[논문] Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
오늘 논문은 지난번 리뷰한 Metrabs의 저자 István Sárándi님의 또 다른 논문입니다. 간단히 조사해 본 바에 의하면 3D human undertanding분야에서 pose estimation을 연구하시는 분인데요. 지금은 Real Vitual Humans에서 researcher로 계십니다. MeTRABs 이후에 Demo라는 real-time 3D human Estimation이 가능한 모델을 발표하셨는데, 다음번에 리뷰하도록 하겠습니다.
본 논문은 제목에서도 어느정도 유추가 가능한 것처럼, 많은 데이터셋을 어떻게하면 한번에 잘 학습하는지에 대한 연구를 주제로 합니다. 아시다시피, ML에서 데이터 양과 질은 모델의 성능에 큰 영향을 줍니다. 최~대한 다양한 데이터셋을 학습시킴으로써, 모델이 어떤 input이 들어와도 잘될 수 있도록 하는것이 우리의 소망이죠. 다행히, 최근에 많은 데이터셋의 출현해서 양적인 면에서 부족하다고 하기에는 변명밖에 안되죠.😓(근데, 그래도 부족하긴 합니다!!) 여튼, 양은 많아져서 이제 ML을 통한 pose estimation은 성능면에서 많은 발전을 이뤘는데, 여전히 문제는 있죠. 정말 디테일이 필요한 춤이나, 영화 산업에 과연 신뢰를 줘서 기술을 사용할 수 있게끔 할 수 있나?라는 생각이 들어요. 춤같은 경우의 그루브가 굉장히 중요하자나요. 그리고 최근 유행한 슬릭백이나 트월킹의 작은 디테일이 잘 표현되어야 그 의미가 있죠. 근데, pose estimation에서 데이터셋은 정해진 annotation rule이 없고, 표현된 joint개수도 다 다르고, 심지어 위치도 다 다른데, 모든 데이터셋을 다 갖다 쓰다보니, 그런 데이터로 학습된 모델이, 과연, 그 그루브와 디테일을 표현할 수 있을까는 의문이죠. 그런 의미에서, 이제는, Pose분야도 양보다 질로 승부해야할 때가 된 겁니다! 아마 István Sárándi님도 그런 생각이 들지 않으셨을까요? 그럼 어떻게 솔루션을 제시하는지 보겠습니다!
https://istvansarandi.com/dozens/
https://arxiv.org/pdf/2212.14474.pdf
Introduction
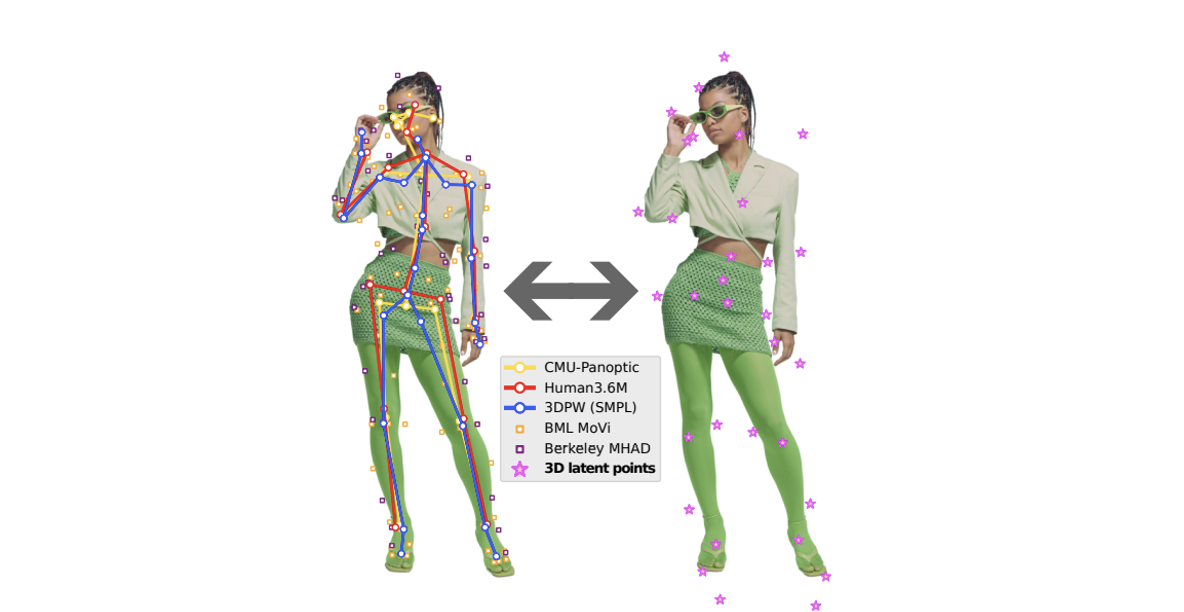
저자는 많은 연구자들이 제공하는 데이터셋들에 감사함을 표현하면서, 동시에, 그 데이터셋들이 서로 다른 위치에 같은 label로 annotation되어 있음에 아쉬움을 표합니다. 예를 들면, 데이터셋마다 힙의 높이나 위치가 조금씩 다르죠. 그래서 많은 모델들이 그 많은 데이터셋을 같은 데이터 포멧으로 학습한 후 test해보면 hip(또는 다른 조인트들)이 미세하게 또는 많이 씰룩씰룩합니다.(제 표현이 적절...한가요?) 그래서 저자는 고민합니다. 어떻게 하면 자동으로 서로 labeling이 다르게 된 많은 3D pose 데이터셋을 하나의 trainig process에 합쳐서 넣을 수 있을까?
