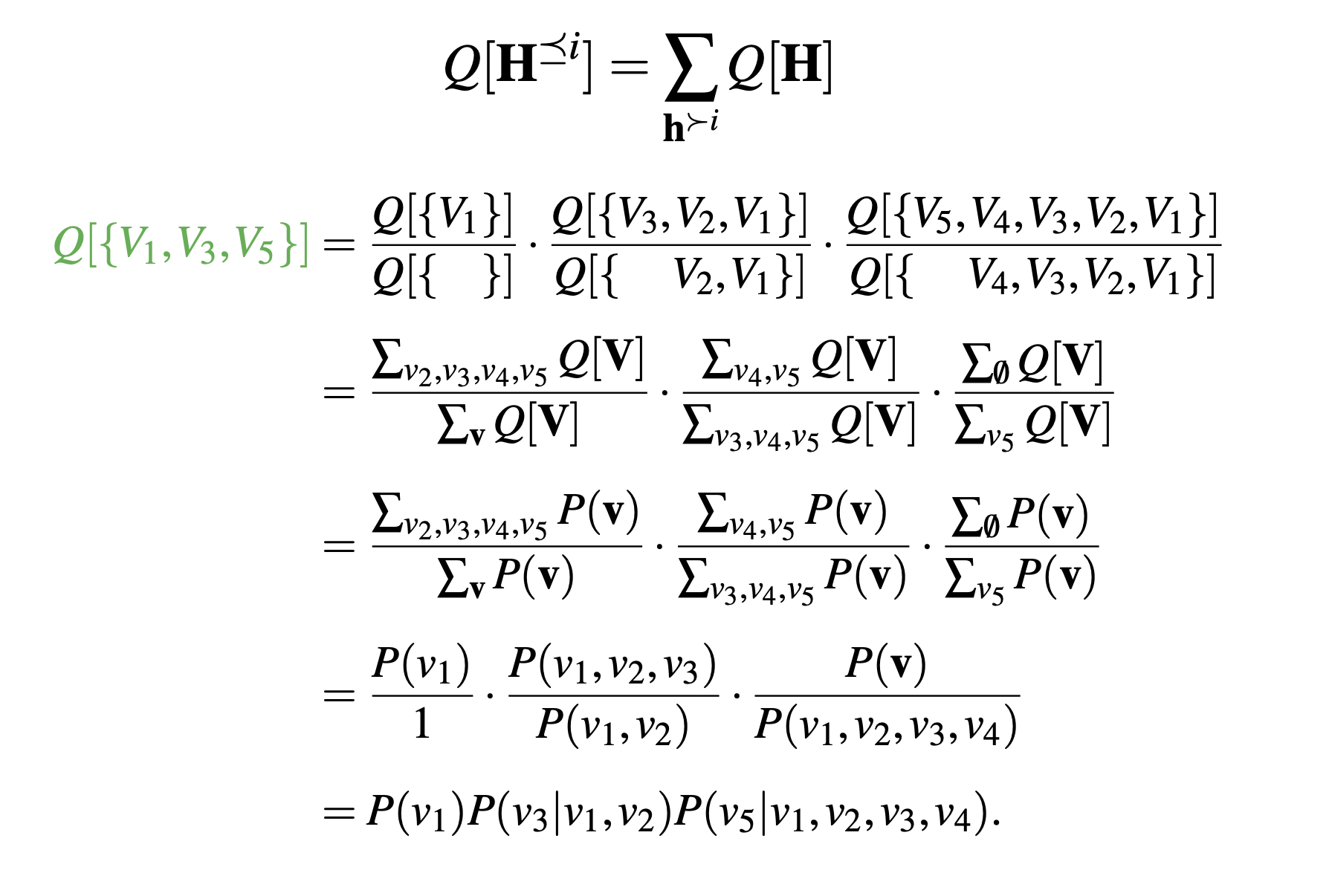1. Factorization
1.1 Truncated Factorization
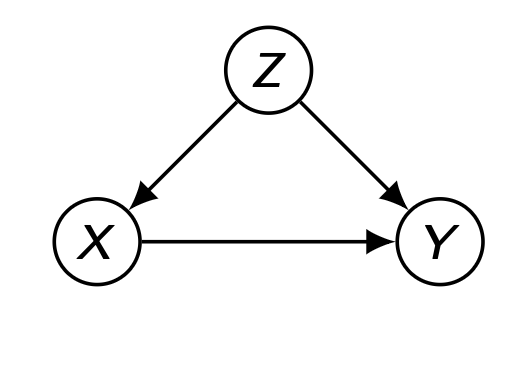
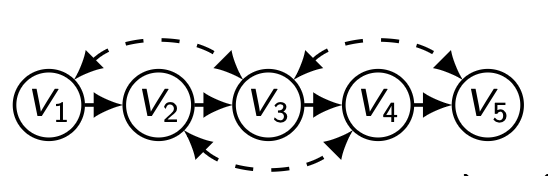
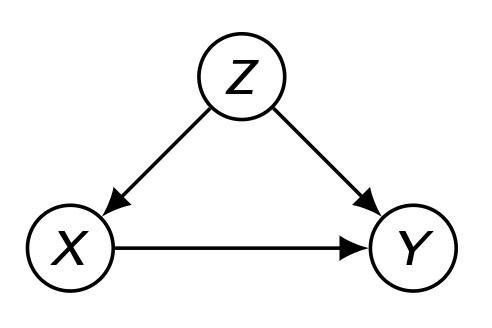
다음과 같은 Markovian Model 상황을 가정하자. 이 경우, Truncated Factorization 에서 unobserved variable을 생략해도 괜찮으며 P ( v i ∣ p a i ) P(v_i|pa_i) P ( v i ∣ p a i )
