[논문] One-for-All: Bridge the Gap Between Heterogeneous Architectures in Knowledge Distillation
프로젝트 하나만 딱 정해서 연구/개발을 하다보면, 내가 만드려는/사용하려는 모델이 많은 난관에 부딪히는 경우가 많아요. 그 중 하나가, 모델 정확도는 너무 괜찮은데, 서비스에 모델을 올리기에는 너무 무겁다는 것이죠 🥲 이제는 더이상 정확도만으로는 세상을 바꾸지 못합니다... 그래서 많은 방법으로 모델을 경량화하고자 하는 연구들이 많이 출현했습니다.
그 중 하나가 Knowledge Distillation(KD)을 통한 model compressing입니다. KD는 2014년에 처음 제안된 방법으로, 최근에 많은 분야에서 사용되었죠. 그리고, 많은 분야에서 KD가 그냥 학습시키는 것보다 훨씬 좋은 효과를 보인다는 성과가 쏟아져 나왔어요. 제가 관심있는 Real-time Pose Estimation 분야에서도 DWPose가 KD를 이용해서 RTMPose가 이룬 SOTA자리를 빼앗았습니다. 물론, 그뒤에 RTMPose가 데이터를 대량으로 가져다가 학습시켜서 다시 그 자리를 찾았지만요.🤣
그러나, KD에도 한계가 있었는데요. 같은 구조를 가진 모델만 KD가 가능하다는 것이였어요. 예를 들어서 ResNet계열은 ResNet끼리만...swin은 swin끼리만... 딱 듣기만 해도 조금 답답하죠? 그래도, 그 뒤로는 CNN계열끼리는 서로 공유할 수 있고.. 그런 KD 연구가 또 나왔어요. 하지만, Transformer와 CNN간의 KD는 여전히 어려운 일이었죠.
그런데!! 그걸 가능한 연구가 바로 오늘 소개할 One-for-All 논문입니다. 오랜만에 ZhiHu에 들어갔더니, 王云鹤(YunHe Wang)의 NeurIPS23에 제출하신 새로운 논문 포스팅이 있더라구요. 王云鹤님은 HuaWei Lab에서 연구하시고, VanillaNet을 연구하신 분으로, 이번 논문의 교신저자로 참여하셨습니다. 전에 이분의 대단한 포부를 본 적 있는데, 하나씩 이뤄가시는 느낌이네요. 존경합니다. 👍
논문이 많이 어려운 편도 아니고 knowledge distillation을 흥미롭게 풀어가기 때문에 읽어보시길 추천합니다!
https://arxiv.org/abs/2310.19444
https://github.com/Hao840/OFAKD
https://gitee.com/mindspore/models/tree/master/research/cv/
Introduction
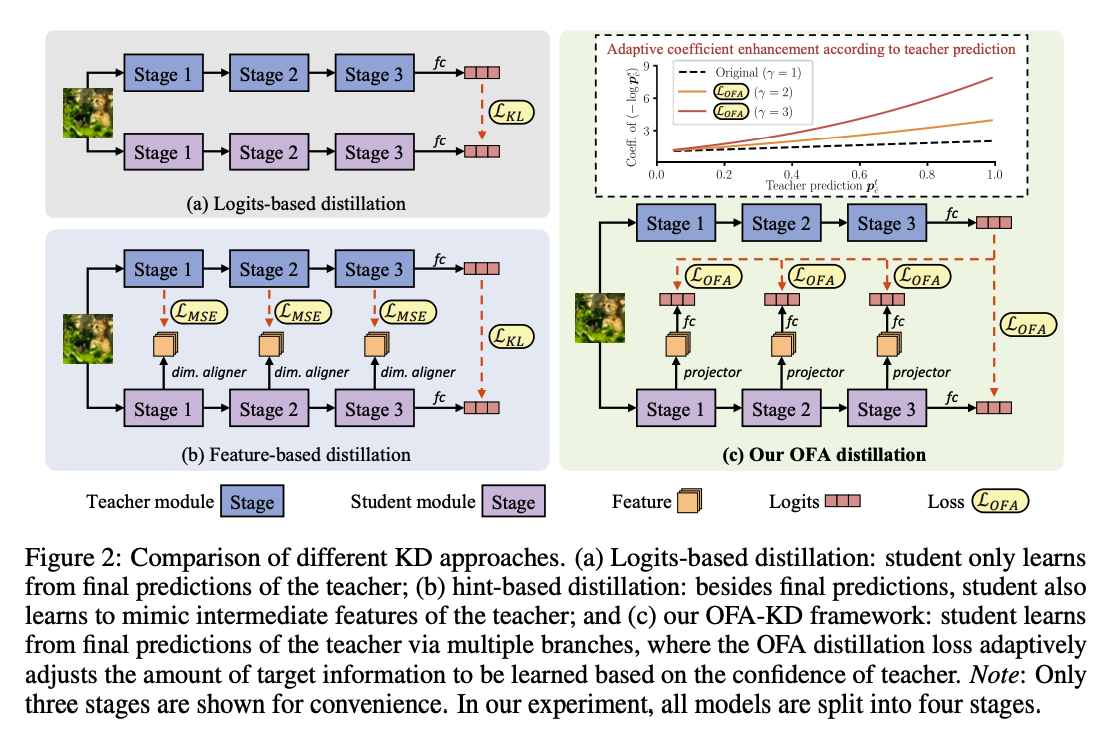
