Hyper Parameter Tuning에 들어가기 앞서, 과대적합에 대해 알아보자.
일반화 (Generalization)
- 모델이 새로운 데이터셋(Test 데이터)에 대한 예측 성능이 좋은 것을 말한다. (새로운 데이터에 잘 맞추는 것)
- 모델이 훈련 데이터로 예측한 결과와 테스트 데이터로 예측한 결과에 차이가 거의 없고 좋은 평가지표를 보여준다.
과대적합 (Overfitting) ("과적합"이라고도 많이 쓴다)
- 모델이 훈련 데이터에 대한 예측은 너무 좋지만 새로운 데이터(Test data)에서는 그 정도 성능이 안나오는 것을 말한다.
- 모델이 훈련 데이터에 너무 맞춰서 학습 했기 때문에 새로운 데이터셋(Test set)에 대한 성능이 떨어진다.
- 학습한 데이터를 가지고는 예측 결과가 잘 나오지만, 새로운 데이터에 대한 예측 능력이 떨어진다.
과소적합 (Underfitting)
- 모델이 훈련 데이터과 테스트 데이터셋 모두에서 성능이 않좋은 것.
- 학습 데이터로 점수가 잘 안나오고, 새로운 데이터와도 잘 안 맞는 것.
과대적합(Overfitting)의 원인
- 모델이 너무 복잡한 경우
- 과대적합(Overfitting)을 줄이기 위한 규제 하이퍼파라미터 설정
- Feature 개수 줄이기 - 데이터의 질이 않좋은 경우 (노이즈들이 껴 있는 경우)
- 질 좋은 데이터를 만든다. => 데이터 전처리 (ex. 이상치를 과감하게 버릴 땐 버리기)
- 데이터를 더 수집한다. (시간과 돈이 더 들어가겠지만) 데이터가 많으면 많을수록 오차나 노이즈가 상쇄가 되기 때문이다.
위스콘신 유방암 데이터셋
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
pred_train = tree.predict(X_train)
pred_test = tree.predict(X_test)from sklearn.metrics import accuracy_score
accuracy_score(y_train, pred_train), accuracy_score(y_test, pred_test)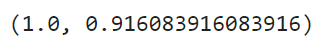
tree.predict(X_train)[:15] #이건 예측 결과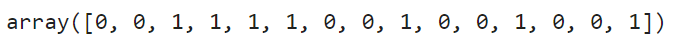
- DecisionTree model의 장점 중 하나로, DecisionTree를 통해 어떤 결과를 내었을 때 결과가 나온 조건들이 있을텐데(조건을 가지고 계속 가지를 쳐나가는 것), 이것들을 그래프적으로 볼 수 있다는 것이다.
- GraphViz를 사용하여 어떻게 내부적으로 그렇게 되었는지, 찾아나갔는지를, 어떤 조건을 가지고 분리해 나갔는지를 알 수 있다.
#tree model만 graphviz를 통해 시각화 할 수 있다
from sklearn.tree import export_graphviz
from graphviz import Source
from IPython.display import SVG
graph = Source(export_graphviz(tree #tree - 모델을 알려준 것
, out_file = None
, feature_names = cancer.feature_names #feature 이름들; 무엇을 갖고 비교했는지 이름을 가지고 알려준다; 안 하면 index가지고 하기 때문에 일일이 비교해야 할 수도 있다
, class_names = cancer.target_names #class 이름들
, rounded = True
, filled = True)) #filled : 색을 채워줘서 이해하기 더 편하다
display(SVG(graph.pipe(format='svg')))
# 가장 위에 있는 박스가 가장 중요한, 가장 많이 분류할 수 있는 조건/기준이다
# gini : 순도; 0,1의 비율; 섞여있는 정도; 낮을 수록 어느거 하나로 많이 차있다는 뜻이고, 클수록(0.5에 가까울 수록) 많이 섞여있다는 뜻; 그래서 순도가 0이 될 때까지 갈라진다
# sample : 데이터 양
# value = [a, b] -- 0인애가 a개, 1인애가 b개
# class : 개수가 더 많은 쪽의 클래스- DecisionTree model은 같은 클래스인 애들만 혹은 혹은 클래스가 완전히 분리되도록 다 쪼개기 때문에 과적합이 잘 일어나는 모델이다.
Decision Tree 복잡도 제어
- Decision Tree 모델을 복잡하게 하는 것은 노드가 너무 많이 만들어 지는 것이다 --> 다 분리를 해내기 때문이다.