Truncated Factorization P ( v ) = P ( y ∣ x , z ) P ( x ∣ z ) P ( z ) P(\bold{v})=P(y|x,z)P(x|z)P(z) P ( v ) = P ( y ∣ x , z ) P ( x ∣ z ) P ( z )
하지만 Semi-Markovian 이라면? 위와 같이 P ( v i ∣ p a i ) P(v_i|pa_i) P ( v i ∣ p a i )
1.2 C-factors
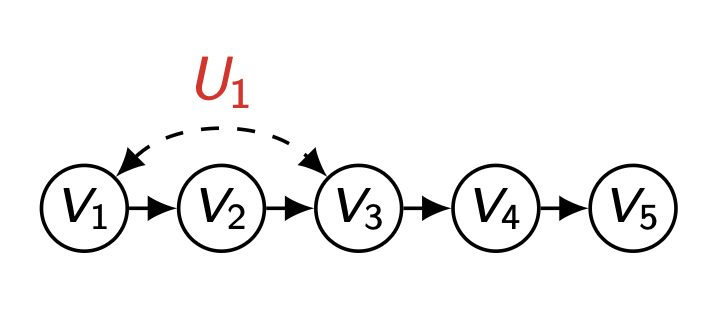
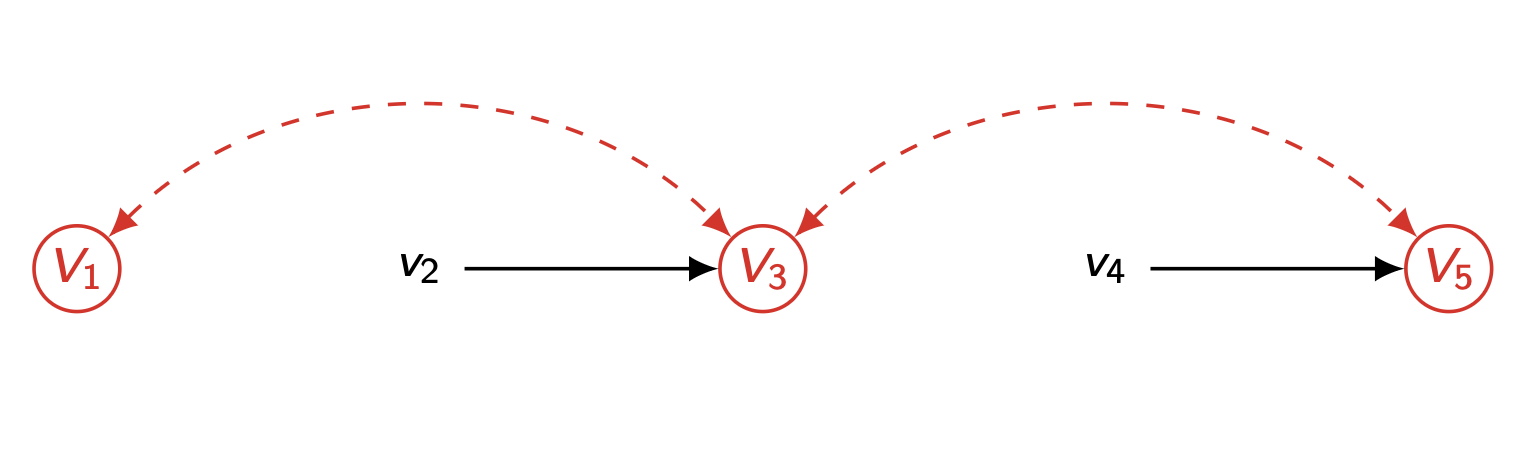
위의 상황과 같은 경우엔 다음과 같이 P(v )를 작성할 수 있다.
