[논문] Visibility Aware Human-Object Interaction Tracking from Single RGB Camera

오늘 리뷰할 논문은 타이틀을 보고 호기심이 딱 가더라구요. 포즈쪽에 관심이 있다면 누구나 궁금할 것 같아요.
- Human... Tracking: 일단 pose estimation 기능이 있고,
- Object... Tracking: Object에 대해서도 tracking을 하고
- Human-Object Interation: 사람과 사물의 상호작용을 인식하고, (!)
- from Single Camera: 위의 세 주제를 한 RGB 카메라에서, (!)
- Visibility Aware: occlusion에 robust하게 (!!!)
그리고, 결과 동영상(https://www.youtube.com/watch?v=YzLkOJdvRRE)을 보면 더 일어보고 싶어집니다. 그리고 더욱 의미가 있다고 생각한 이유는 물체가 인체에 닿아있는지에 대한 contact 정보도 같이 준 다는 점도 의미가 놀랍죠.
현재 시점에 2D/3D Pose estimation은 어느정도까지 성능이 정점에 닿았기 때문에, 더 확장된 기술을 필요로 합니다. 가장 대표적인 것 중 하나가 Human-Object Interation이죠. 하지만 문제는 물체는 형태가 매우 다양하고, 사람에 의해서 가려지기 때문에, 그 형태를 reconstruction하기에는 많은 challenge들이 있죠. 그쪽 분야를 진지하게 파고 있는 곳이 오늘 논문의 저자 Xianghui Xie, Bharat Lal Bhatnagar, Gerard Pons-Moll님입니다. 독일의 튀빙겐 대학 소속으로 Real Virtual Human 연구소에서 People in Clothing, 3D Shape Learning, 3D human Body Registration, Human Motion from Wearables를 연구합니다. 그리고 이 조직 구성원중에 익숙한 분이 있더라구요. 바로 Metrabs의 저자 István Sárándi님입니다.😲 엄청난 조직이죠...
오늘의 논문은 CVPR2023에 accept된 Real Virtual Human팀의 두 논문 중 하나인데, 다른 논문들도 많은 학회에서 활약하고 있으니 관심있게 봐야겠습니다. 또한, 이 논문은 같은 저자들의 BEHAVE dataset과 CHORE을 기반으로 연구했습니다.
https://virtualhumans.mpi-inf.mpg.de/VisTracker/
https://virtualhumans.mpi-inf.mpg.de/VisTracker/VisTracker.pdf
https://github.com/xiexh20/VisTracker
Introduction
RGB이미지에서 3D human이나 object를 추출하는 것의 어려움 중 저자가 개선한 포인트는 아래 2가지입니다.
- depth-scale ambiguity로 인한 depth 추정의 어려움
- object나 human의 occlusion으로 인한 어려움
앞선 같은 주제의 연구 중에서, facebook의 PHOSA는 ambiguity를 수작업을 하는 heuristic한 방법을 사용했지만, 그 결과가 정확하지도 않았고, scalable하지도 않았고, 본 논문의 저자들의 CHOREA은 여러 neural 모델들을 사용했지만, fixed depth로 인해서, 프레임간의 일관성이 부족했습니다. 이러한 이전 연구들의 아쉬움들을 보완한 저자들의 연구 main contribution은 다음과 같습니다.
