1. Identifiability Problem
Markovian Model 에서는 우리가 identifiable 함을 알고 있으나, unobserved confounder 가 존재한다고 하더라도 non-causal path를 차단할 수 있다면 causal effect 를 계산할 수 잇음을 알아보았다.
하지만 우리가 모든 Semi-Markovian 상황에서도 causal effect 를 계산할 수 있는 것은 아니다.
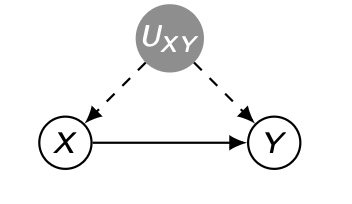
위의 그림과 같이 X와 Y에 대해 Unobserved confounder U가 존재한다고 하자. 직관적으로만 생각해보았을 때, 라는 non-causal path를 차단할 수 없으므로 adjustment formula 를 사용할 수 없으며, 다른 변수들에 대해 condition 할수조차 없는 상황이다.
그렇기에 위의 경우는 Non-identifiable 하다.
(counterexample 을 통해 보여줄 수 있으나 정성적 이해가 더 중요하다고 판단하였다.)
1.1 Confounding Bias
실제 데이터를 분석할 때도 위와 같은 문제는 빈번하게 발생한다. 다음과 같은 경우를 생각해보자.
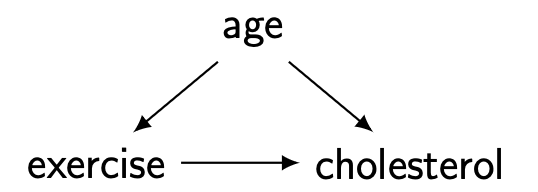
일반적으로 사람들은 나이를 먹으면 건강 관리를 위해 운동을 하고, 나이를 먹으면 심혈관계 질환 등 여러 문제가 누적되어 가며 콜레스테롤이 증가할 것이다.
만약 우리의 데이터셋 상에서 Age가 unobserved confounder 라면 어떻게 될까?
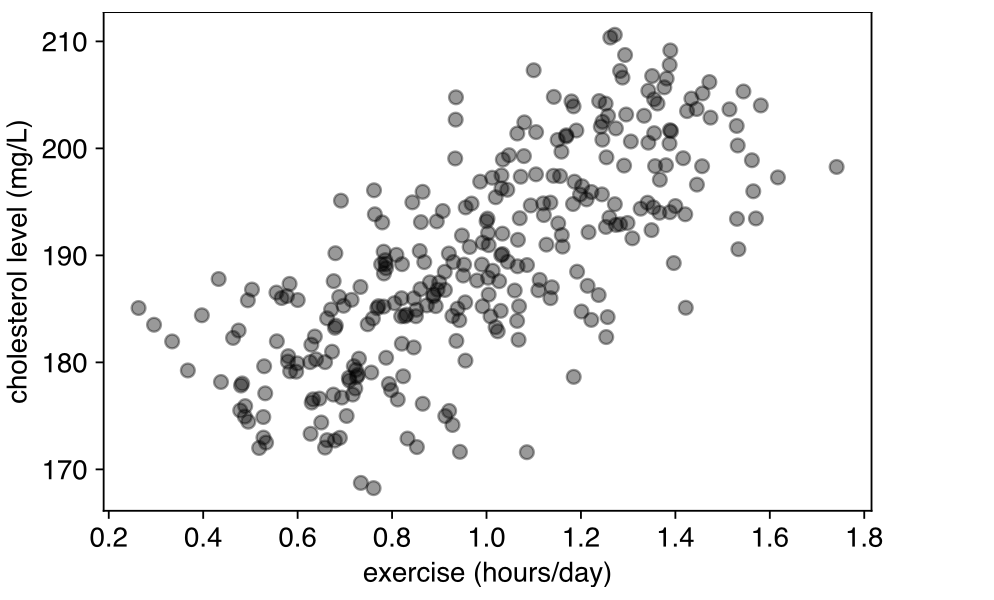
우리의 직관과는 맞지 않는, 콜레스테롤과 운동량이 양의 상관관계를 가진다고 결과를 내리게 될 것이다. 이를 계량 경제학에서의 용어로는 Spurious Regression이라 부른다.
만약 우리가 나이 정보를 추가로 알고 있다면?