P ( v 5 ∣ v 4 ) P ( v 4 ∣ v 3 ) P ( v 2 ∣ v 1 ) ( ∑ u 1 P ( u 1 ) P ( v 3 ∣ v 2 , u 1 ) P ( v 1 ∣ u 1 ) ) P(v_5|v_4)P(v_4|v_3)P(v_2|v_1)(\underset{u_1}{\sum}P(u_1)P(v_3|v_2,u_1)P(v_1|u_1)) P ( v 5 ∣ v 4 ) P ( v 4 ∣ v 3 ) P ( v 2 ∣ v 1 ) ( u 1 ∑ P ( u 1 ) P ( v 3 ∣ v 2 , u 1 ) P ( v 1 ∣ u 1 ) )
이처럼 unobserved confounder 를 공유하는 두 노드 v 1 , v 3 v_1,\,v_3 v 1 , v 3
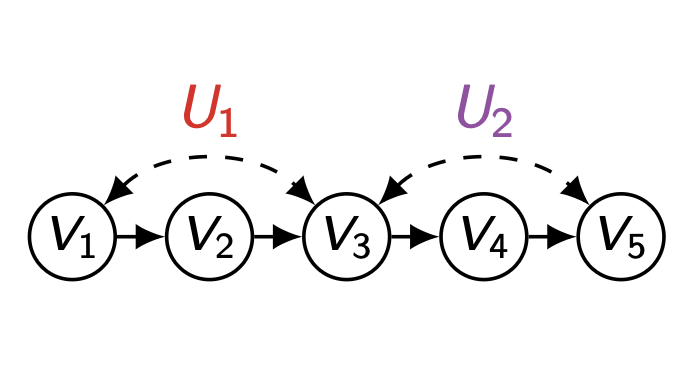
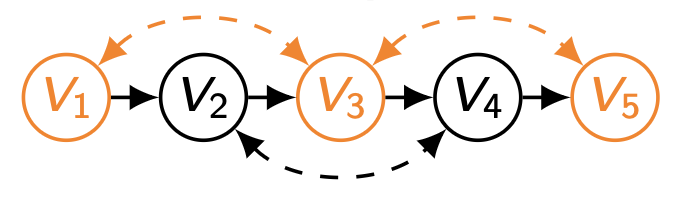
마찬가지로 하나의 unobserved confounder 를 추가한 뒤 P ( v ) P(\bold{v}) P ( v )
P ( v 4 ∣ v 3 ) P ( v 2 ∣ v 1 ) ( ∑ u P ( u ) P ( v 5 ∣ v 4 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 1 ∣ u 1 ) ) P(v_4|v_3)P(v_2|v_1)(\underset{\bold{u}}{\sum}P(\bold{u})P(v_5|v_4,u_2)P(v_3|v_2,u_1,u_2)P(v_1|u_1)) P ( v 4 ∣ v 3 ) P ( v 2 ∣ v 1 ) ( u ∑ P ( u ) P ( v 5 ∣ v 4 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 1 ∣ u 1 ) )
이처럼 v 3 v_3 v 3 u 1 , u 2 u_1,\,u_2 u 1 , u 2
이 경우에서도 앞선 사례들과 유사하게 아래와 같이 계산된다.
( 1 ) = ∑ u 2 P ( u 2 ) P ( v 3 ∣ v 2 , u 1 ) P ( v 1 ∣ u 1 ) ( 2 ) = ∑ u P ( u ) P ( v 5 ∣ v 4 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v ) = ( 1 ) ⋅ ( 2 ) (1)=\underset{u_2}{\sum}P(u_2)P(v_3|v_2,u_1)P(v_1|u_1)\\(2)=\underset{\bold{u}}{\sum}P(\bold{u})P(v_5|v_4,u_2)P(v_3|v_2,u_1,u_2)P(v_1|u_1)\\P(\bold{v})=(1)\cdot(2) ( 1 ) = u 2 ∑ P ( u 2 ) P ( v 3 ∣ v 2 , u 1 ) P ( v 1 ∣ u 1 ) ( 2 ) = u ∑ P ( u ) P ( v 5 ∣ v 4 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v ) = ( 1 ) ⋅ ( 2 )
이처럼, unobserved confounder 에 의해 연결되는 노드들을 기준으로 P ( v ) P(\bold{v}) P ( v ) C-factor 라 부른다.
이와 같은 각각의 factor 들을 편의상 Q [ { V 1 , V 3 , V 5 } ] Q[\{V_1,V_3,V_5\}] Q [ { V 1 , V 3 , V 5 } ] Q [ { V 2 , V 4 } ] Q[\{V_2,V_4\}] Q [ { V 2 , V 4 } ] ( 1 ) , ( 2 ) (1),\,(2) ( 1 ) , ( 2 )
이때, C-factor는 다음과 같이 나타낼 수 있고 C-factor의 정의의 일관성을 위해 우리는 Q [ ∅ ] = 1 Q[\empty]=1 Q [ ∅ ] = 1 V = V ∪ ∅ V=V\cup\empty V = V ∪ ∅ Q [ v ] = Q [ v ] Q [ ∅ ] Q[\bold{v}]=Q[\bold{v}]Q[\empty] Q [ v ] = Q [ v ] Q [ ∅ ]
Q [ v ] = ∑ u P ( u ) ∏ v i ∈ v P ( v i ∣ p a i , u i ) = P ( v ) Q[\bold{v}]=\underset{\bold{u}}{\sum}P(\bold{u})\underset{v_i\in\bold{v}}{\prod}P(v_i|pa_i,u_i)=P(\bold{v}) Q [ v ] = u ∑ P ( u ) v i ∈ v ∏ P ( v i ∣ p a i , u i ) = P ( v )
1.3 C-factors are Causal Effects
C ⊂ V \bold{C}\subset\bold{V} C ⊂ V P ( c ∣ d o ( v \ c ) ) = ∑ u P ( u ) ∏ V i ∈ C P ( v i ∣ p a i , u i ) P(\bold{c}|do(\bold{v\backslash{}c}))=\underset{\bold{u}}{\sum}P(\bold{u})\underset{V_i\in\bold{C}}{\prod}P(v_i|\bold{pa_i,u_i}) P ( c ∣ d o ( v \ c ) ) = u ∑ P ( u ) V i ∈ C ∏ P ( v i ∣ p a i , u i ) Q [ C ] Q[\bold{C}] Q [ C ]
고로, C-factor는 V \bold{V} V C , V \ C \bold{C},\bold{V\backslash{C}} C , V \ C V \ C \bold{V\backslash{C}} V \ C C \bold{C} C 인과 효과 로 해석할 수 있다.