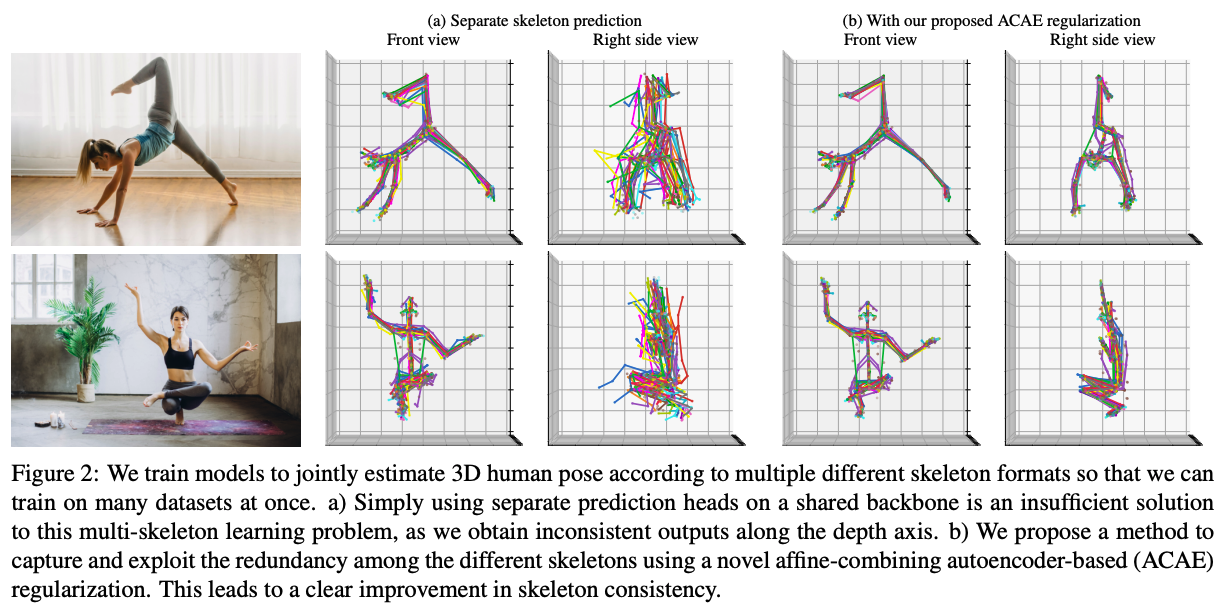
아마 이런 문제를 multi-task learing problem으로 생각하고, 하나의 backbone에 따로따로 output head를 줄 수 있을 겁니다. 하지만, 위의 Fig. 2a에서 볼 수 있듯이, 그 방법은 모델의 depth 추정에 있어 일관되지 않은 점이 눈에 확 띄고, skeleton들 사이에 불충분한 정보 공유로 인해, 이상적이지 않습니다.