- 하나의 monocular RGB 카메라에서 움직이는 물체와 fullbody human을 한번 tracking 가능한 방법 제안
- SIFNet을 이용한, 일관성있는 human & object 4D tracking 제안
- heavy occlusion에도 robust 방법 제안
- 관련 미래 연구에 기여할 수 있는 public code와 pretrained 모델 제공
Method
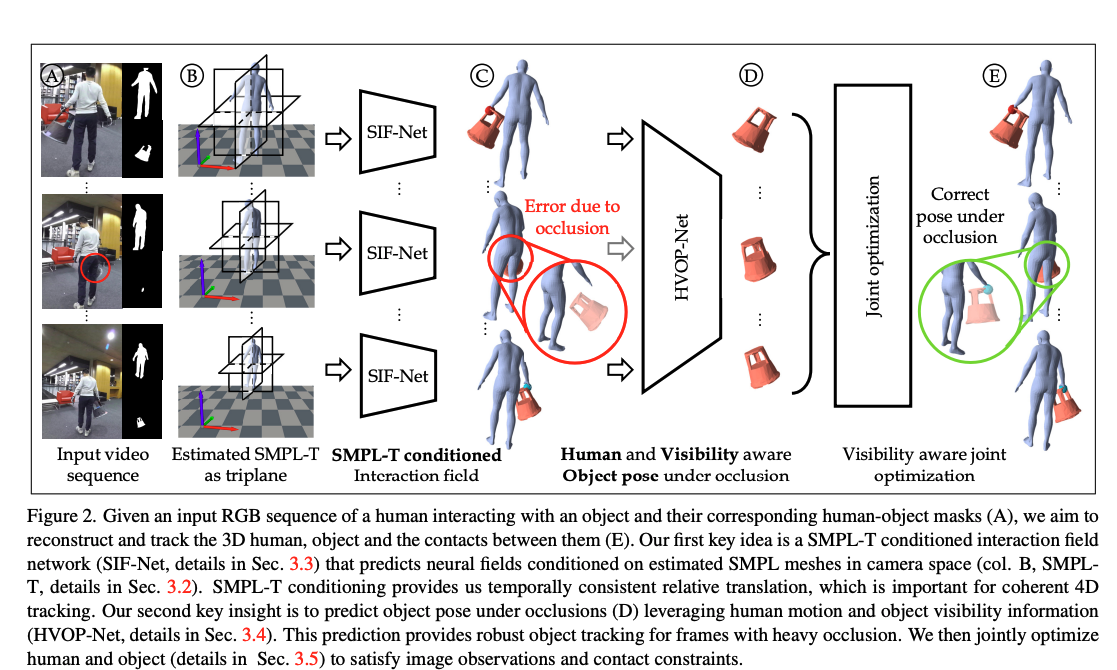
저자가 제안하는 approach는 Fig 2.와 같습니다. 시퀀스 이미지와 그에 따른 사람과 물체의 mask를 input으로 받아 SMPL-T 모델로, 카메라 스페이스에서의 포즈를 추정하고, 다시 SIFNet에서 사람과 물체를 트래킹하고, HVOPNet에서 occlusion에도 강인한 포즈와 object를 완성하고, 그 결과를 마지막으로 최적화합니다.
논문에서 사용하는 notation
- : SMPL body Model (: pose, : shape parameter)
- : object의 rotation과 translation
- : Input sequence (RGB, human & object mask)
- 여기서의 mask는 데이터셋에 포함되어 있지만, 없는 데이터셋에서는 Detectron v2로 human mask를, video segmentation으로 object mask를 추출하여 사용했다고 합니다.
SMPL-T: Temporally consistent SMPL meshes in camera space
저자는 OpenPose로 시퀀스 인풋에서 2D keypoint를 찾고 FrankMocap으로 SMPL-T의 pose 와 를 찾습니다. 그리고 그 mesh의 중점을 원점에 두고, scale과 translation은 전체 frame들의 평균값으로 설정합니다. 이렇게 하는 목적을 2D reprojection과 temporal smoothness를 최소화하고자 하는 목적입니다.
그 error는 다음과 같습니다.
- : body keypoint projection loss의 합
- : 이전 데이터들로 부터 학습된 bodypose에 대한 regularization
- : SMPL-T의 vertices 의 큰 acceleration에 penality를 줄 수 있는 temporal smoothness 식
- : 포즈가 처음보다 너무 많이 바껴있는 것에 대한 방지용 loss
- : loss weight
SIF-Net: SMPL-T conditioned interaction field
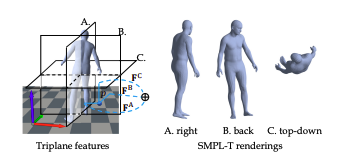
그치만! 위에서 뽑은 건 사람에 대한 포즈고, object에 대한 정보나 그와의 interaction을 추정하진 못하죠. 그래서 하나의 모델을 추가합니다. 그리고, RGB만 넣어주면 fixed depth문제가 생기니, RGB image + human & object mask + 앞서 추정한 SMPL-T 결과도 같이 넣어줍니다. 여기서 주의할 점은!!!! SMPL-T의 결과를 triplane으로 넣어주는 것 입니다. triplane이 라는것은 SMPL-T의 결과물을 전체로 넣는 것이 아니고, camera 를 적용하여 오른쪽, 뒤쪽, 위에서 아래방향의 실루엣 이미지를 넣어주는 것이에요.(Fig 7처럼요!) 왜 전체를 넣지 않고 이렇게 쪼개서 넣는냐?! 불필요할 정도로 많은 양의 계산을 피하기 위해서 입니다.