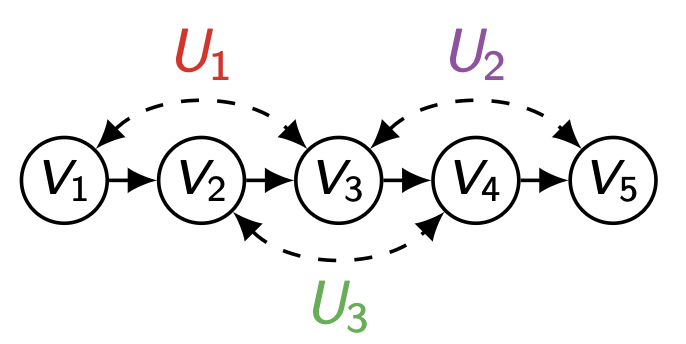
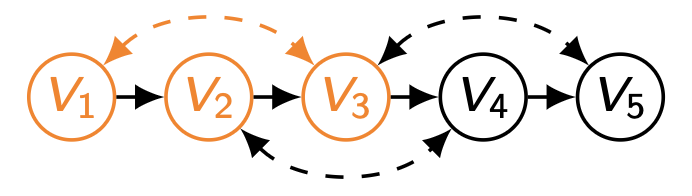
위의 결과를 토대로 Q [ { V 1 , V 3 , V 5 } ] Q[\{V_1,V_3,V_5\}] Q [ { V 1 , V 3 , V 5 } ] G v 2 ˉ , v 4 ˉ G_{\bar{v_2},\bar{v_4}} G v 2 ˉ , v 4 ˉ
2. Marginalizing Variables in C-factors
앞서 살펴본 예시를 기준으로 C-factor 안에서도 Marginalization이 가능한지 살펴보자.
Q [ { V 1 , V 3 , V 5 } ] = ∑ u 1 , u 2 P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 5 ∣ v 4 , u 2 ) Q[\{V_1,V_3,V_5\}]\\=\underset{u_1,u_2}{\sum}P(u_1,u_2)P(v_1|u_1)P(v_3|v_2,u_1,u_2)P (v_5|v_4,u_2)\\ Q [ { V 1 , V 3 , V 5 } ] = u 1 , u 2 ∑ P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 5 ∣ v 4 , u 2 ) ∑ v 3 Q [ { V 1 , V 3 , V 5 } ] = ∑ v 3 ∑ u 1 , u 2 P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 5 ∣ v 4 , u 2 ) = ∑ u 1 , u 2 P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 5 ∣ v 4 , u 2 ) ∑ v 3 P ( v 3 ∣ v 2 , u 1 , u 2 ) = ∑ u 1 , u 2 P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 5 ∣ v 4 , u 2 ) = Q [ { V 1 , V 5 } ] \underset{v_3}{\sum}Q[\{V_1,V_3,V_5\}]\\=\underset{v_3}{\sum}\underset{u_1,u_2}{\sum}P(u_1,u_2)P(v_1|u_1)P(v_3|v_2,u_1,u_2)P(v_5|v_4,u_2)\\=\underset{u_1,u_2}{\sum}P(u_1,u_2)P(v_1|u_1)P(v_5|v_4,u_2)\underset{v_3}{\sum}P(v_3|v_2,u_1,u_2)\\=\underset{u_1,u_2}{\sum}P(u_1,u_2)P(v_1|u_1)P(v_5|v_4,u_2)\\=Q[\{V_1,V_5\}] v 3 ∑ Q [ { V 1 , V 3 , V 5 } ] = v 3 ∑ u 1 , u 2 ∑ P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 5 ∣ v 4 , u 2 ) = u 1 , u 2 ∑ P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 5 ∣ v 4 , u 2 ) v 3 ∑ P ( v 3 ∣ v 2 , u 1 , u 2 ) = u 1 , u 2 ∑ P ( u 1 , u 2 ) P ( v 1 ∣ u 1 ) P ( v 5 ∣ v 4 , u 2 ) = Q [ { V 1 , V 5 } ]
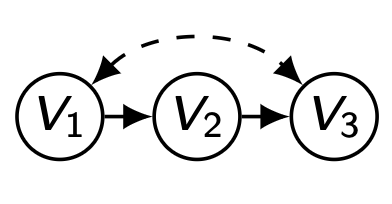
하지만 모든 경우에서 C-factor가 Marginalization 가능한 것은 아니다. 아래의 예를 살펴보자.