Knowledge Distillation의 main idea는 teacher model의 output이나 soft label을 student model이 따라할 수 있도록 하는 것입니다. 최근, 중간 feature를 hint로 사용하는 KD 방법론은 더 좋은 성과를 얻었습니다. 그러나, 현재까지의 연구는 같은 구조를 가진 모델끼리만 가능했고, 계속해서 새로운 구조의 모델이 출현 및 성능 개선되는 현재에는 다른 구조를 가진 모델을 teacher모델로 사용할 수 있도록 하는 연구의 수요가 늘었습니다. 최근 CNN 모델끼리 knowledge transfer를 하는 연구도 있었을 뿐만아니라 ViT student를 CNN teacher를 사용하여 성공적으로 학습시킨 사례또한 생겼습니다. 저자들은 위의 연구들을 토대로, CNN, Transformer, MLP와 같이 모든 구조를 student/teacher로 학습할 수 있는 방법을 연구하고 제안했습니다.
이전 연구들은 teacher와 student가 같은 구조를 갖고, feature space의 representation이 비슷했고, 이런 점에서 MSE와 같은 방법으로 정보를 distillation할 수 있었습니다. 그러나, teacher와 student의 구조가 다르면, 둘의 latent feature space가 다르기 때문에 direct하게 매칭하기 어렵습니다. 이런 어려움을 해소하고자 하는 것이 저자의 main contribution입니다.
- mismatched representation에 student에 exit branch를 추가하여 정렬된 logits space로 바꿔, teacher의 classifier layer와 매칭하여 구조가 다른 모델끼리 knowledge distillation 수행
- modifief KD loss 제안 (OFA loss)
저자들의 OFA-KD 방법은 CIFAR-100에서 8%, ImageNet-1K에서 0.7%의 개선이 있었다고 합니다.
Method
Revisit feature distillation for heterogeneous architectures
Knowledge distillation
KD에서 가장 흔하게 사용되는 knowledge는 Logits와 feature입니다. Logits은 모델의 추론 분표를 표현합니다. Logit-based distillation은 student가 teacher의 output logits를 따라하도록 하는 것으로 식으로 표현하면 아래와 같습니다.
- : 샘플과 class label의 joint distribution
- 와 : student와 teacher의 샘플 에 대한 추론값
- : cross-entropy, : KL divergence
- : one-hot label 와 soft label 의 trade-off 조정 hyper-parameter
Hint-based distillation은 student를 학습하기 위해 중간 레이어에서 더 fine-grained한 teacher activation을 선택합니다.