- 노드가 많이 만들어 질수록 훈련 데이터셋에 과대적합 된다. 따라서 적절한 시점에 트리 생성을 중단해야 한다. 예를 드렁, 어디 까지만, 어느 단계까지만 쪼개지게(분리되게) 만들거나, 또는 어느 노드에서 x, y의 합이 5 미만이면 그 노드에선 더 이상 트리 생성을 중단하게 만들거나 해야 할 것이다.
tree2 = DecisionTreeClassifier(max_depth = 3) #최대 3단계 까지만 가지치기를 하라 라는 것
tree2.fit(X_train, y_train)
pred_train = tree2.predict(X_train)
pred_test = tree2.predict(X_test)
accuracy_score(y_train, pred_train), accuracy_score(y_test, pred_test)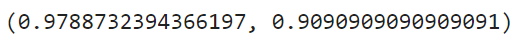
- 하지만 max_depth를 너무 적게 잡으면 과소적합이 일어날 수도 있는 것이다.
- 그렇다면 어떻게 가장 적합한/적당한 지점을 찾아낼까? 계속 돌려보는 수밖에 없다.
- max_depth (하이퍼파라미터)를 계속 바꿔주면서 가장 적당한 것을 찾아야 한다.
적당한 max_depth 찾기
- 학습데이터는 모델복잡도가 커질수록 성능이 좋아진다. 정확도가 계속 상승한다(그래프상으로 보면 올라간다).
- 테스트데이터는 모델이 복잡해지면은 복잡도가 커질수록 어느 정도까지는 성능이 올라가다, 데이터가 너무 학습데이터에 최적화되어 어느 순간부터 테스트데이터의 정확도는 떨어지게 된다.
- 가장 적합한/적당한 곳은 테스트데이터의 정확도가 max이면서 동시에 학습데이터의 정확도와의 차이가 크지 않은 곳을 찾아야 한다.
depth_list = range(1, 11)
train_acc_list = [] #한번 반복할 때마다 예측 정확도가 나오면 여기에다 저장할 것이다
test_acc_list = [] #여기도
for depth in depth_list:
tree = DecisionTreeClassifier(max_depth = depth)
tree.fit(X_train, y_train) #학습을 시키고
pred_train = tree.predict(X_train) #예측을 해보고
pred_test = tree.predict(X_test) #예측을 해보고
acc_train = accuracy_score(y_train, pred_train) #정확도; 평가지표를 만들어내고
acc_test = accuracy_score(y_test, pred_test) #여기도
train_acc_list.append(acc_train) #그것을 리스트에 담고
test_acc_list.append(acc_test)import pandas as pd
df = pd.DataFrame({'Train':train_acc_list, 'Test':test_acc_list}, index=depth_list)