∑ v 1 Q [ { V 1 , V 2 , V 3 } ] = ∑ v 1 ∑ u P ( u ) P ( v 1 ∣ u 1 ) P ( v 2 ∣ v 1 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) = ∑ u P ( u ) P ( v 3 ∣ v 2 , u 1 , u 2 ) ∑ v 1 P ( v 1 ∣ u 1 ) P ( v 2 ∣ v 1 , u 2 ) ≠ ∑ u P ( u ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 2 ∣ v 1 , u 3 ) = Q [ { V 1 , V 3 } ] \underset{v_1}{\sum}Q[\{V_1,V_2,V_3\}]\\=\underset{v_1}{\sum}\underset{\bold{u}}{\sum}P(\bold{u})P(v_1|u_1)P(v_2|v_1,u_2)P(v_3|v_2,u_1,u_2)\\=\underset{\bold{u}}{\sum}P(\bold{u})P(v_3|v_2,u_1,u_2)\underset{v_1}{\sum}P(v_1|u_1)P(v_2|v_1,u_2)\\\neq\underset{\bold{u}}{\sum}P(\bold{u})P(v_3|v_2,u_1,u_2)P(v_2|v_1,u_3)\\=Q[\{V_1,V_3\}] v 1 ∑ Q [ { V 1 , V 2 , V 3 } ] = v 1 ∑ u ∑ P ( u ) P ( v 1 ∣ u 1 ) P ( v 2 ∣ v 1 , u 2 ) P ( v 3 ∣ v 2 , u 1 , u 2 ) = u ∑ P ( u ) P ( v 3 ∣ v 2 , u 1 , u 2 ) v 1 ∑ P ( v 1 ∣ u 1 ) P ( v 2 ∣ v 1 , u 2 ) = u ∑ P ( u ) P ( v 3 ∣ v 2 , u 1 , u 2 ) P ( v 2 ∣ v 1 , u 3 ) = Q [ { V 1 , V 3 } ]
그렇다면 어떠한 경우 일 때 C-factor 에서의 Marginalization 이 가능한 것일까?
2.1 Ancestral Reduction
이때, W ⊂ C ⊆ V \bold{W}\subset\bold{C}\subseteq\bold{V} W ⊂ C ⊆ V G \mathcal{G} G G [ C ] \mathcal{G}[\bold{C}] G [ C ] A n ( W ) = W An(\bold{W})=\bold{W} A n ( W ) = W
앞서 살펴본 C = { V 1 , V 3 , V 5 } \bold{C}=\{V_1,V_3,V_5\} C = { V 1 , V 3 , V 5 } W = { V 1 , V 3 } \bold{W}=\{V_1,V_3\} W = { V 1 , V 3 } G [ C ] \mathcal{G}[\bold{C}] G [ C ] A n ( W ) = W An(\bold{W})=\bold{W} A n ( W ) = W
주어진 G [ C ] \mathcal{G}[\bold{C}] G [ C ]
W 1 = { V 1 , V 2 } → A n c e s t r a l \bold{W_1}=\{V_1,V_2\}\rightarrow{Ancestral} W 1 = { V 1 , V 2 } → A n c e s t r a l W 2 = { V 1 } → A n c e s t r a l \bold{W_2}=\{V_1\}\rightarrow{Ancestral} W 2 = { V 1 } → A n c e s t r a l W 3 = { V 2 , V 3 } → A n c e s t r a l \bold{W_3}=\{V_2,V_3\}\cancel{\rightarrow}{Ancestral} W 3 = { V 2 , V 3 } → A n c e s t r a l
이러한 Ancestral Reduction 은 C-factor Algebra 에서 거의 기초에 가깝게 사용되는만큼, sub-model 을 기준에서의 subset 이 Ancestral Set 이기만 하면 된다는 걸 기억해두자.
2.2 Confounded Components (C-Components)
앞서 다룬 예시를 떠올려보자. 이 경우 { V 1 , V 3 , V 5 } , { V 2 , V 4 } \{V_1,V_3,V_5\},\,\{V_2,V_4\} { V 1 , V 3 , V 5 } , { V 2 , V 4 }
이러한 각 집합을 우리는 Confounded Component 라 부른다.
이때, C-component Relation 은 Reflexive, Symmetric, Transitivie 하므로 이산수학에서의 Equivalence Relation 과 동일한 구조라고 생각해볼 수 있다.
2.3 C-Component Factorization
수식만 봐서는 어렵게 느껴질 수 있으나, 요약해서 설명하자면 H \bold{H} H k k k Q [ H ] Q[\bold{H}] Q [ H ]
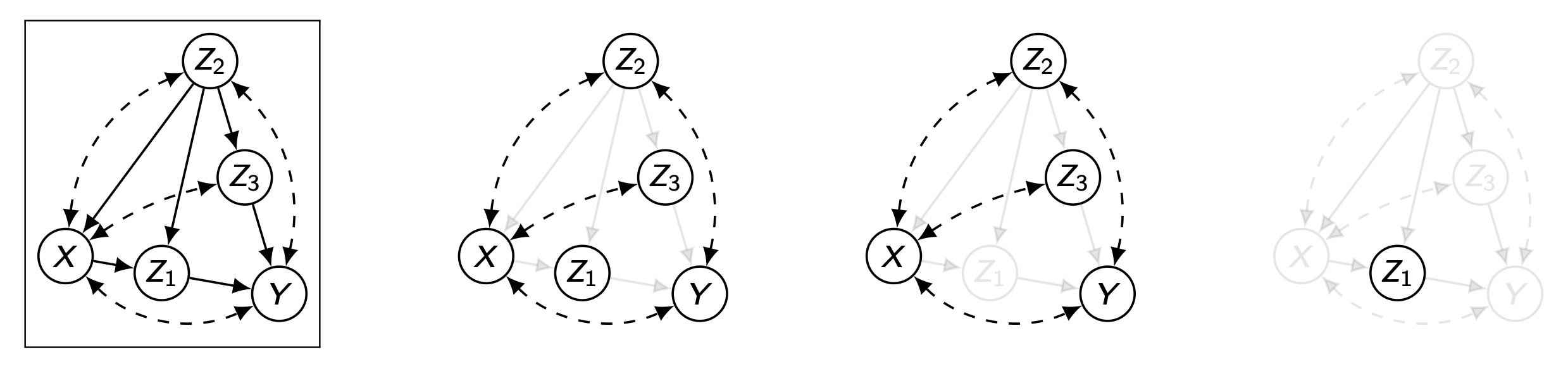
[ Case study ]
여기서 총 두 개의 Confounded Components가 생기고, 이를 위의 C-Component Factorization Lemma를 적용하면 아래와 같이 나타낼 수 있다.
