[논문] Effective Whole-body Pose Estimation with Two-stages Distillation, DWPose
Pose Estimation 논문 리뷰
오늘 리뷰할 논문은 ICCV 2023에 제출된 논문 Effective Whole-body Pose Estimation with Two-stages Distillation입니다. 얼마 전에 RTMPose를 보고 놀랐는데, 이 논문은 그런 RTMPose를 기반으로 두가지 Knowledge Distillation을 통해서 성능을 극대화한 연구입니다.
개인적으로 저자가 중국인이면, 더 궁금해지는데요! 우선 양쩐똥(Zhendong Yang)님 이십니다. 찾아보면 pose estimation뿐만아니라, knowledge distillation에 큰 관심을 가지고 계심을 알 수 있습니다. 양쩐똥님은 IDEA(International Digital Economy Academy)에서 인턴 하실때, 이 연구를 하셨다고 합니다. 논문 저자의 다른 분들은 교수님(Chun Yuan)과 IDEA에서 지도해주시는 연구원분들(Ailing Aeng, Yu Li)입니다.
그리고, DWPose는 RTM Pose 처럼 MMPose에 속해져있습니다. 교수님이 칭화대(정확히는 칭화대 부속 대학)이시고, 현재 양쩐똥님이 칭화대 부속 대학교에서 석사를 하고 계시니, 자연스럽게 MMPose에 들어간 것 같네요. 아! 물론 성능인적인면에서 MMPose에 들어가게 된 게 제일 크겠죠!!!
