서론
이전 글에서는 도커로 Opensearch를 띄워봤습니다. 그럼 기존 DB에 존재하던 데이터는 어떻게 옮기면 될까요?
ELK Stack에는 Logstash라는 데이터 처리 파이프라인이 있는데요, Opensearch에서도 동일하게 Logstash를 사용하면 됩니다!
Logstash는 단순히 RDBMS -> Elastic(Open)Search로의 데이터 전송만을 담당하지 않습니다!
대부분의 입력 소스에 대하여 데이터를 가공하고 처리하여 대부분의 출력으로 보내는 역할을 할 수 있습니다.
예를 들어 웹 서버의 로그 파일을 주시하며 데이터를 처리한 후 AWS의 S3로 옮기게 할 수도 있죠 :)
이번 시간에는 MySQL의 데이터를 Logstash로 처리하여 Opensearch로 옮기는 과정을 설명해보겠습니다.
logstash-output-opensearch
아쉽게도 순수 Logstash만으로는 Opensearch로 데이터를 전송할 수 없습니다... 추가적인 플러그인을 설치해야하는데요
바로 logstash-output-opensearch 라는 플러그인입니다.
Opensearch에 대해 알아보기 위해서 여러 블로그 글을 검색해봤을 때, 대부분의 글에서는 해당 플러그인이 포함된 이미지인 logstash-oss-with-opensearch-plugin을 소개해주고 있었습니다. (심지어 공식 문서에서까지도...)
해당 이미지는 현재 지원이 중단된 상태인데요, 관련 블로그 게시물에서는 플러그인이 업데이트 될 때마다, Opensearch팀에서 해당 플러그인이 포함된 이미지를 다시 제공해야 하는데, 그 기간 동안 사용자들이 빠르게 업데이트를 받지 못하기 때문에 지원을 중단했다고 합니다.
그렇기에! 우리는 해당 플러그인이 포함된 이미지를 직접 생성해야 합니다.
Logstash 도커 이미지 생성하기
해당 이미지를 만들기위한 Dockerfile은 쉽게 작성할 수 있습니다. 기존 이미지를 설치하고 컨테이너 내부에서 해당 플러그인을 설치하게 하면 되거든요.
FROM docker.elastic.co/logstash/logstash:8.17.3
RUN bin/logstash-plugin install logstash-output-opensearch버전(8.17.3)은 최신 버전을 확인하여 교체해주세요!
필요한 파일 준비하기
Logstash로 RDBMS에서 Opensearch로 데이터를 옮기기 위해서는 아래의 세 가지 파일이 필요합니다.
pipelines.yml: 여러 파이프라인 구성 설정 파일- 파이프라인 정의 파일: 파이프라인 동작을 정의하는 파일
- JDBC 파일: DB에 연결하기 위한 JDBC 파일
저는 이 파일들을 아래와 같은 파일 구조로 관리하고 있습니다! 여러분들께 편리한 방식으로 구성하여 Logstash를 이용해보세요.
logstash
├── Dockerfile # 이전 단게에서 생성한 Dockerfile
├── config
│ └── pipelines.yml
├── pipeline
│ └── logstash-recreations.conf
└── resources
└── jdbc
└── mysql-connector-j-9.2.0.jarpipelines.yml
해당 파일은 여러 파이프라인을 구성하고 설정하기 위한 파일입니다.
저의 경우 MySQL -> Opensearch 하나의 파이프라인만 필요하기 때문에 하나의 구성만 작성하였습니다!
- pipeline.id: recreations
pipeline.workers: 1
path.config: "/usr/share/logstash/pipeline/logstash-recreations.conf" # 파이프라인 정의 파일파이프라인 정의 파일
이제 실제로 파이프라인이 어떻게 동작하는지 정의하는 파일을 만들어 보겠습니다.
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://host.docker.internal:3306/avab"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "root"
jdbc_driver_library => "/usr/share/logstash/resources/jdbc/mysql-connector-j-9.2.0.jar"
statement => "SELECT
r.id,
r.title,
r.summary,
GROUP_CONCAT(DISTINCT rk.keyword) AS keywords,
r.min_participants,
r.max_participants,
r.play_time,
GROUP_CONCAT(DISTINCT rp.purpose) AS purposes,
GROUP_CONCAT(DISTINCT rg.gender) AS genders,
GROUP_CONCAT(DISTINCT ra.age) AS ages
FROM recreation r
LEFT JOIN recreation_recreation_keyword rrk ON r.id = rrk.recreation_id
LEFT JOIN recreation_keyword rk ON rrk.keyword_id = rk.id
LEFT JOIN recreation_purpose rp ON r.id = rp.id
LEFT JOIN recreation_gender rg ON r.id = rg.recreation_id
LEFT JOIN recreation_age ra ON r.id = ra.recreation_id
GROUP BY r.id"
}
}
filter {
mutate {
split => {
"keywords" => ","
}
split => {
"purposes" => ","
}
split => {
"genders" => ","
}
split => {
"ages" => ","
}
}
ruby {
code => "
['keywords', 'purposes', 'genders', 'ages'].each do |field|
event.set(field, []) if event.get(field).nil? || event.get(field).empty?
end
"
}
}
output {
opensearch {
hosts => ["http://opensearch-node1:9200"]
index => "recreations"
ssl => false
ssl_certificate_verification => false
}
}filter.mutate에 있는 내용은 배열 값이 null일 때 빈 배열로 치환하는 구문입니다.