저자는 이러한 두 개의 밸런스(front와 right side view의 각각 결과)를 잘 균형잡기 위해서, 같은 label의 서로 다른 포맷들을 가진 skeleton 포멧들간의 약간의 connection을 만들어줍니다. skeleton들 간의 위치적인 관계를 학습하기 위해서, 저자는 autoencoder기반의 차원 축소 테크닉을 제안하여, 대량의 3D keypoint들을 더 작은 latent keypoint로 축소하여 더 낮은 cardinality representation을 수행하도록 합니다. 인코더와 디코더는 인풋 점들의 affine combination을 계산하여, 회전과 이동이 동일해질 수 있도록합니다. 더 나아가, weight sharing을 통하여, 왼쪽 / 오른쪽의 비대칭성을 줄입니다. 저자들은 논문에서 이러한 역할을 하는 autoencoder를 Affine Combining Autoencoder(ACAE)라고 부릅니다. 저자들은 이러한 ACAE를 output regularizer로 학습하고, 일관성있는 추정을 할 수 있도록 합니다. 이런 방법은 양적, 질적 개선을 이룰 수 있었습니다. 뿐만 아니라, regularization 방법 대신에, 3D pose estimator로 바로 ACAE의 latent keypoint를 추정할 수 도 있습니다. 후자의 경우는 많은 조인트를 추정해야하는 pose estimator가 필요없어, cost도 줄일 수 있습니다. 이 두가지 경우에서, 최종 추정결과는 일관성있게 되고, 다양한 데이터셋도 이용할 수 있게 해줍니다.
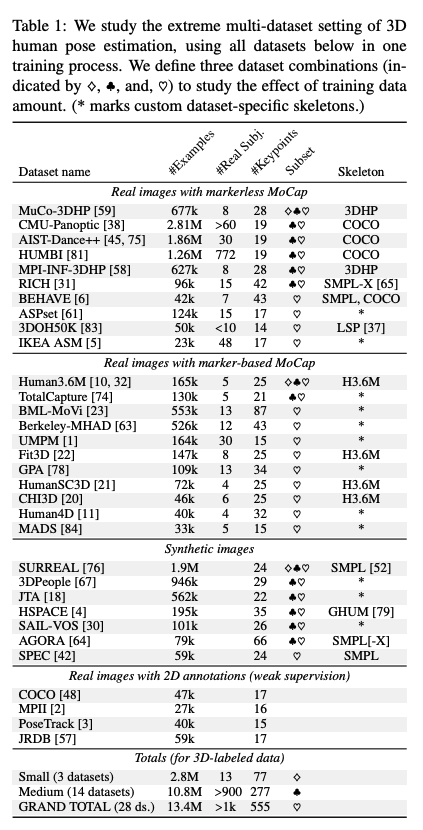
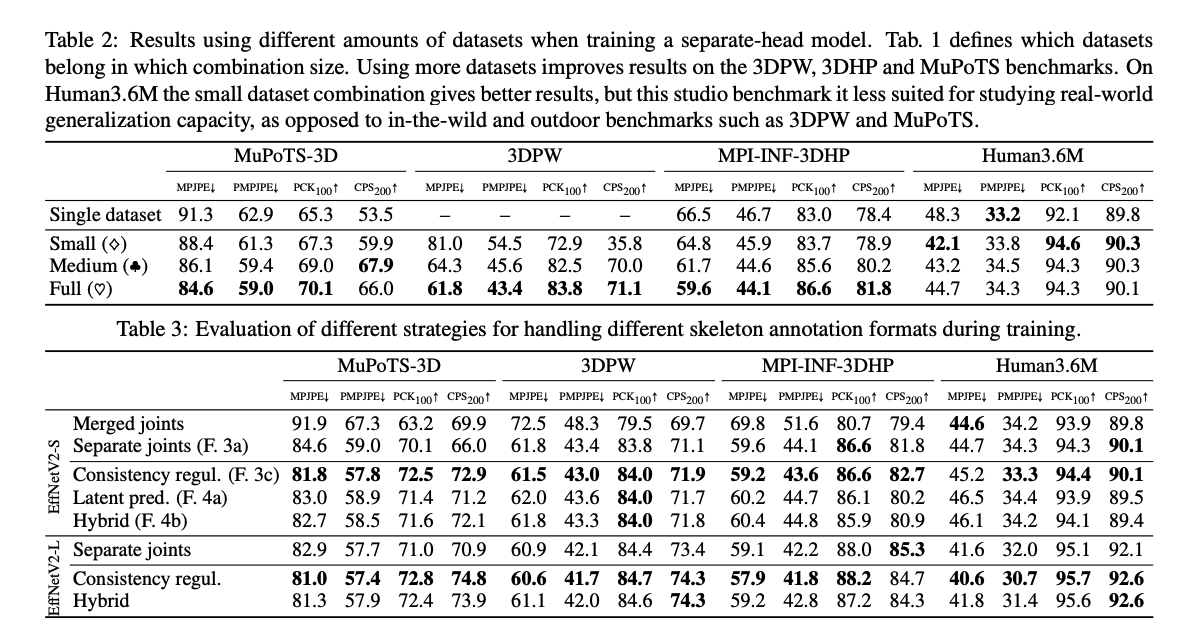
저자는 28개의 데이터셋을 모아, 불필요한 데이터셋을 걸러낸 뒤, 130만장의 데이터를 사용합니다. 이 데이터셋들의 개별 joint는 총 555로 Table 1에서 볼 수 있습니다.