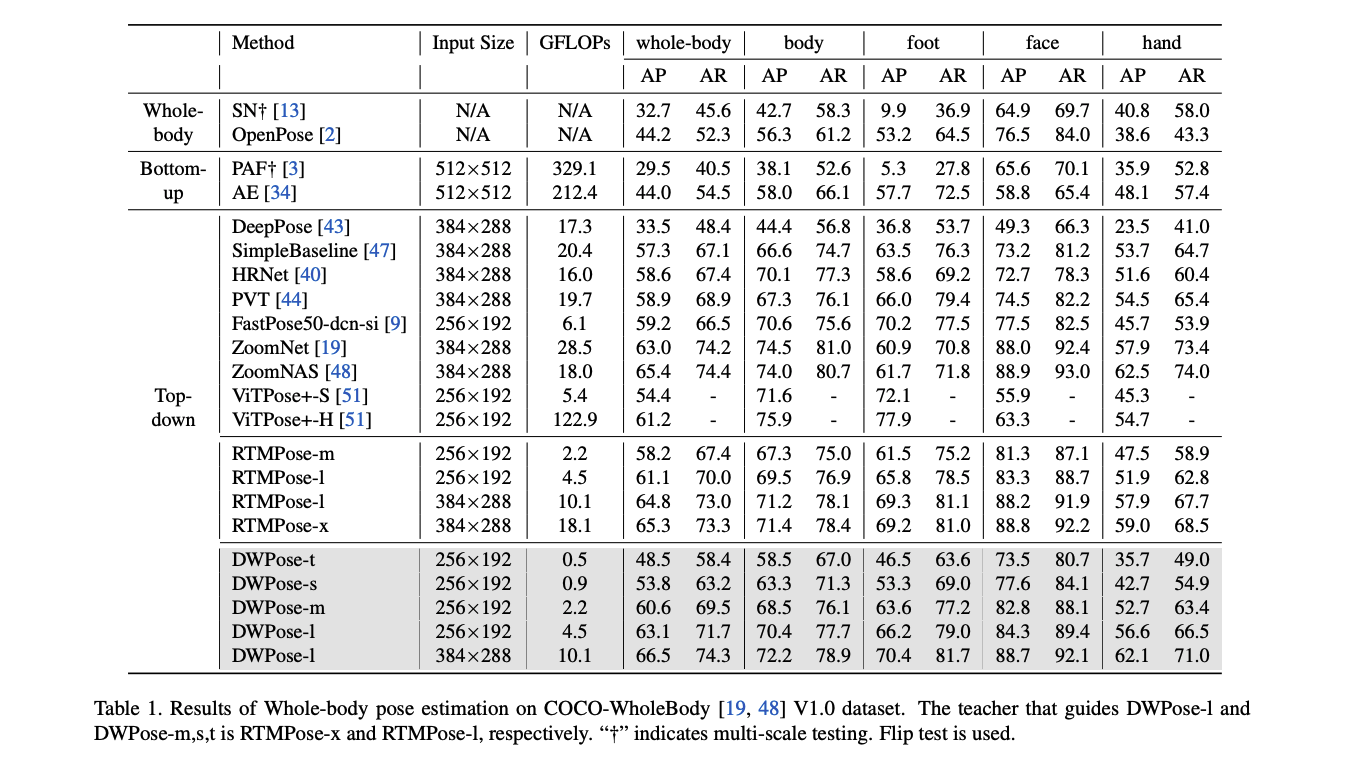
다음은 다시 모델 자체로 돌아와서! DWPose... 성능이 엄청납니다. COCO-Wholebody에서 지원하는 것처럼 무려 133개의 조인트를 지원하고, Whole AP가 0.665이고, 각각의 부분(Body, Foot, Face, Hand)에서 좋은 성능을 보입니다. RTM Pose를 뛰어넘었습니다..🤩
https://github.com/IDEA-Research/DWPose
https://arxiv.org/pdf/2307.15880.pdf
Introduction
- 두 단계의 knowledge distillation(KD)를 통한 효율적이고 정확한 pose estimation
- 데이터 한계를 극복하여, hand gesture와 facial expression과 다양성 있는 데이터 사용을 통한 실생황을 타겟팅
- RTM Pose를 기반에 KD 방법과 데이터활용을 통한 성능 향상(RTMPose-1: 64.8% -> 66.5%)
Method
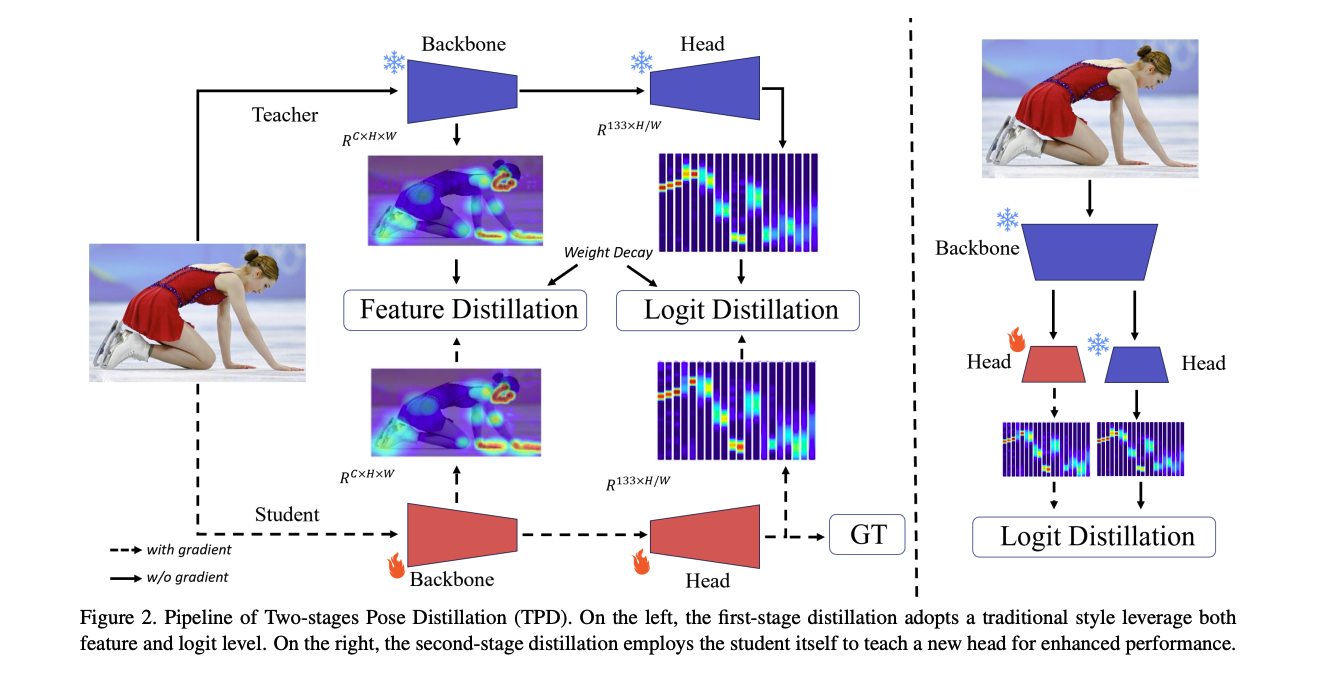
저자는 two-stage pose distillation(TPD)를 제안합니다. 첫번째 stage의 distillation은 pretrained Teacher가 scratch로 student를 feature와 logits를 가이딩합니다. 그리고, 두번째 단계에선 self-KD 방법으로, 모델이 라벨링된 데이터없이 스스로 만들어낸 logits를 이용하여 짧은 시간동안 더 큰 성능 강화를 합니다.