- : teacher와 student의 feature
- : teacher feature의 dimension에 맞춘 student를 map한 feature projector
Challenges in heterogeneous feature distillation
feature를 서로 맞추기 위해서 사용하는 convlotional projector는 같은 모델 구조에 만 적용되기 때문에, 서로 다른 모델의 diverse한 feature를 맞추기는 어렵습니다. 게다가 ViT는 embedded image patch를 input으로 받고, 몇 모델들은 추가적인 classification token도 가지 때문에 mismatch문제가 더 클 수 밖에 없죠.
Centered kernel alignment analysis
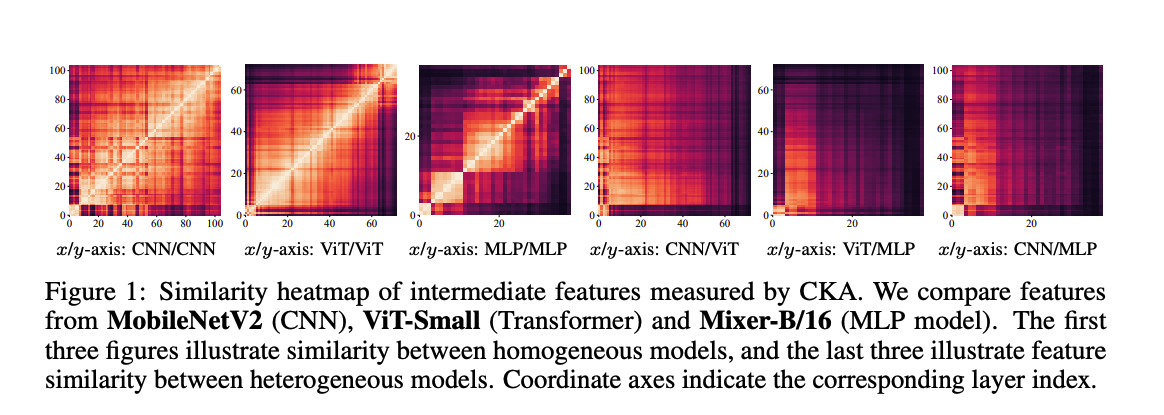
서로 다른 구조의 모델의 representation gap을 보이기 위해서, 저자들은 centered kernel alignment(CKA)를 사용하여, CNN, ViT, MLP모델들로부터 추출된 feature들을 비교했습니다. CKA는 서로 다른 구조를 가진 모델이 서로 다른 input dimension을 가져도 feature similarity를 비교할 수 있는 방법입니다.
CKA는 mini-batch마다 feature similarity를 측정합니다. 와 은 샘플 에서 서로 다른 모델에서 추출한 feature하고 할때, CKA는 아래와 같습니다.
- (Gram matrices of features)
위 식처럼 계산하는 CKA를 모델들에 적용하면 Figure 1과 같습니다. 논문에 나온 내용은 아니지만, CKA 시각화 결과를 볼때는 밝은 부분(값이 1에 가까움)이 많을수록 두 피쳐가 서로 닮았다는 뜻 입니다. 딱봐도 비슷한 구조끼리는 feature도 닯았다는 것을 알 수 있습니다. 반대로 구조가 다른 경우 CKA가 0에 가깝고 figure가 어둡기 때문에 서로 연관성이 적다라는 것이죠. 따라서, feature가 다르기때문에, 서로 다른 모델들은 hint based distillation은 사용하기에는 어려움이 있는 겁니다. 그럼 좀 더 feasible한 logits만 사용해서 distillation을 해야하는 것일까요? 그렇지 않습니다. 중간 layer에 supervision 없이는 최적의 방법이 될 수 없기 때문이죠.
Generic heterogeneous knowledge distillation
저자는 위에서 언급된 서로다른 구조를 가진(heterogeneous) 모델간의 KD 어려움을 극복할 수 있는 방법을 제안합니다.
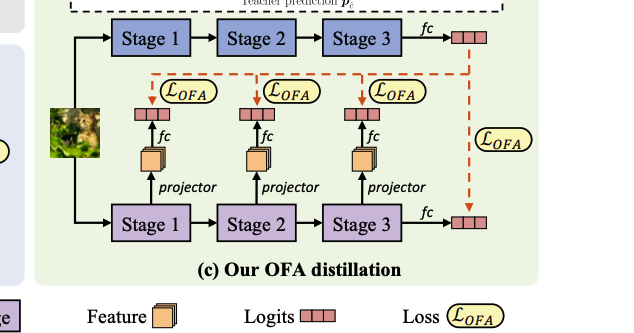
Learning in the logits space.