P ( V ) = Q [ V ] = Q [ { X , Z 2 , Z 3 , Y } ] Q [ { Z 1 } ] ) P(\bold{V})=Q[\bold{V}]=Q[\{X,Z_2,Z_3,Y\}]Q[\{Z_1\}]) P ( V ) = Q [ V ] = Q [ { X , Z 2 , Z 3 , Y } ] Q [ { Z 1 } ] )
이때, C-Factor에 대해 다음과 같은 성질이 존재하는데, 우선 H \bold{H} H V \bold{V} V
H \bold{H} H H i \bold{H}_i H i V j ∈ H i V_j\in\bold{H}_i V j ∈ H i Q [ V 1 : j ] / Q [ V 1 : j − 1 ] Q[V_{1:j}]/Q[V_{1:j-1}] Q [ V 1 : j ] / Q [ V 1 : j − 1 ]
이때 각 항을 계산하고자 할 때, 우리는 앞서 다룬 Ancestral Reduction 을 통해 이를 계산한다.
이렇게 글로만 읽었을 때는 잘 와닿지 않을 것이기에, 아래와 같은 예시를 통해 이해해보도록 하자.
[ Case Stduy 1 ]
이때 topological sort를 이용한 ordering 에 맞춰 수식을 전개하므로 ancestral reduction 의 조건은 자동으로 충족되므로 다음과 같이 계산할 수 있다.
[ Case Study 2 ]
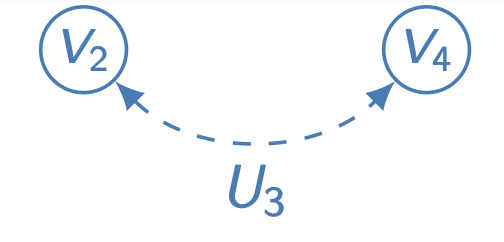
Q [ { V 2 , V 4 } ] Q[\{V_2,V_4\}] Q [ { V 2 , V 4 } ] W = { V 2 } , C = { V 2 , V 4 } \bold{W}=\{V_2\},\,\bold{C}=\{V_2,V_4\} W = { V 2 } , C = { V 2 , V 4 } W \bold{W} W G [ C ] \mathcal{G}[C] G [ C ] Ancestral Set 이다. 고로, Marginalization을 적용할 수 있고, 이는 다음과 같이 표현된다.
Q [ { V 2 , V 4 } ] = Q [ { V 2 , V 1 } ] Q [ { V 1 } ] × Q [ { V 4 , V 3 , V 2 , V 1 } ] Q [ { V 3 , V 2 , V 1 } ] = P ( v 2 ∣ v 1 ) P ( v 4 ∣ v 1 , v 2 , v 3 ) Q[\{V_2,V_4\}]\\={Q[\{V_2,V_1\}]\over{Q[\{V_1\}]}}\times{Q[\{V_4,V_3,V_2,V_1\}]\over{Q[\{V_3,V_2,V_1\}]}}\\=P(v_2|v_1)P(v_4|v_1,v_2,v_3)\\ Q [ { V 2 , V 4 } ] = Q [ { V 1 } ] Q [ { V 2 , V 1 } ] × Q [ { V 3 , V 2 , V 1 } ] Q [ { V 4 , V 3 , V 2 , V 1 } ] = P ( v 2 ∣ v 1 ) P ( v 4 ∣ v 1 , v 2 , v 3 ) Q [ { V 2 } ] = ∑ v 4 Q [ { V 2 , V 4 } ] = P ( v 2 ∣ v 1 ) ∑ v 4 P ( v 4 ∣ v 1 , v 2 , v 3 ) = P ( v 2 ∣ v 1 ) Q[\{V_2\}]\\=\underset{v_4}{\sum}Q[\{V_2,V_4\}]\\=P(v_2|v_1)\underset{v_4}{\sum}P(v_4|v_1,v_2,v_3)\\=P(v_2|v_1) Q [ { V 2 } ] = v 4 ∑ Q [ { V 2 , V 4 } ] = P ( v 2 ∣ v 1 ) v 4 ∑ P ( v 4 ∣ v 1 , v 2 , v 3 ) = P ( v 2 ∣ v 1 )
3. Case Study : C-factor Algebra
3.1 Back-door
우선 주어진 V \bold{V} V { X } , { Y } , { Z } \{X\},\,\{Y\},\,\{Z\} { X } , { Y } , { Z } Q [ V ] = Q [ X ] ⋅ Q [ Y ] ⋅ Q [ Z ] Q[\bold{V}]=Q[\bold{X}]\cdot{Q[\bold{Y}]\cdot{Q}[\bold{Z}]} Q [ V ] = Q [ X ] ⋅ Q [ Y ] ⋅ Q [ Z ]