main contribution:
- 28 개의 대량 3D pose 데이터셋을 모아, 재생산(불피요한 데이터 제거) 과정을 제작
- ACAE를 통한 pose의 keypoint에 최신 linear 차원 축소 기법 제안
- 일관성있는 추론을 통한 질적 양적 개선효과
- in-the-wild 환경에서의 훌륭하고 일관성있는 3D pose estimator 릴리즈
Method
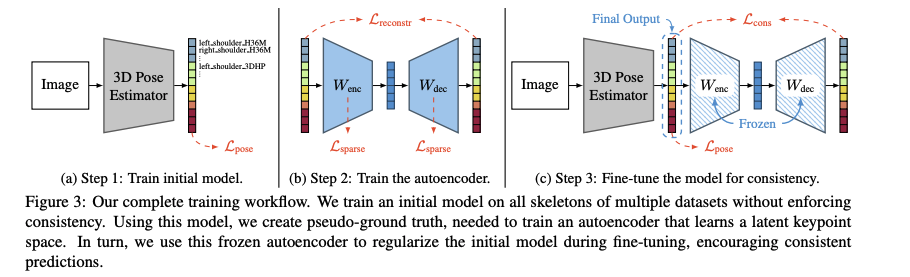
저자들의 목적은 비록 다른 데이터셋에서 다른 skeleton 포멧을 제공해도, 많은 데이터셋을 학습과정에 합쳐 넣어, 강력한 monocular RGB기반의 3D human pose estimation을 달성하는 것입니다. 논문에서 각각 joint를 가진 개의 skeleton 포멧을 가지고 있고 전체는 입니다. 추가로, 합친 데이터셋은 개의 training sample을 가지며, 각각 한명의 이미지와 3D의 joint 에 대한 annotation을 가집니다.
저자는 제안하는 방법을 다음 3단계를 구성합니다.
1. 공통의 백본을 가지고 각각의 포멧에 따른 헤드를 각각 가진 모델을 학습합니다. (Fig 3a. 참고)
2. 1에서 학습된 모델로 각각 다른 포멧의 모든 skeleton으로 주어진 많은 포즈를 pseudo-ground truth "parallel corpus"를 추론하고, 이것을 통합하여 undercomplete geometry-aware autoencoder를 학습시켜, pseudo-GT data에서 pose가 가장 잘표현된 latent 3D body landmark를 얻을 수 있도록 합니다. (Fig 3b. 참고)
3. 학습된 autoencoder를 붙여서, 모델 아웃풋이 일관성을 가질 수 있도록 합니다. 또한 다양한 latent point 추정과 hybrid variant를 마지막 부분에서 실험합니다.
Initial Model Training
저자는 서로 다른 skeleton들을 연관 짓거나 하지 않고 공통의 backbone에 각각의 head를 두어, 굳이 서로를 연관시키지 않습니다. 그리고, 다음의 pose loss를 최소화하는 방향으로 학습합니다. 또한, 해당 포멧에 없는 조인트에 대해서는 loss를 발생시키 않습니다.
- : prediction과 GT에 대한 loss의 평균
- : 이미지에 projection된 2d 좌표에 대한 loss
- : 카메라 좌표계상의 절대적 pose 대한 loss
학습 결과는 Fig 2a.에서 볼 수 있듯이, 2d 상에서는 잘 학습되었지만, depth(right side view)는 그렇지 않은 것을 볼 수 있습니다.