df
# max_depth가 1~10 까지의 경우 정확도들 결과가 나왔다.
# train 데이터의 정확도는 계속 상승하지만, test 데이터의 정확도는 어느 시점부터 상승하지 않고 하락한다.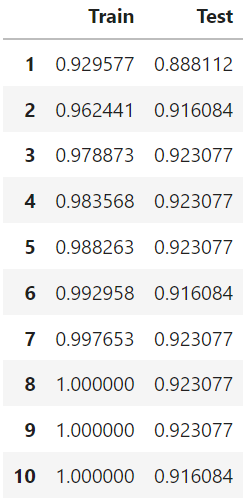
df.plot(figsize=(10,10));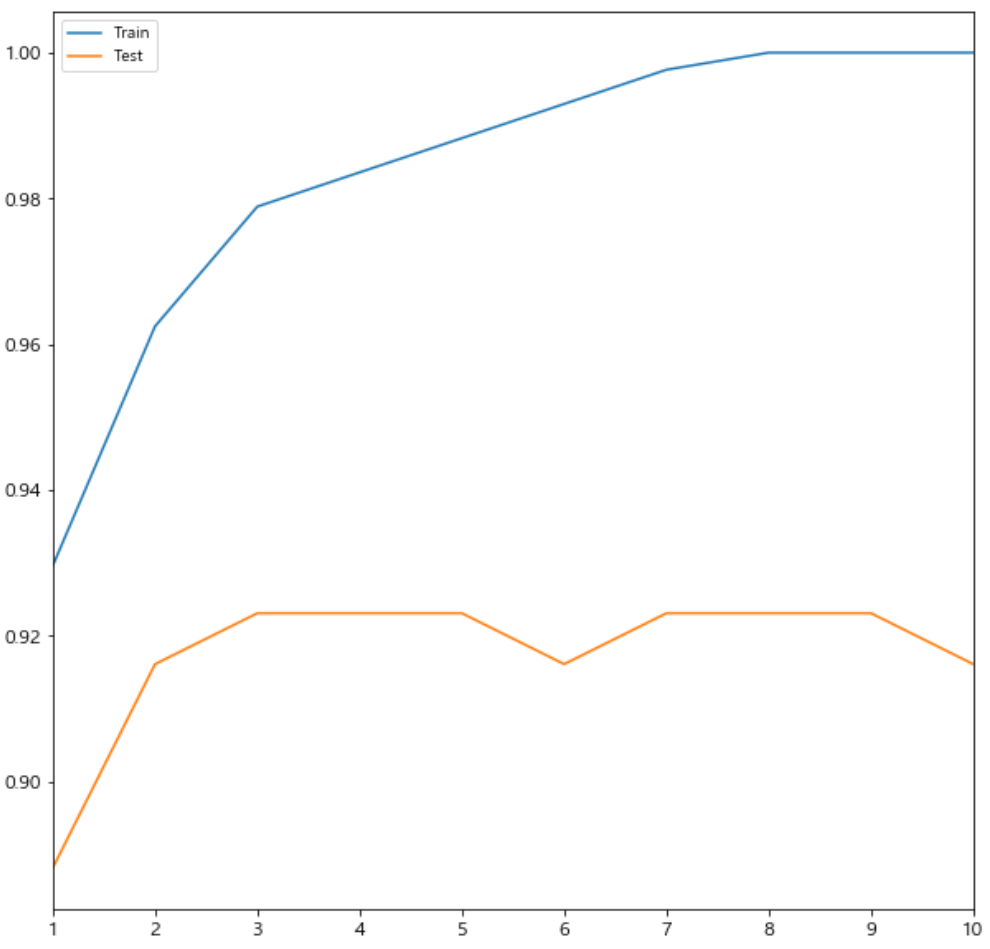
데이터 모델링을 하면서 모델 성능을 높일 수 있는 방법은 크게 (1) 데이터 전처리, (2) 하이퍼파라미터 튜닝이 있을 것이다.
- data 전처리 --> 성능을 가장 크게 높일 수 있는 곳(가장 먼저 해야 할 것)
- 모델 --> 하이퍼파라미터 튜징 (더 이상 전처리 할 수 있는것이 없을 때에, 하이퍼파라미터를 바꿈으로써 성능을 높일 수 있다; "튜닝한다"라고 함)
- 학습
- 검증
Grid Search 를 이용한 하이퍼파라미터 튜닝
하이퍼 파라미터 (Hyper Parameter)
- 머신러닝 모델을 생성할 때 사용자가 직접 설정하는 값
- 머신러닝 모델에 따라 다르기는 하지만 많은 하이퍼파라미터들을 변경할 수 있다.
하이퍼 파라미터 튜닝
- 하이퍼 파라미터의 설정에 따라 모델의 성능이 달라진다.
- 최적의 하이퍼파라미터를 찾는 것이 중요하다.
최적의 하이퍼파라미터 찾기
1. 만족할 만한 하이퍼파라미터들의 값의 조합을 찾을 때 까지 일일이 수동으로 조정
2. GridSearch 사용
- GridSearchCV()
- 시도해볼 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 하이퍼파라미터 조합을 찾아준다.
- 적은 수의 조합의 경우는 괜찮지만 시도할 하이퍼파라미터와 값들이 많아지면 너무 많은 시간이 걸린다.
- 모든 경우의 수를 다 조합을 해보고 모델을 만들어 예측을 해보고 검증을 하고 검증결과도 보여준다
GridSearchCV 매개변수 및 결과조회
- 주요 매개변수
-estimator: 모델객체 지정
-params: 하이퍼파라미터 목록을 dictionary로 전달('파라미터명':[파라미터값 list] 형식)
-scoring: 평가 지표
-cv: 교차검증시 fold 개수.