H = { X , Y , Z } , Z ≺ X ≺ Y \bold{H}=\{X,Y,Z\},\,Z\prec{X}\prec{Y} H = { X , Y , Z } , Z ≺ X ≺ Y Q [ { Y } ] = Q [ { Z , X , Y } ] Q [ { Z . X } ] = P ( y ∣ z , x ) Q[\{Y\}]={Q[\{Z,X,Y\}]\over{Q[\{Z.X\}]}}=P(y|z,x) Q [ { Y } ] = Q [ { Z . X } ] Q [ { Z , X , Y } ] = P ( y ∣ z , x )
P ( y ∣ d o ( x ) ) = ∑ z P ( y , z ∣ d o ( x ) ) = ∑ z Q [ { Y } ] ⋅ Q [ { Z } ] P(y|do(x))=\sum_z{}P(y,z|do(x))=\sum_{z}Q[\{Y\}]\cdot{}Q[\{Z\}] P ( y ∣ d o ( x ) ) = ∑ z P ( y , z ∣ d o ( x ) ) = ∑ z Q [ { Y } ] ⋅ Q [ { Z } ] Q [ { Z } ] Q[\{Z\}] Q [ { Z } ] C = { Z , X , Y } \bold{C}=\{Z,X,Y\} C = { Z , X , Y } P ( z ) P(z) P ( z )
곧, P ( y ∣ d o ( x ) ) = ∑ z Q [ { Y } ] ⋅ Q [ { Z } ] = ∑ z P ( z ) P ( y ∣ z , x ) P(y|do(x))=\underset{z}{\sum}Q[\{Y\}]\cdot{}Q[\{Z\}]=\underset{z}{\sum}P(z)P(y|z,x) P ( y ∣ d o ( x ) ) = z ∑ Q [ { Y } ] ⋅ Q [ { Z } ] = z ∑ P ( z ) P ( y ∣ z , x )
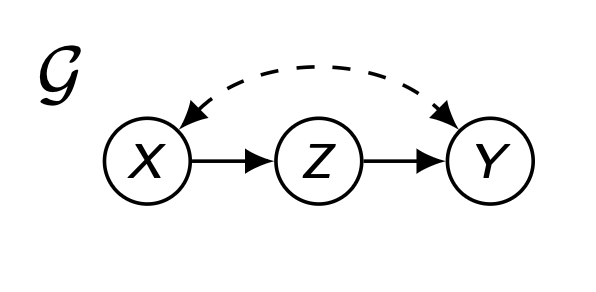
3.2 Front-door
P ( v ) = Q [ v ] = Q [ X , Y ] ⋅ Q [ Z ] ( ∵ P(\bold{v})=Q[\bold{v}]=Q[X,Y]\cdot{}Q[Z](\because P ( v ) = Q [ v ] = Q [ X , Y ] ⋅ Q [ Z ] ( ∵ ) ) )
P ( y ∣ d o ( x ) ) = ∑ z Q [ Y , Z ] = ∑ z Q [ Y ] ⋅ Q [ Z ] P(y|do(x))=\underset{z}{\sum}Q[Y,Z]=\underset{z}{\sum}Q[Y]\cdot{}Q[Z] P ( y ∣ d o ( x ) ) = z ∑ Q [ Y , Z ] = z ∑ Q [ Y ] ⋅ Q [ Z ]
이때, Q [ Y ] Q[Y] Q [ Y ] C = { X , Y } \bold{C}=\{X,Y\} C = { X , Y } W = { Y } \bold{W}=\{Y\} W = { Y } Ancestral Set 이므로 Q [ Y ] = ∑ x Q [ X , Y ] = ∑ x Q [ X ] Q [ ∅ ] ⋅ Q [ X , Z , Y ] Q [ X , Z ] = ∑ x P ( x ) P ( y ∣ x , z ) Q[Y]=\underset{x}{\sum}Q[X,Y]=\underset{x}{\sum}{Q[X]\over{Q[\empty]}}\cdot{Q[X,Z,Y]\over{}Q[X,Z]}=\underset{x}{\sum}P(x)P(y|x,z) Q [ Y ] = x ∑ Q [ X , Y ] = x ∑ Q [ ∅ ] Q [ X ] ⋅ Q [ X , Z ] Q [ X , Z , Y ] = x ∑ P ( x ) P ( y ∣ x , z )
H = { X , Z , Y } \bold{H}=\{X,Z,Y\} H = { X , Z , Y } Q [ Z ] = Q [ X , Z ] Q [ X ] = P ( z ∣ x ) Q[Z]={Q[X,Z]\over{}Q[X]}=P(z|x) Q [ Z ] = Q [ X ] Q [ X , Z ] = P ( z ∣ x )
