1. Truncated Factorization in Semi-Markovian Models
앞서 다룬 Markovian Model들은 모두 identifiable 하며, 이 경우 P(vi∣pai,ui)=P(vi∣pai) 로 줄여서 표현할 수 있었다.
하지만 Semi-Markovian, 즉 unobserved confounder가 존재하는 상황에선 과연 어떠한가? 이러한 Semi-Markovian Model은 위와 같은 방식으로 축약할 수 없고 아래와 같이 기술된다.
P(v′∣do(x))=u∑Vi∈V\X∏P(vi∣pai,ui)P(u)
Recap
do-operation 으로 인해 P(x|pa, u) 가 1로 고정이 된 것. (생성 함수가 상수 함수로 고정)
이때, Marginalization 처리하여 P(y∣do(x))를 계산하면 아래와 같다.
P(y∣do(x))=v\x\y∑u∑Vi∈V\X∏P(vi∣pai,ui)P(u)
세 가지 Semi-Markovian 그래프들을 보고, 이들의 causal effect 가 어떻게 계산되는지 확인해보도록 하자.
Example 1 : Back-door Graph
Computation of Causal Effect P(v′∣do(x))=u∑P(z∣uz)P(y∣x,z,uy)P(u)=uz∑P(z∣uz)P(uz)uy∑P(uy∣x,z)P(y∣x,z,uy)ux∑P(ux)=P(z)P(y∣x,z)(Adjustment Formula)
Example 2 : Bow Graph
Computation of Causal Effect P(v′∣do(x))=u∑P(x∣u′,ux)P(y∣x,u′,uy)P(u)
Example 3 : Front-door Case
Computation of Causal Effect P(v∣do(x))=u∑P(u)P(z∣x,uz)P(y∣z,u′,uu)=ux∑uy∑uz∑P(u′)P(ux)P(uy)P(uz)P(z∣x,uz)P(y∣z,u′,uy)=uy∑P(u′)P(uy)P(y∣z,u′,uy)uz∑P(uz∣x)P(z∣x,uz)ux∑P(ux)=P(z∣x)uy∑P(u′)P(uy∣u′)P(y∣z,uy,u′)=...
이런 식으로 지나치게 계산량이 많고 복잡해짐. 간단하게 계산할 수 없을까?
2. Identification Approaches
Back-door 이든 Front-door 이든 결국 우리의 목표는 P(y∣do(x))를 P(V)만으로 계산하는 것이다.
두 가지 방법이 있는데, 앞서 했던 것과 같이 truincated factorization을 사용하여 U가 없는(U-free) 표현으로 바꾸는 것이고, 나머지 하나는 U와 do-operator 없이 식을 전개해나가는 것이다.
2.1 Insights for Do-Calculus
수식을 설명하기에 앞서 총 세 가지의 직관을 짚고 넘어갈 필요가 있다.
Insight 1 :
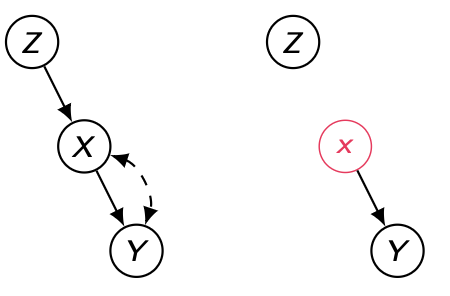
독립 사건은 조건으로 있어도 없어도 똑같다. do(x) 연산을 수행한다는 것은 곧 X로의 incoming edge 를 끊어버리는 것으로, 원래라면 Z와 Y는 서로 종속 변수로서 존재하며 X를 given으로 하더라도 Collider 구조로 인해 proper non-causal path가 존재했다.
하지만 Do-operation 이후에는 Z와 Y는 서로 독립이므로, 생략할 수 있다.