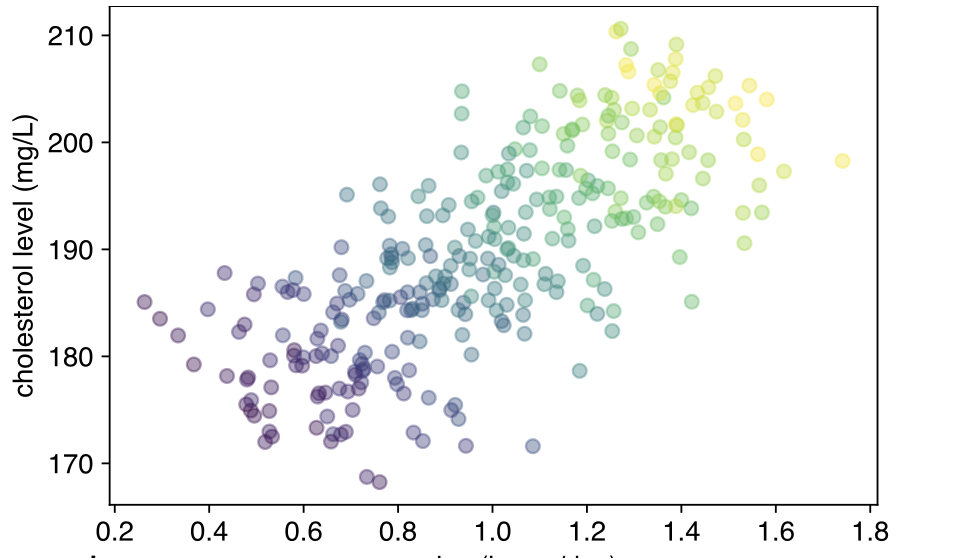
위에서 색깔은 곧 연령대로, 동일 내지는 유사한 색상군을 기준으로, 운동과 콜레스테롤 수치는 음의 상관 관계를 가지는 것을 알 수 있다.
위와 같이, 인 이런 확률 분포의 차이를 confounding bias라 부르며, 인과추론과 해석의 가장 주요한 방해 중 하나이다.
그렇다면 Confounding bias는 제거 가능한가? 다음과 같은 그래프가 주어지고 변수 X에 대한 부모 변수들의 값 중 하나를 관측하지 못했다고 가정해보자.
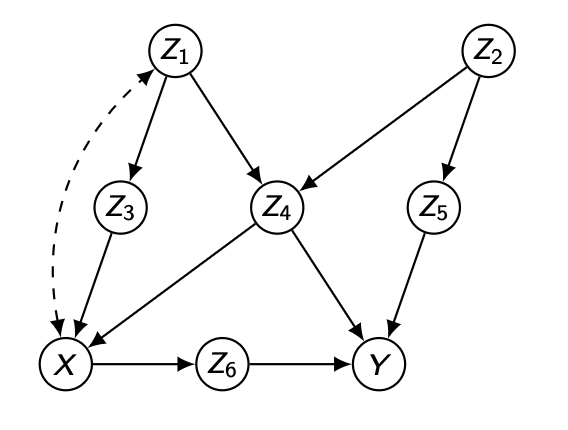
앞서 다룬 Direct Parents 에서 나아가, 우리는 backdoor path만 잘 차단해주면 confounding bias를 제거할 수 있음을 보여줄 것이다.
2. Back-door Criterion
2.1 Definition & Identifiability

직관적으로 이해해보자면, 어떠한 변수 집합 Z의 원소들이 X에서 Y로 가는 non-causal path를 전부 차단할 수 있다면 confounding bias를 전부 제거 가능하고 X에서 Y로의 인과효과를 Adjustment formula 형태로 계산할 수 있다는 것이다.