P ( y ∣ d o ( x ) ) = ∑ z P ( z ∣ x ) ∑ x ′ P ( x ′ ) P ( y ∣ x ′ , z ) P(y|do(x))=\underset{z}{\sum}P(z|x)\underset{x^\prime}{\sum}P(x^\prime)P(y|x^\prime,z) P ( y ∣ d o ( x ) ) = z ∑ P ( z ∣ x ) x ′ ∑ P ( x ′ ) P ( y ∣ x ′ , z )
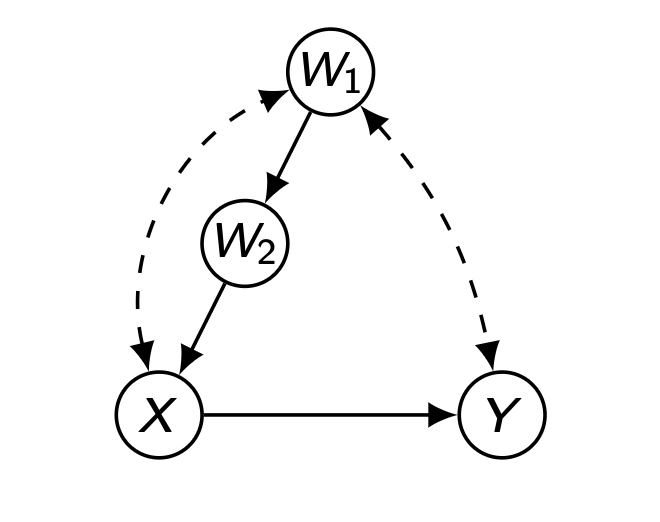
3.3 Napkin
P ( v ) = Q [ X , W 1 , Y ] ⋅ Q [ W 2 ] P(\bold{v})=Q[X,W_1,Y]\cdot{}Q[W_2] P ( v ) = Q [ X , W 1 , Y ] ⋅ Q [ W 2 ] P ( y ∣ d o ( x ) ) = ∑ w 1 , w 2 Q [ W 1 , W 2 , Y ] P(y|do(x))=\underset{w_1,w_2}{\sum}Q[W_1,W_2,Y] P ( y ∣ d o ( x ) ) = w 1 , w 2 ∑ Q [ W 1 , W 2 , Y ]
P ( y ∣ d o ( x ) ) = ∑ w 1 , w 2 Q [ W 1 , Y ] ⋅ Q [ W 2 ] = ∑ w 2 Q [ W 2 ] ∑ w 1 Q [ W 1 , Y ] = ∑ w 2 Q [ W 2 ] Q [ Y ] P(y|do(x))\\=\underset{w_1,w_2}{\sum}Q[W_1,Y]\cdot{}Q[W_2]\\=\underset{w_2}{\sum}Q[W_2]\underset{w_1}{\sum}Q[W_1,Y]\\=\underset{w_2}{\sum}Q[W_2]Q[Y] P ( y ∣ d o ( x ) ) = w 1 , w 2 ∑ Q [ W 1 , Y ] ⋅ Q [ W 2 ] = w 2 ∑ Q [ W 2 ] w 1 ∑ Q [ W 1 , Y ] = w 2 ∑ Q [ W 2 ] Q [ Y ]
이때, Q [ W 2 ] = P ( w 2 ∣ w 1 ) ( ∵ M a r g i n a l i z a t i o n ) Q[W_2]=P(w_2|w_1)(\because{}Marginalization) Q [ W 2 ] = P ( w 2 ∣ w 1 ) ( ∵ M a r g i n a l i z a t i o n )
그렇다면 Q [ Y ] Q[Y] Q [ Y ] H = { X , Y } \bold{H}=\{X,Y\} H = { X , Y } X , Y X,\,Y X , Y
그에 따라, Q [ Y ] = Q [ X , Y ] Q [ X ] , Q [ X , Y ] = ∑ w 1 P ( w 1 ) P ( x ∣ w 1 , w 2 ) P ( y ∣ w 1 , w 2 , x ) Q[Y]={Q[X,Y]\over{}Q[X]},\\Q[X,Y]=\underset{w_1}{\sum}P(w_1)P(x|w_1,w_2)P(y|w_1,w_2,x) Q [ Y ] = Q [ X ] Q [ X , Y ] , Q [ X , Y ] = w 1 ∑ P ( w 1 ) P ( x ∣ w 1 , w 2 ) P ( y ∣ w 1 , w 2 , x ) X ≺ Y ≺ W 1 X\prec{Y}\prec{}W_1 X ≺ Y ≺ W 1
마찬가지로 ancestral reduction 에 의해 Q [ X ] = ∑ y Q [ X , Y ] Q[X]=\underset{y}{\sum}{Q[X,Y]} Q [ X ] = y ∑ Q [ X , Y ] P ( y ∣ d o ( x ) ) P(y|do(x)) P ( y ∣ d o ( x ) )
4. General Identificaion Algorithm
우선 처음의 P ( y ∣ d o ( x ) ) = ∑ v \ ( x ∪ y ) Q [ V \ X ] P(y|do(x))=\underset{\bold{v}\backslash(\bold{x}\cup\bold{y})}{\sum}Q[\bold{V}\backslash\bold{X}] P ( y ∣ d o ( x ) ) = v \ ( x ∪ y ) ∑ Q [ V \ X ] 당연한 이야기다.
그렇지만 v \ x ∪ y \bold{v}\backslash{\bold{x\cup{}y}} v \ x ∪ y
이를 이용하여 다음과 같이 재귀적인 identify 알고리즘을 구성할 수 있고, 다음과 같은 정리가 성립한다.