Claim (Z⊥Y∣X)GXˉ⇒P(y∣do(x),z)=P(y∣do(x)) Proof P(y,z∣do(x))=u∑P(z∣uz)P(y∣x,uy,u′)P(u)=P(z)u′∑P(u′)P(y∣u′,x)
이를 이용하여 아래와 같은 두 식이 성립함을 보일 수 있다. P(z∣do(x))=P(z)u′∑P(u′)y∑P(y∣u′,x)=P(z) P(y∣do(x))=u′∑P(u′)P(y∣u′,x) P(y∣do(x),z)=u′∑P(u′)P(y∣u′,x) ∴(Y⊥Z∣X)GXˉ
Insight 2 :
Proper Non-causal Path 가 없다면 Intervention 과 Observation 확률은 동일하다
주어진 조건 하에서 Proper Non-causal Path가 존재하지 않는다면 상관관계(Correlative)를 유발 시키는 confounder 의 효과를 전부 차단 한 것으로 생각해볼 수 있다. 그렇기에 관찰한다는 것은 proper causal path의 효과, 즉 인과 효과만을 관찰하는 것이라 할 수 있다.
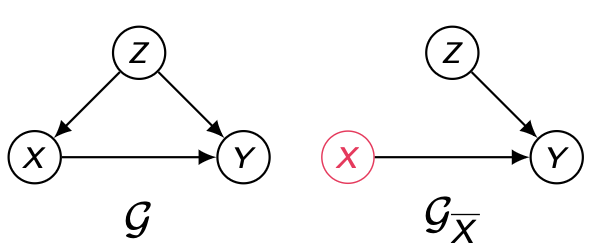
Claim (Y⊥X∣Z)G_X⇒P(y∣do(x),z)=P(y∣x,z)
여기서 G_X는 기존 그래프에서 X에서 Y로 가는 proper causal path를 차단한 것 Proof P(y∣do(x),z)=u∑P(u)P(y∣x,z,uY)=uY∑P(uY∣x,z)P(y∣x,z,uY)uX∑P(uX)uZ∑P(uZ)=uY∑P(y,uY∣x,z)⋅1⋅1=P(y∣x,z)
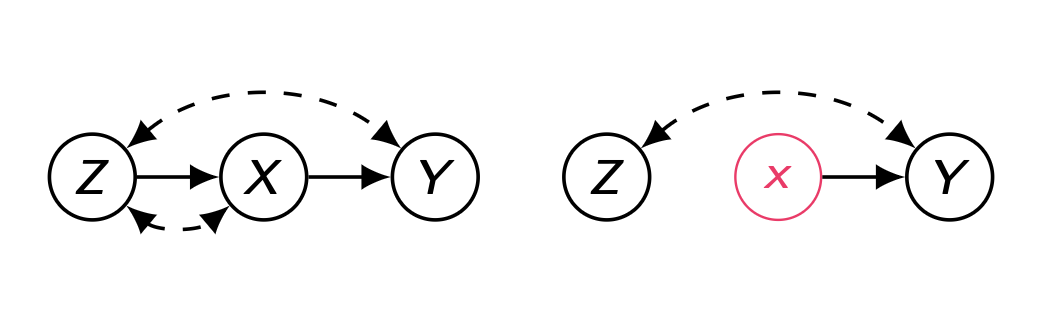
Insight 3 : Proper causal path가 없다면 do-operation을 추가하든 제거하든 확률은 변하지 않는다.
결국 Do-operation을 수행한다는 것은 어떤 변수 X의 직접적인 인과 효과만을 추정하겠다는 것으로, do-operation으로 인해 X의 incoming edge 가 전부 pruning 되기에 애초부터 인과 효과가 존재하지 않는다면 do-operation을 수행하든 수행하지 않든 간에 아무런 효과도 없다는 것이다.
앞서 다룬 세 개의 관점을 일반화 시킨다면 위와 같이 정리할 수 있다. 직관적으로 이를 풀어서 설명하자면 아래와 같다.
첫번째 규칙은 do(x) 연산으로 인해 변형된 그래프 상에서 proper causal path든 proper non-causal path든 간에 경로가 존재하지 않는다면 곧 y와 z는 해당 그래프 상에서 독립이기에 z 변수를 조건에서 제거하거나 추가할 수 있다는 것이다.
두번째 규칙은 X를 intervention 한 그래프 상에서 Z에서 Y로의 인과 경로를 끊었을 때, Z에서 Y로의 confounder의 효과는 이미 X에 intervention 을 한 결과로 인해 proper non-causal path가 존재하지 않기(d-separated) 때문에, 관찰을 통해 인과 효과만을 확인할 수 있다는 것이다.