Pseudo–Ground Truth Generation
각각 다른 skeleton의 joint를 어떻게 서로 연관지을지에 대해서 정의하기 위해, 저자들은 같은 example에 대해 모든 skeleton format에 따른 pose label을 "Rosetta Stone"으로 만들었다. 하나의 데이터셋은 보통 하나의 포멧을 가져, 모든 경우에 GT를 사용하지 못하기 때문에, 저자는 다른 head 모델을 사용하여 pseudo-GT를 만들었다. 이 단계에서 모델이 잘 다룰 수 있는 이미지를 사용하는 것이 중요하기 때문에, 저자는 상대적으로 깨끗하고, 군더더기 없는 데이터셋(H36M과 MoVi)을 사용했다. 그 세트에 대해선 을 가진 pseudo-GT라고 한다.
Affine-Combining Autoencoder
모든 J 조인트 세트의 redundancy를 잡아내고 내어 일관성있는 추정을 하기 위해서, 저자는 간단하지만 효과적인 차원축소 기술을 사용했습니다. pseudo-GT가 2D에서는 믿을만하지만 depth 방면에서는 그렇지 못하기 때문에, latent representation view-point에 독립적이여하며, rotation과 translation에 대등해야합니다. 이러한 대등함은 latent representation이 기하학적이여야 한다는 것인데, 그 의미는 즉, latent 3D 점들로 구성되어야 한다는 것입니다. 직관적으로, 다른 skeleton들을 서로 연관 시키기위해서는 joint가 사람 몸에 어떻게 정의되어 있는것인지를 봐야지 카메라 앵글에서 보면 안됩니다. 또한, 그런 latent point들은 모든 포즈 구조를 다 포함할 수 있어야하고, 왼 무릎이면 왼 무릎만 책임지고 다른 조인트는 상관하지 않는 sparse함이 있어야합니다. 그래서, 저자들은 위와 같은 필요성을 고려하여 제한적인 undercomplete linear autoencoder인 affine-combing autoencoder(ACAE)를 사용합니다. 이 인코더가 J points 리스트를 input으로 받고, 아래와 같이 affine combination을 계산하여 L latent points 로 인코딩합니다.
인코더가 위와같다면, 디코더도 비슷하게 latent points에서 원래 포인트들을 되돌려놓는 것이니, 아래와 같아집니다.
affine combination은 어떤 affine transformation에도 동등하기 때문에, 저자들의 인토와 디코더는 rotation과 translation에 동등합니다.
ACAE의 학습되는 파라미터들은 affine combination weight 와 인데, 이 파라미터들은 latents의 (잠재적으로 음수인) 일반화된 barycentric 좌표이며, 반대로 조인트 전체 세트로 볼 수 있습니다. 여기서 음수라는 것은 human body에서 뻗어나갈 수 있도록 하기 위헤서 필수적이죠. 그리고, 이 weight들의 sparsity를 얻기위해서, 저자는 regularization을 사용하여 음수 가중치들을 줄이고, convex combination에 가깝게 해줍니다. 추가로, reconstruction loss를 사용하여 outlier들에도 robust하게 해줍니다.
Problem Statement
저자가 제안한 autoencoder를 좀더 형식화 해서 보면, joint를 가진 개의 학습 포즈 에서 다음 최소화합니다.
Reconstruction Loss on 2D Projection.
저자는 2D 이미지상에서 depth보다 2D projection한 것이 더 믿을 만하다는 것도 이용하여 다음 loss를 추가합니다.
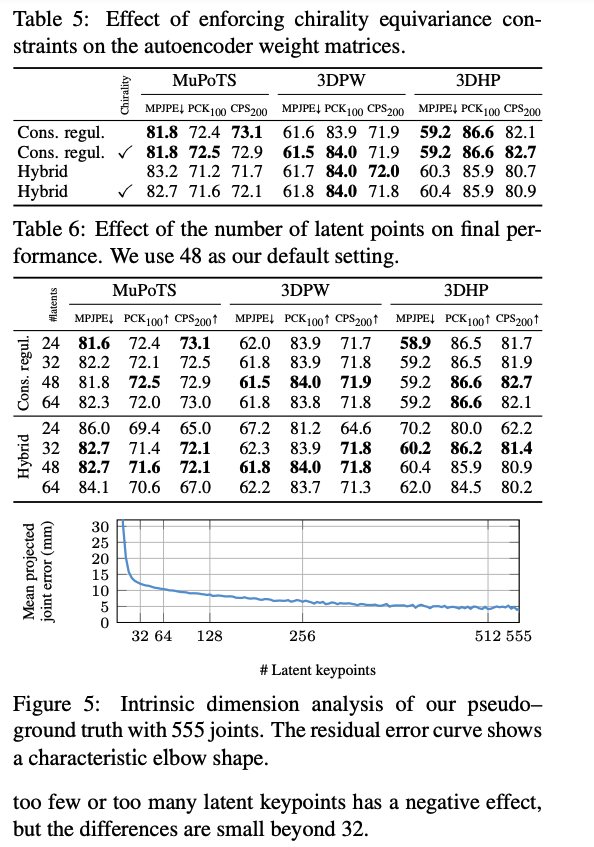
Chirality Equivariance.