위에서 CKA 분석 결론에 따라, 구조가 다른 모델간의 distillation은 서로 맞지 않는 representation을 맞추는 것이 가장 메인입니다. 그러나, 앞서 언급된 것처럼, convolutional projector를 사용해서 feature dimension을 정렬하는 기존의 방법은 서로 다른 구조를 가진 모델들에게는 적합하지 않죠. 이에 저자들은 early-exit 모델 구조처럼 student에 추가적인 exit branch를 도입하여 logit space에서 feature를 조정하는 방법론을 제안했습니다. 또한, 저자는 하나의 feature projector와 classifier layer로 각 exit branch를 만들었습니다. teacher쪽은 마지막 output을 knowledge로 사용합니다. logits space에서 redundant architecture-specific 정보는 지워지고, 그에 따라, feature alignment가 모든 구조에도 적용될 수 있게 되는거죠. 학습할때는 이 exit branch를 student backbone과 함께 최적화 시키고, 테스트시에는 이 브랜치를 제거하기 때문에, 또다른 overhead가 생길 염려를 하지 않아도 됩니다.
Adaptive target information enhancement
서로 다른 두 모델이 위에 제안된 방법으로 logit spaces에서 같은 target을 학습하게 되겠지만, 그들의 작은 차이(inductive bias)가 어떤 결과를 가져올지 모릅니다. 어쩌면, 작은 차이때문에 결국 두 모델이 학습한 분포가 달라져버릴 수 도 있겠죠. 이런 차이를 줄이기 위해서, 저자들이 사용한 방법은 다음과 같습니다.