The First-stage distillation
- : teacher와 student의 backbone에서 나온 feature
- : teacher와 student의 output logits
첫번재 KD에서는 student가 teacher의 와 를 학습하도록 합니다.
Feature-based distillation
Feature-based distillation는 student가 teacher의 backbone Layer를 따라할 수 있도록 하는 방법입니다. 저자는 student의 feature 와 teacher의 feature의 차이를 계산하기 위해 MSELoss를 사용했습니다. 그 과정을 식으로 표현하면 아래와 같습니다.
여기서, 를 의 diemsion과 맞추기 위한, f는 conv 입니다.
Logit-based distillation
RTMPose는 수직수평의 좌표를 classification으로 다루는 SimCC 알고리즘을 통해서 pose keypoints를 추론합니다.
그 형태에 맞춰서 logit-based KD를 수행합니다.
그전에 RTMPose의 classfication loss를 보자면,
- : batch, : keypoint 수, : x,y의 localization bin 수, : 보이지 않는 keypoints를 구별하기 위한 target weight mask, : label value
그러나, label value와 다르게 invisible 키포인트는 teacher에 의한 합당한 값이 될 수 있기 때문에, 아래와 같은 수식으로 만들었다고 합니다.
Weight-decay strategy for distillation
student의 loss는 다음과 같은 total loss로 정리할 수 있습니다.
여기서, 는 loss의 균형을 맞추기 위한 하이퍼파라미터 입니다.
저자들은 detection distillation 방법인 TADF를 따라서, 점차 생기는 distillation의 패널티를 줄이기 위해서, weight decay 전략을 사용합니다. 이런 방법은 student가 라벨에 집중하고, 더 좋은 성능을 보일 수 있도록 하는데요. 아래와 같은 time function을 사용하는 것입니다. 아래의 t는 현재 epoch입니다.
이를 Loss에 적용하여 완성된 첫번째 KD의 loss는 아래와 같게 됩니다.
The Second-stage distillation
두번째 단계에서는 student model이 더 좋은 성능을 갖게하는 방법입니다.
아시다시피, pose estimator는 encoder역할을 하는 backbone과 decoder인 head로 구성되어 있습니다. 우선, train된 backbone과 그렇지 않은 head로 student를 만들고, 같은 학습된 backbone과 head로 teacher를 준비
합니다. 그리고, student의 backbone은 freeze하고 head만 학습시에 사용합니다. teacher와 student는 같은 구조리기 때문에 backbone에서 한번만 feature를 뽑으면 되고, 그 feature를 stuedent와 teacher의 head에 입력하여 와 를 얻어 냅니다. 그리고 logit-distillation에서 사용했던 같은 방식의 loss를 적용하는 것이죠. 이렇게 되면 label로 계산된 값을 를 떨어뜨릴 수 있습니다. 를 통해 scale조정된 두번째 단계 distillation의 loss는 아래와 같습니다.
저자들의 이러한 방법은 training 시간을 20%로 줄였고, localization 능력도 향상시켰다고 합니다.
Experiments
Datasets and Details
- Datasets: COCO + UBody
- Implementaition detail
- loss hyper-parameter:
Main Result



Anlaysis
Effects of TPD method and UBody Data

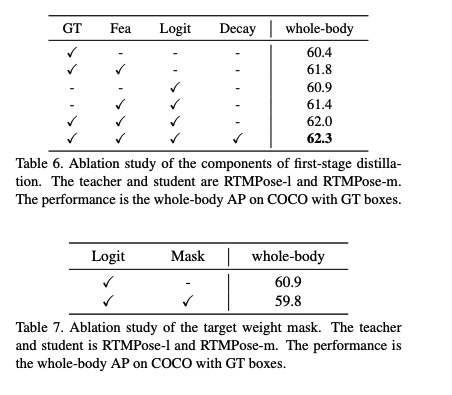
Effects of First and Second Stage Distillation

DWPose for ControlNet


안녕하세요. 블로그 주인장님. 잘보고있습니다. hpe분야 연구를 해보고 싶은데, 도움이 되고 있습니다.
혹시 주인장님도 hpe 분야를 별도로 연구하시는건가요?