-n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용) - 메소드
-fit(X, y): 학습
-predict(X, y): 제일 좋은 성능을 낸 모델로 predict() - 결과 조회 변수
-cv_result_: 파라미터 조합별 결과 조회
-best_params_: 가장 좋은 성능을 낸 parameter 조합 조회
-best_estimator_: 가장 좋은 성능을 낸 모델 반환
from sklearn.model_selection import GridSearchCV
tree = DecisionTreeClassifier()
# 딕셔너리로 전달
# key: 하이퍼파라미터 명; value: [후보값들] 을 리스트로 전달
param_grid = {
'max_depth':[2,3,4,5,6,7,8], #7개
'min_samples_leaf':[5,10,15,20] #4개 --> 7x4 = 총 28개의 조합
}
grid_search = GridSearchCV(tree
, param_grid = param_grid
, cv = 5 #교차검증시 fold 개수; n번의 교차검증; 데이터들이 돌아가면서 하나씩 검증(validation)에 사용되어 일반화하는 것; 데이터가 많지 않을 때 보통 쓰인다고 함
, n_jobs = -1) #-1: 모든 코어 사용
grid_search.fit(X_train, y_train)
pred_train = grid_search.predict(X_train)
pred_test = grid_search.predict(X_test)
accuracy_score(y_train, pred_train), accuracy_score(y_test, pred_test)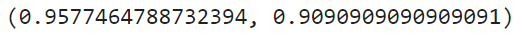
# 찾은 최적의 하이퍼파라미터 조회
grid_search.best_params_ # 준 후보들 중에서 최적을 반환(준 후보들 중이기에 이것보다 더 좋은/적합한 것은 존재할 수 있다.)
# 가장 성능 좋은 estimator(모델)
m = grid_search.best_estimator_ #가장 최적의 하이퍼파라미터 설정을 보여준다
m
accuracy_score(y_train, m.predict(X_train)) # 위에 grid_search한 것이랑 결과가 똑같이 나온느 것을 볼 수 있다; 그게 best를 쓴 것이기에 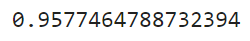
# 전체 결과 조회
grid_search.cv_results_
# 하지만 보기가 좀 힘들다
# 이렇게 dataframe으로 만들어 보면 좀 더 보기 편하다
import pandas as pd
df = pd.DataFrame(grid_search.cv_results_)
df
# 0~27 -- 총 28개 (다 검증된 것을 볼 수 있다)
# fit_time : 걸린 시간들
# param max, min 부분을 보면 모든 조합을 다 해본 것을 볼 수 있다
# split test score : 각각의 교차검증에 대한 점수; 그리고 평균 점수 (mean), 표준 점수(std), 그리고 순위(rank)
# 이것들 중에 '최적'이 나온 것이다
하지만 그리드 탐색은 조합이 비교적 적어서 보유한 컴퓨팅 자원으로 충분히 실행가능한 경우에만 현실적으로 사용 가능하다. 그렇다면, 만약 후보값이 너무 많을 때/조합이 너무 클 때, 그리드 탐색을 사용하기 어려울 경우엔 어떻게 해야 할까?
이 때엔, RandomizedSearchCV를 이용한 랜덤 탐색을 하는 것이 용이하다.
Random Search 사용
- RandomizedSearchCV()
- 랜덤 탐색은 모든 조합을 다 시도하지 않고 각 반복마다 임의의 값만 대입해 지정한 횟수만큼만 평가한다.
- 모든 경우를 다 조합해서 하는게 아니라 랜덤하게 일부만 조합을 해서 그 중에 최적의 조합을 정하겠다 라는 것
- 후보값이 많을 때 사용하기 좋음 (수가 많지 않다면 그냥 Grid Search 사용)
- GridSeach와 동일한 방식으로 사용한다.
- 랜덤 탐색의 장점은 크게 두 가지이다:
(1) 랜덤 탐색은 1000회를 입력할 경우 각 하이퍼파라미터에 1000개의 서로 다른 값을 입력한다. 그리드 탐색으로 1000개의 조합을 탐색하려면 임의로 1000개의 값을 설정해야 하지만 랜덤탐색은 자동으로 진행한다.