사람 몸이 대칭적인 것처럼, 저자들의 auto encoder도 대칭성을 가져갑니다. 그래서 중앙, 왼쪽, 오른쪽, 이렇게 세 부분으로 균일하게 집합을 나눠줍니다. 그랬을때 가중치의 구조는 아래와 같게 됩니다.
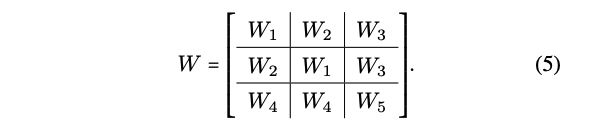
다시 돌아와서, 위와 같은 구조는 논문에서 말하는 대칭성 (chirality equivariance)를 보장할 수 있게 되죠.
Head Keypoint Weighting.
머리부분의 미포인트들은 서로 연관성이 많기 때문에, 좀 더 가중치를 줬다고 합니다.
Consistency Fine-Tuning
Output Regularization.
예측된 조인트들을 autoencoder에 넣을 때, latent space에서 일관적인 추정을 위해서, 다음 loss를 추가했다고 합니다.
Direct Latent Prediction.
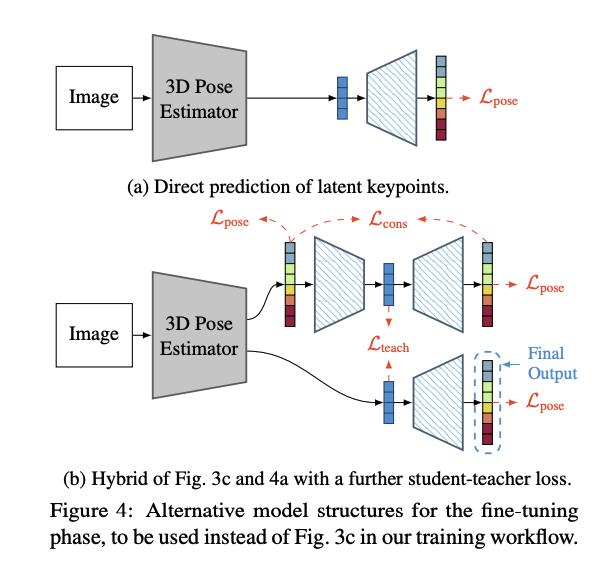
pose estimator에서 많은 skeletons를 추정하는 것을 피하기위해, 저자들은 latent 가 추론되고, 바로 frozen됭 decoder에 들어갑니다. Fig 4.a에서 보이는 것처럼요.
Hybrid Student–Teacher.
추가로, Fig 4.b 처럼 knowledge distillation을 사용하여 3D Pose Estimator가 바로 latents를 추정할 수 있도록 했습니다.
Experimental Setup
Base Model.
- MeTRAbs 사용
- backbone: EfficientNetV2-S
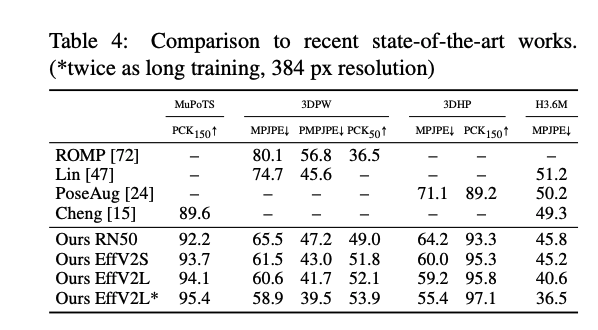
Results