Opensearch의 보안 설정을 꺼두었다면 output.opensearch에서 ssl과 ssl_certifacate_verfication은 false로 해주세요.
JDBC 파일
MySQL 공식 사이트에서 JDBC JAR 파일을 받아주면 됩니다!
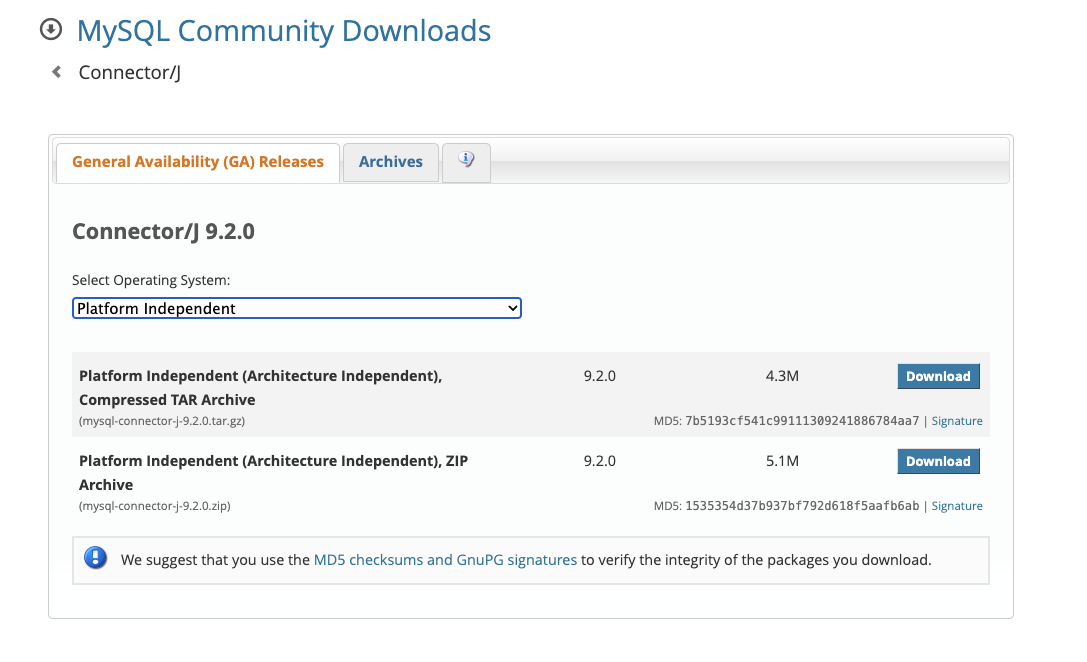
Platform Independent로 하여 다운 받은 후 내부에 있는 JAR 파일을 이용하면 됩니다!
docker-compose.yml 작성하기
이제 파일들을 적당히 구성했다면 실제로 Docker에 올려볼 차례입니다.
이전 글과 중복되는 내용은 생략하였으니 궁금하신 분은 이전 글을 참고해주세요!
logstash:
build: ./logstash # Dockerfile이 있는 디렉토리
container_name: logstash
volumes: # 볼륨 설정 확인!
- ./logstash/config/pipelines.yml:/usr/share/logstash/config/pipelines.yml
- ./logstash/pipeline:/usr/share/logstash/pipeline
- ./logstash/resources:/usr/share/logstash/resources
ports:
- 5044:5044
networks:
- opensearch-net이전에 만든 파일을 볼륨에 적절히 매핑만 해주면 됩니다.
실행해보기
이제 docker-compose.yml로 컨테이너를 띄워볼까요?
이전에 정의한 Opensearch와 Dashboards도 동일하게 다시 띄워지게 됩니다!
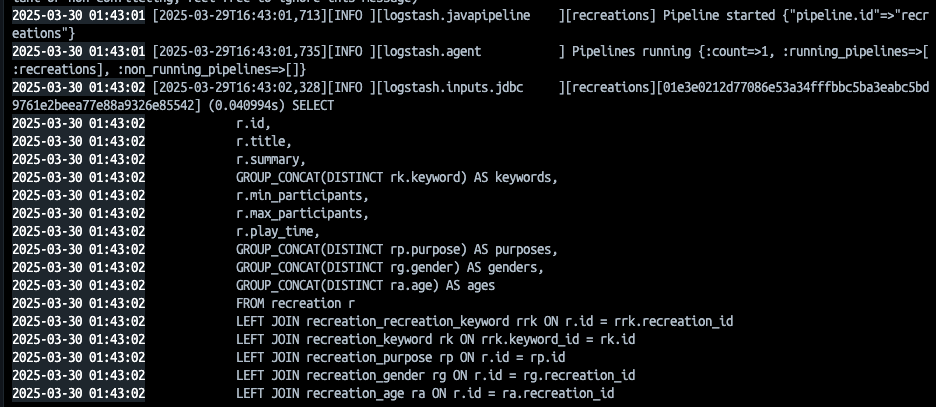
컨테이너에 찍힌 로그를 보면 정의한 SQL문대로 파이프라인이 정상적으로 돌아가고 있는 것을 확인할 수 있습니다!
결론
이번 글에서는 Logstash와 Opensearch를 연동하고, MySQL의 데이터를 Opensearch로 옮기는 작업을 소개해 드렸습니다.
다음 글에서는 옮겨진 데이터를 Opensearch를 이용하여 검색 자동완성을 만드는 기능을 소개해드리겠습니다!