세번째 규칙은 Do-operation을 한다는 것은 순전히 인과 효과만을 관찰하겠다는 것으로, do(x) 세계에서 Z에서 Y로 가는 proper causal path가 존재하지 않으면 애초에 인과효과가 없기에 조건문에서 do(z)를 제거하든 추가하든 확률 분포에 변화가 없다는 것이다.
이를 확장하면 다음과 같은데, 결국 위에서 설명했던 것과 별반 다르지 않다. 단지 조건을 더 추가했을 때도 성립함을 보이는 정도이다.
첫번째, Z와 Y가 주어진 do(x)-world 에서 w가 given일 때 d-separated 라면 조건부 독립이므로 고려하지 않아도 된다는 것.
두번째, do(x)-world 에서 w가 주어짐으로서 proper non-causal path가 d-separated 되어 있다면 관찰을 통해 인과효과만을 추정할 수 있다는 것.
세번째, do(x)-world 에서 w가 주어진 상황에서 Z에서 Y로 가는 인과 경로가 존재하지 않거나 d-separated 되어 있어야 한다는 것.
하지만 세번째 규칙은 이렇게만 이해하면 문제가 발생할 수 있다. 다음과 같은 사례를 살펴보자.
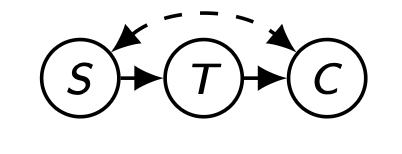
Z→WY←C→Z
이 경우, Z에서 Y로 가는 인과 경로는 존재하지 않는다. 하지만 Z가 W의 조상이게 되면, W가 주어졌을 때 W←Z←C→Y 라고 하는 proper non-causal path가 발생하게 된다. 이 경우에 W에 대한 정보를 안다는 것은 Y에 대한 간접적인 정보를 아는 것과 동일하기에 P(Y|w)와 P(Y|w, do(z))는 같지 않다.
그렇기에 단순하게 인과 경로의 유무로만 Rule 3의 적용 가능성을 검토해서는 안 되며, W가 Z의 자손이라면 Z의 경우 인과 경로 뿐 아니라 비인과 경로에서도 Y와 d-separated 되어 있는지 확인해야 한다.
2.4 Do-Calculus & Identification
이 정리는 쉽게 말해, 확률의 공리 (Marginalization 등)와 Do-Calculus 의 순열로 do가 없는 표현으로, 곧 P(v) 의 항들만으로 표현 가능할 때 identifiable 하고, 역으로 identifiable 하면 확률의 공리와 do-calculus 만으로 이를 구할 수 있다는 것이다.
Example : Front-door Goal : P(c∣do(s))=t∑P(c,t∣do(s))(∵Marginalization)=t∑P(c∣do(s),t)P(t∣do(s))(∵ProductRule)=t∑P(c∣do(s),t)P(t∣s)(∵Rule2)=t∑P(c∣do(s),do(t))P(t∣s)(∵Rule2)=t∑P(c∣do(t))P(t∣s)(∵Rule3)=t∑P(t∣s)s′∑P(c,s′∣do(t))(∵Marginalization)=t∑P(t∣s)s′∑P(c∣do(t),s′)P(s′∣do(t))(∵ProductRule)=t∑P(t∣s)s′∑P(c∣t,s′)P(s′∣do(t))(∵Rule2)=t∑P(t∣s)s′∑P(c∣t,s′)P(s′)(∵Rule3)
Identifiability 와 관련해서, 다음의 두 가지가 증명되어 있다.