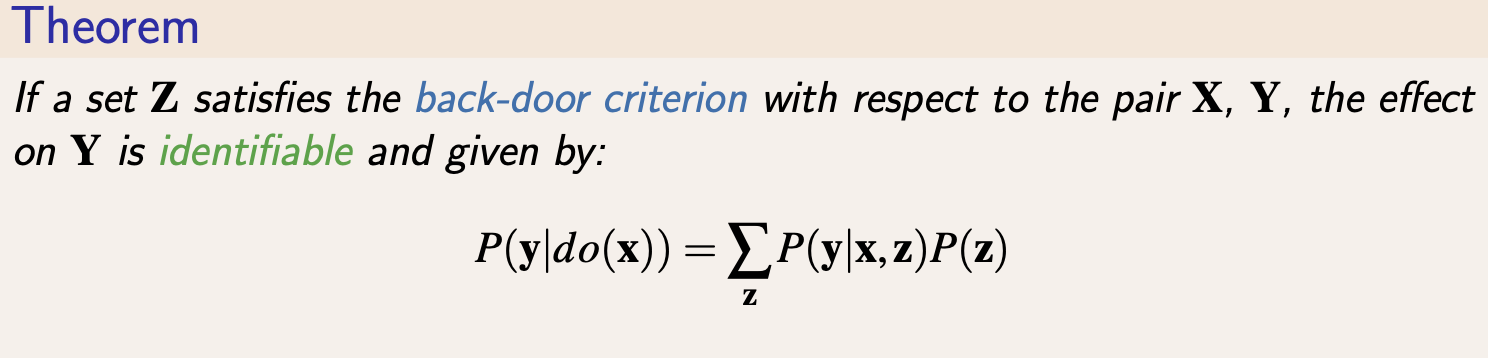
여기서 다루지 않지만, confounding bias를 제거하기 위해 front-door criterion 도 존재하는만큼 back-door criterion은 identifiability의 충분조건이지만 필요충분 조건은 아니다.
(심지어 Adjustment formula를 쓰기 위한 필요 충분 조건조차 아니다. 단지 충분 조건)
2.2 Case Study : Back to Sprinkler
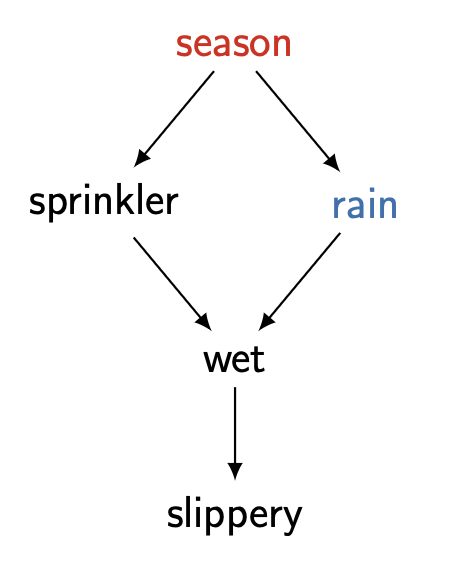
앞서 우리가 배운 direct parens는 back-door critertion 의 (i) Sprinkler 의 자손이 아님과 (ii)Sprinkler로 가는 간선을 포함하는 모든 경로를 차단하기에 Back-door criterion을 만족한다.
마찬가지로 Sprinkler에서 wet으로 가는 non-causal path를 rain 또한 의 triplet을 in-active 하게 만들기에 back-door criterion을 만족한다.
두 변수 모두 Adjustment formula 형태로 causal effect를 계산하는 데에 사용될 수 있다.
2.3 Evaluating Back-door Adjustment
실무적으로 Back-door Critertion을 만족한다 하더라도 변수 집합 Z를 이용하여 인과 효과를 계산하는 건 비용이 만만치 않다.
첫째, 라고 하는 두 개의 다른 확률 분포를 추정해야 한다.
둘째, Z의 변수가 많다면, 곧 Z의 차원이 높다고 한다면 O(exp|Z|)의 시간 복잡도로 계산해야 한다.
곧, 실무적으로 사용할 수 없다. 그렇다면 우린 이 문제를 어떻게 해결할 것인가?
앞서 보았던 수식을 변형해보도록 하자.
Inverse Probablity Weightiing
이 경우, 두 확률 분포를 계산할 필요도 없이 P(x|z)만 계산하면 되고, 분모의 경우 P(v)이므로 observation data 를 통해 바로 알아낼 수 있다.
그렇다면 실제론 이를 어떻게 측정할 것인가?
여기서 우린 Sampled-based estimation을 수행한다.
(강화학습에서도 많이들 이렇게 처리한다. 결국 모집단 전체를 볼 수 없기 때문)
곧, 원래라면 확률 분포를 계산해야 할 문제를 단순하게 표본 수를 세는 것만으로도 풀 수 있도록 바꾸는 것. (물론 P(x|z) 의 경우, logistic regression 등으로 계산할 필요 O)
이를 통해 실무적ㅇ로도 back-door criterion을 만족함을 안다면 효율적으로 계산할 수 있음을 알 수 있다.