우선, SIFNet에서는 feature encoding이 이루어집니다. 인코더는 두개가 있는데, 와 입니다. 는 각 에서 pixel aligned feature grid 을 추정합니다. 그리고 query point 를 추출하기 위해서 를 세 plane에 project하기 위해, orthographic projection 를 적용하여, local feature 를 추정합니다. 또한, 이미지에서는 가 feature grid 를 추출하고, 주어진 query point 에 대하여 full perspective projection 를 사용하여, pixel-aligned feature 를 추정합니다. 마지막으로, 이 두 encoder에 추정된 feature는 concatenate되어 하나로 완성됩니다.
위에서 추정된 feature 들에서 SIFNet의 decoder head로, 최종적으로 다음 output들을 추정합니다.
- train
- ()human과 object mesh사이의 unsigned 거리
- 그 거리가 아주 작을때 얻게 되는 contact정보
- ()object의 rotation과 translation
- ()human과 object mesh사이의 unsigned 거리
- test time
- ()object 표면상의 point, 그 point의 rotation, translation
- () [0,1]로 표현되는 object visibility mask
HVOP-Net: Human and Visibility aware Object Pose under occlusions
이전까지는 프레임 단위로 inference가 이루어졌다면, HVOP-Net에서는 occlusion이 고려된 human pose와 object와 그 사이의 interaction을 더 정확히 추정하기 위해서 transformer기반의 모델을 추가하여, 시퀀스단위로 input을 받게 됩니다.
첫째로, 각 프레임에 대한 SIFNet의 Head인 visibility decoder 의 결과를 평균내어, visibility score를 결정합니다. 다음은, occlusion에 대해서 확실하게 결과를 추정할 수 있도록, visibility score 가 0.5보다 작으면 occlusion이 발생된 frame으로 고려합니다. 이러한 object visibilty와 pose를 함께 transformer에 입력합니다. 여기서, transformer 도 두가지로 나뉘는데, SMPL-T transformer 와 object transformer 입니다.
