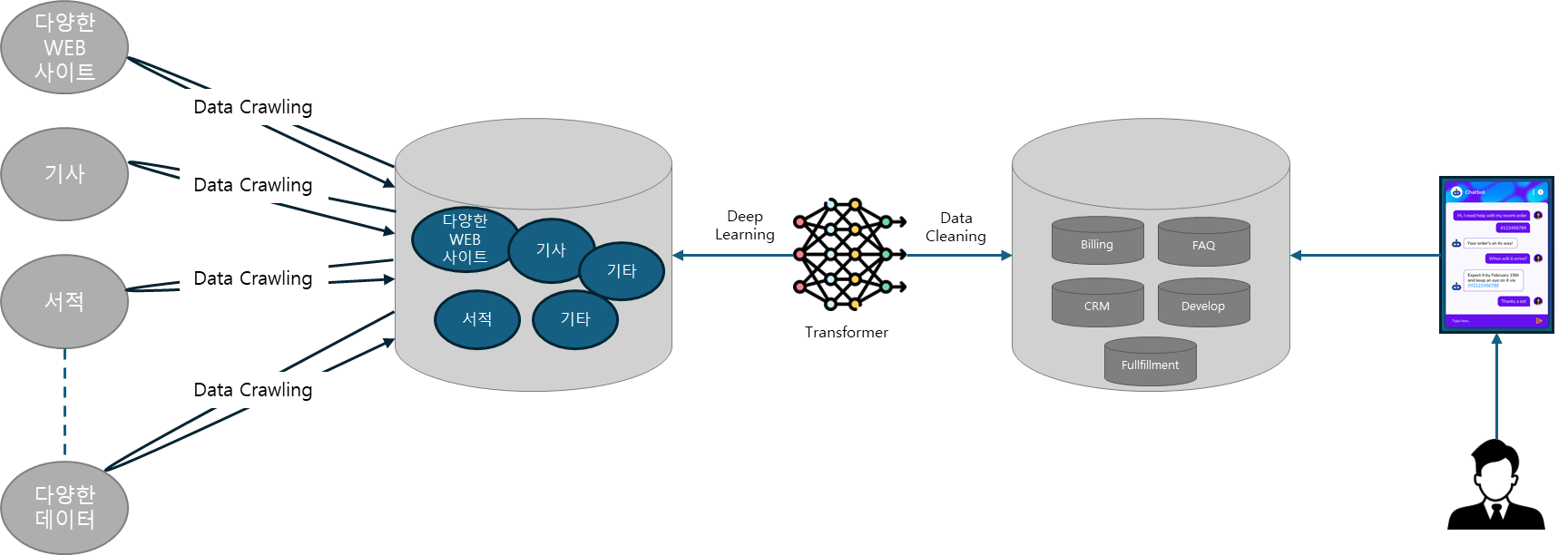
대규모 언어 모델(LLM)은 인간과 유사한 텍스트를 처리, 이해 및 생성하도록 설계된 고급 인공 지능(AI) 시스템입니다. 그들은 딥 러닝 기술을 기반으로 하며 일반적으로 웹 사이트, 책, 기사와 같은 다양한 소스에서 가져온 수십억 개의 단어를 포함하는 대규모 데이터 세트에서 훈련됩니다. 이 광범위한 교육을 통해 LLM은 언어, 문법, 문맥 및 일반 지식의 일부 측면의 뉘앙스를 파악할 수 있습니다.
LLM 구현 절차
- 자신의 도메인에 맞는 사전 학습된 BedRock 모델 선택
- 자체 데이터로 모델 미세 조정
- 모델 배포 및 추론

LLM을 구현하는데 있어 대규모의 데이터 세트가 필수적이며, 다만 데이터의 광범위한 범위와 함께 체계적인 데이터 세트가 필요하며, 만약 데이터 세트의 품질이 낮을 경우 훈련된 모델의 결과가 부정확한 결과를 제공 하게 됩니다.
즉, 거버넌스 측면에서 데이터 세트를 추가 및 클리닝 하는 과정에서 추집된 데이터의 정확성과 함께 보안성을 검증 할 수 있는 확인 절차가 필요 합니다.