(2) 반복 횟수를 조절하는 것만으로 컴퓨팅 자원의 소비를 제어할 수 있다.
RandomizedSearchCV
- 개수를 어느 정도 정해주고, 그 중에서 제일 좋은 것을 찾아라 라는 것
- 주요 매개변수
-estimator: 모델객체 지정
-param_distributions: 하이퍼파라미터 목록을 dictionary로 전달 '파라미터명':[파라미터값 list] 형식
-n_iter: 파라미터 검색 횟수
-scoring: 평가 지표
-cv: 교차검증시 fold 개수.
-n_jobs: 사용할 CPU 코어 개수 (None:1(기본값), -1: 모든 코어 다 사용) - 메소드
-fit(X, y): 학습
-predict(X, y): 제일 좋은 성능을 낸 모델로 predict() - 결과 조회 변수
-cv_result_: 파라미터 조합별 결과 조회
-best_params_: 가장 좋은 성능을 낸 parameter 조합 조회
-best_estimator_: 가장 좋은 성능을 낸 모델 반환
from sklearn.model_selection import RandomizedSearchCV
tree = DecisionTreeClassifier() #여기 괄호 안에 하이퍼파라미터들이 들어가는 곳인데, 여기선 할 필요 없다
param_grid = {
'max_depth':[2,3,4,5,6,7,8], #7개
'min_samples_leaf':[5,10,15,20] #4개 --> 7x4 = 총 28개의 조합
}
n_iter = 5 #파라미터 검색 횟수; 여기선 5번
random_search = RandomizedSearchCV(tree
, param_distributions = param_grid
, n_iter = n_iter
, cv = 5)
random_search.fit(X_train, y_train)
pred_train = random_search.predict(X_train)
pred_test = random_search.predict(X_test)
accuracy_score(y_train, pred_train), accuracy_score(y_test, pred_test)
random_search.best_params_ #최적의 파라미터 조회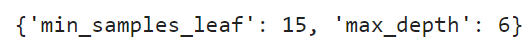
random_search.best_estimator_ # 최적의 설정
pd.DataFrame(random_search.cv_results_)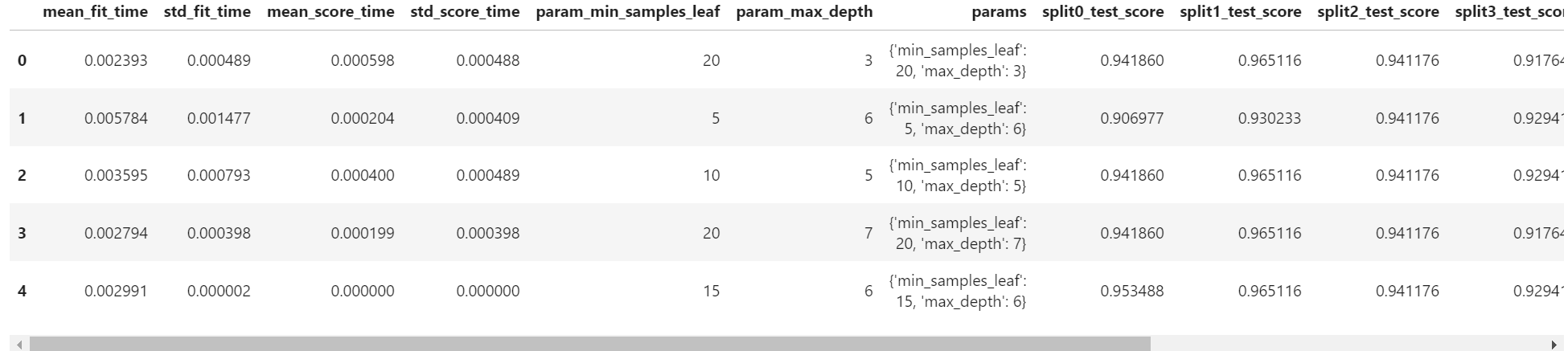
GridSearchCV와 RandomizedSearchCV는 정말이지 편리한 기능이 아닐 수 없다. 최적의 파라미터 값을 알아서 찾아주는 방법, 잘 활용한다면 분명 좋은 성능의 모델을 만드는데 매우 유용할 것이다.