Visibility aware joint optimization
다음은 위의 과정에서 얻어진 정보들로, contact constrain를 만족하는 SMPL과 object의 mesh를 완성하는 과정으로 파라미터를 얻어야합니다. 이때 human data , obejct data, contact data , SMPL prior term 는 다음 energy function을 따릅니다.
각 data에 대한 공식은 아래와 같습니다.
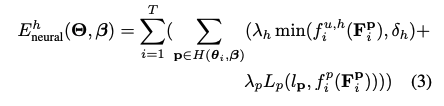
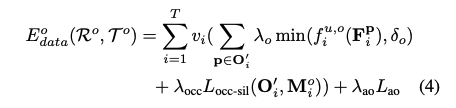
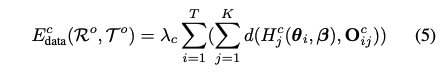
Experiments
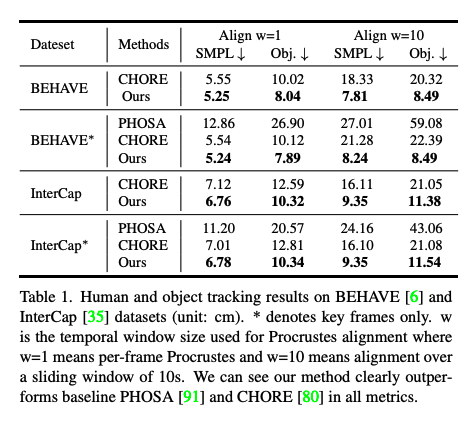
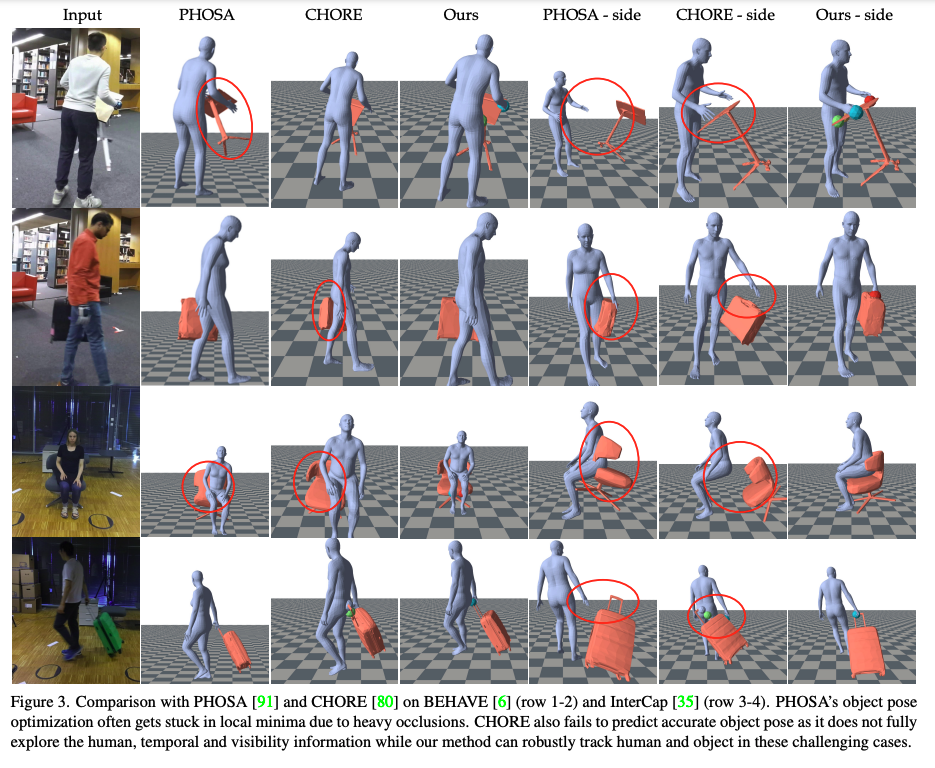
Evaluation of tracking results
Importance of SMPL-T conditioning
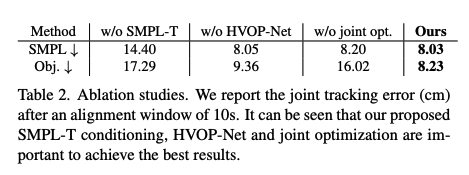
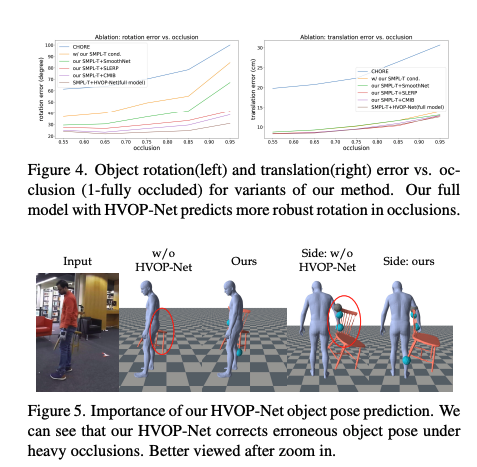
Importance of HVOP-Net
Generalization

Limitations

저자들이 제안한 방법은 정말 훌륭한 결과를 보여주었지만, 여전히 약간의 한계가 있다고 합니다. 예를 들어, 가려져있는 프레임들동안, 물체가 너무 많이 움직이게 되면, 결과 추정에 어려움이 있다고 합니다. 또는 물체가 대칭형이거나 포즈가 너무 특이한 경우에도 실패하는 경우가 있다고하네요.
Appendix
Runtime Cost
- SMPL-T pre-fitting: 6.38s,
- SIF-Net object pose prediction: 0.89s,
- HVOP-Net: 1.3ms,
- joint optimization: 9.26s,
- total: 16.53s.