target class에 관한 정보를 분리하기 위해 original distillation loss를 변형합니다.
- : predicted class, : target class
위에서 저자들은 gradient와 상관없기 때문에, KL-divergence의 denominator 부분을 사용하지 않습니다.
그리고, target class의 정보를 강조하기 위해, 조정 parameter 을 를 적용합니다.
Expreriments
Result

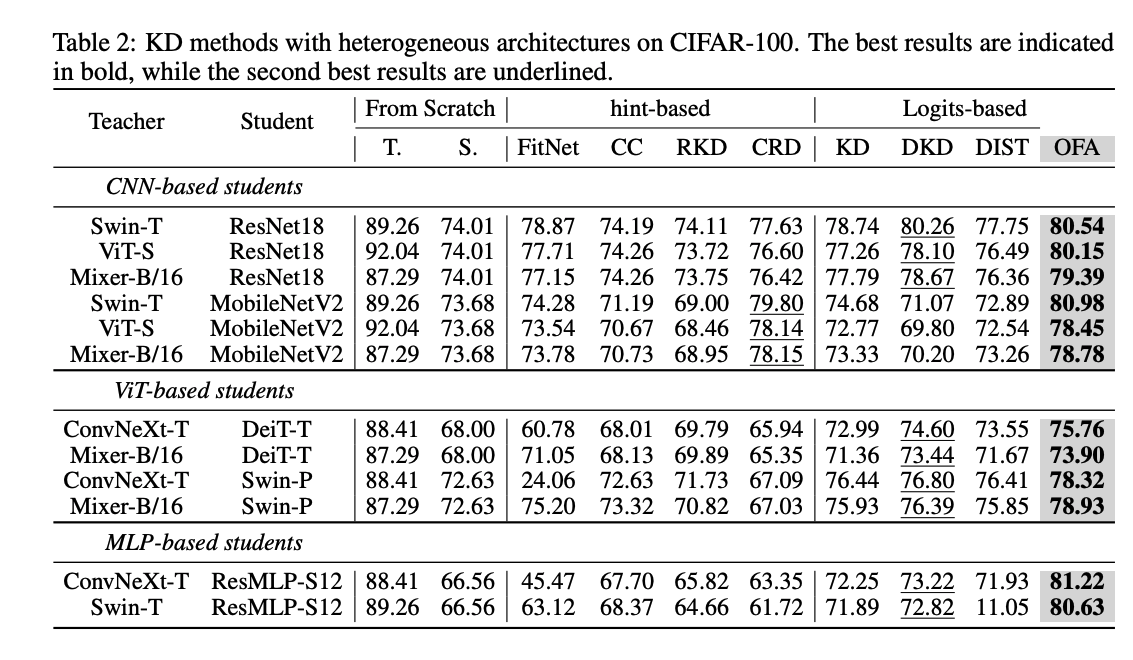
Ablation study
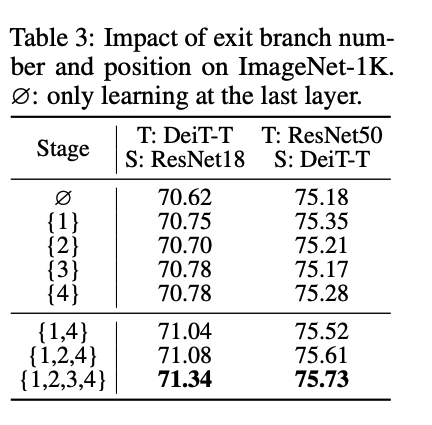
- Exit branch의 개수와 위치
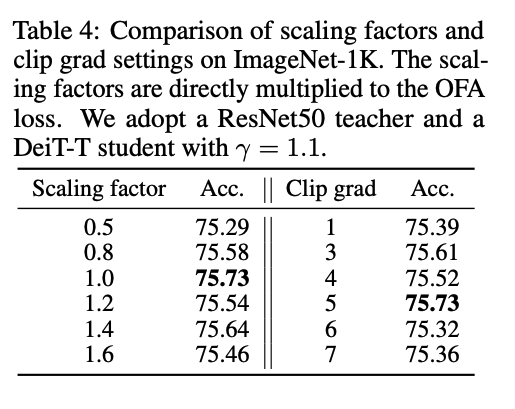
- OFA loss의 scale
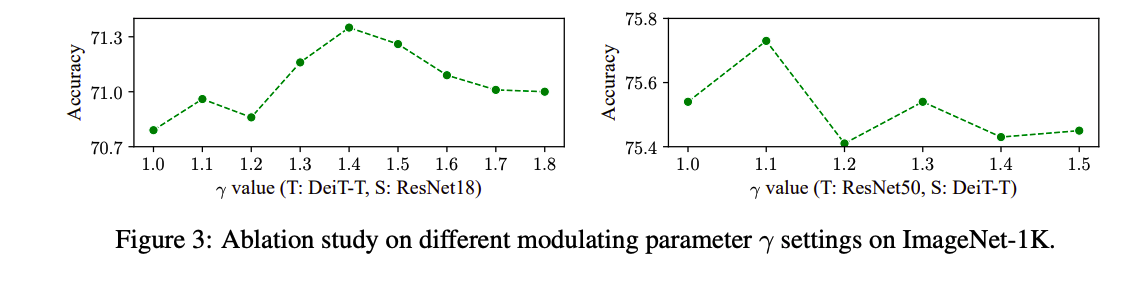
- 파라미터 조정
- 같은 구조의 모델간 KD 방법

- 같은 구조의 teacher vs 다른 구조의 teacher

Conclusion
위의 experiments 섹션에서 볼 수 있듯이, 저자들이 제안한 방법은 서로 다른 구조를 가진 모델간에 knowledge distillation이 가능하게끔 하는 성공적인 연구였습니다. 뿐만 아니라, 제안한 방법은 기존에 사용하고 있던 같은 모델끼리의 KD의 효과도 뛰어넘었다는면에 큰 의미가 있습니다.
Limitation
ResNet-50에서는 효과가 있었지만, ResNet-18은 서로 다른 모델을 teacher보다 같은 계열에 더 효과가 있었다고 합니다. 또한 파라미터를 조정하는 것이 쉽지 않고, 파라미터의 영향에 따라 결과도 많이 달라진다는 점이 위 연구의 한계입니다.