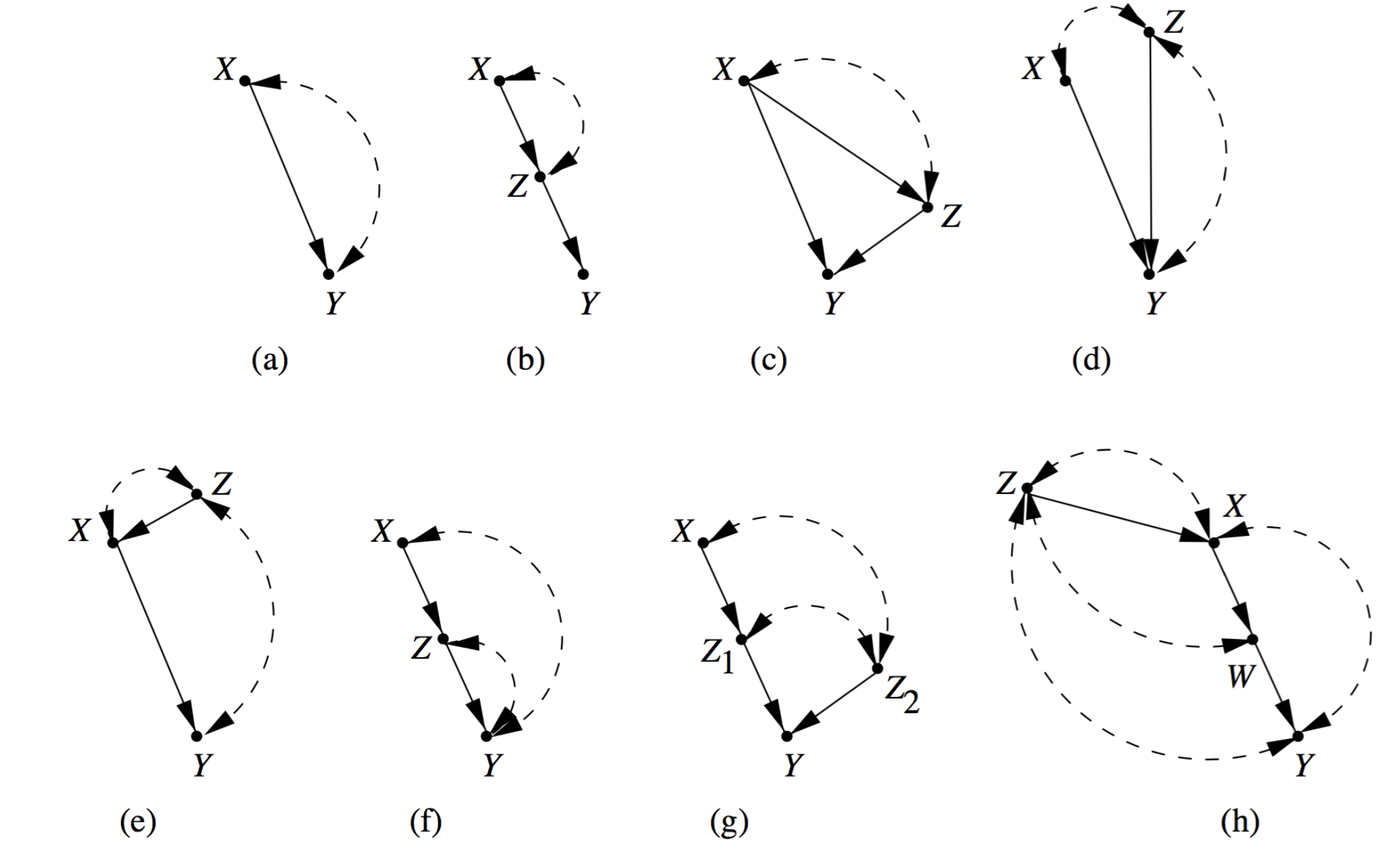
하지만 여전히 식별 가능성 문제는 어려운 문제로, 위의 조건을 만족하지 않는다고 하더라도 non-identifiable 한 경우가 발생한다. (곧, 충분 조건이지 필요 충분 조건이 아니라는 것)
위의 경우와 같이 (c), (d)를 보면 이를 쉽게 알 수 있다.
마지막으로, Simpson's Paradox는 do-operation을 통해 identifiable 하다면 confouding bias를 제거하여 해결 가능하며 Sure Thing Principle 에 따라, 모든 부분 집단에 대해 X라는 treatment가 Y를 증가 시킨다면 마찬가지로 전체 집단에 대해서도 Y를 증가시킨다는, 당연한 정리로 이 단원을 마무리 지을 수 있다.