Amazon BedRock 이란
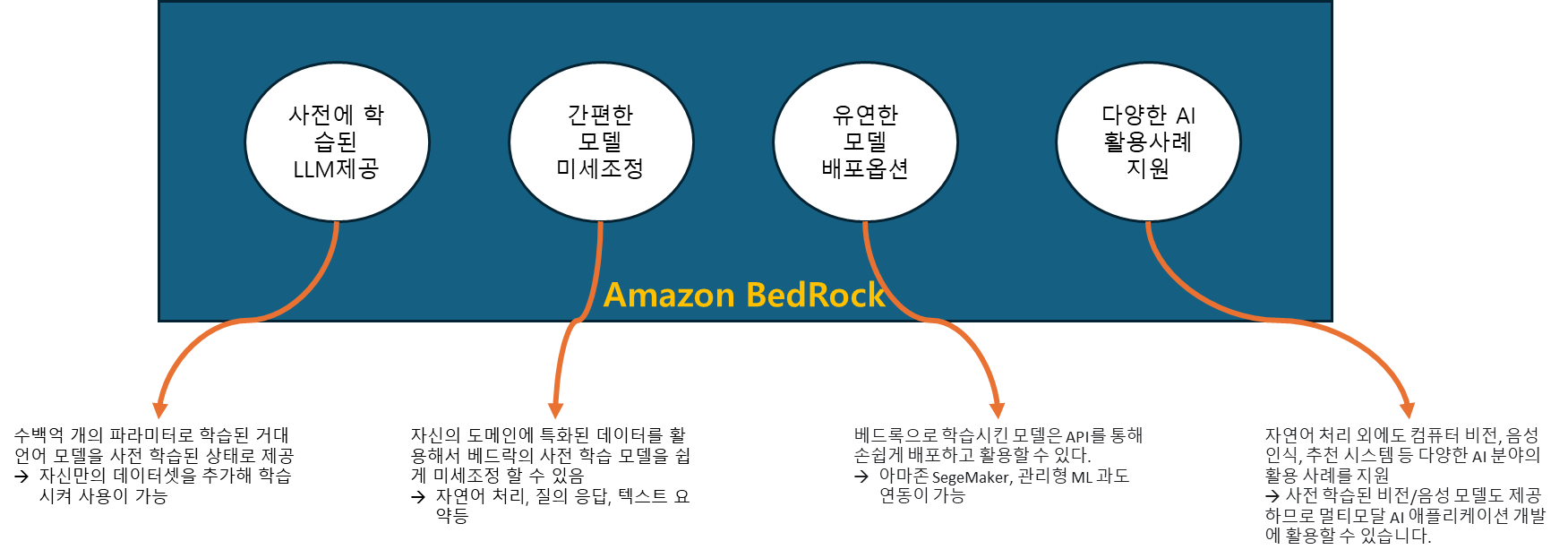
기존에는 GPT-3나 PaLM과 같은 대규모 언어 모델을 개발하려면 막대한 컴퓨팅 자원과 전문 지식이 필요하지만 Amazon BedRock에서는 개발자나 기업이 대규모의 컴퓨터 지원과 전문지식이 없어도 대규모의 AI모델을 구축하고 배포 할 수 있습니다.
※ Amazon BedRock은 대규모 언어 모델(LLM) 개발 및 배포 플랫폼 입니다.
Amazon BedRock 적용사례
Amazon Bedrock을 이용하여 Stream 방식의 한국어 Chatbot 구현
사용자가 Web Client를 이용하여 로그인하면, DynamoDB에서 이전 대화 이력을 가져와 채팅 화면에서 확인할 수 있습니다.

단계1: 브라우저를 이용하여 사용자가 CloudFront 주소로 접속하면, Amazon S3에서 HTML, CSS, JS등의 파일을 전달합니다. 이때 로그인을 수행하고 채팅 화면으로 진입합니다.
단계2: Client는 사용자 아이디를 이용하여 ‘/history’ API로 채팅이력을 요청합니다. 이 요청은 API Gateway를 거쳐서 lambda-history에 전달됩니다. 이후 DynamoDB에서 채팅 이력을 조회한 후에 다시 API Gateway와 lambda-history를 통해 사용자에게 전달합니다.
단계3: Client가 API Gateway로 WebSocket 연결을 시도하면, API Gateway를 거쳐서 lambda-chat-ws로 WebSocket connection event가 전달됩니다. 이후 사용자가 메시지를 입력하면, API Gateway를 거쳐서 lambda-chat-ws로 메시지가 전달됩니다.
단계4: lambda-chat-ws는 사용자 아이디를 이용하여 DynamoDB의 기존 채팅이력을 읽어와서, 채팅 메모리에 저장합니다.
단계5: lambda-chat-ws는 사용자의 질문(Question)과 채팅 이력(Chat history)을 Amazon Bedrock의 Enpoint로 전달합니다.
단계6: Amazon Bedrock의 사용자의 질문과 채팅이력이 전달되면, Anthropic LLM을 이용하여 적절한 답변(Answer)을 사용자에게 전달합니다. 이때, Stream을 사용하여 답변이 완성되기 전에 답변(Answer)를 사용자에게 보여줄 수 있습니다.
