1. 프로젝트 개요
1.1 프로젝트 주제
: 재활용 품목 분류를 위한 Object Detection
1.2 프로젝트 목표
: 본 프로젝트는 사회적인 쓰레기 문제 중 하나인 분리수거를 Object Detection 기술 적용을 통해서 효과적인 방안 제시한다.
2. 수행 과정
: 본 프로젝트는 다음과 같은 실험환경구축을 기초로 한다.
GPU - Tesla V100-SXM2 32GB
OS - Ubuntu 18.04.5 LTS
DE - Jupyter notebook, Visual Studio Code
2.1 탐색적 데이터 분석 (EDA)
2.1.1 Dataset
Dataset : 1024*1024 사이즈, 9754개의 image(train - 4883장, test - 4871장, COCO format).
Class : 10개.(General trash, Paper, Paper pack, Metal, Glass, Plastic, Styrofoam, Plastic bag, Battery, Clothing)
2.1.2 EDA
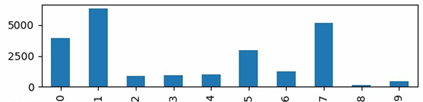
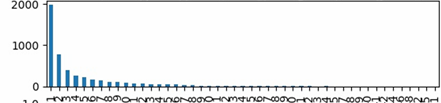

: 그림(a) 분석 결과로 Class Imbalance가 training에 영향을 줄 것으로 예상했던 것과 달리, 1-9 class에 대해서 좋은 결과를 보였다. 하지만 0번 class(General trash)의 다양성으로 인해 추론 결과가 비교적 좋지 못하다라는 분석이 나왔다. 그림(b)는 validation set을 제작하는데 큰 기여를 하였다. 또, Augmentation을 위해서 bbox가 어느 부분에 집중되어 있는지 그림(c)를 통해 관찰하였다.
2.1.3 Validation dataset
빈도가 높은 bbox class를 각 이미지의 class로 정의한 뒤 class별로 이미지를 분류하고, Stratified K-fold 이론을 바탕으로 각 class를 5등분하여 validation set을 구성한다. 이때, 동일한 class의 bbox가 다수 중복된다면 random하게 하나를 선정한다.
대회 기간을 효율적으로 사용하기위해 다섯 세트의 데이터셋중 LB-Score와 선현성을 보이는 한 세트를 실험 데이터셋으로 이용한다.
2.2 모델 실험
2.2.1 실험 Model
: MMdetection 라이브러리에서 제공하는 Swin_Transformer_tiny, DetectoRS, GA_FasterRCNN과 개별적으로 작성된 YOLO_v5.6와 EfficientDet을 본 프로젝트의 실험 모델로 선정하였다.
2.2.2 데이터 증강(Data Augmentation)
: Random flip(horizon), HSV, Brightness, Contrast등의 이미지 조정과 Mixup, Mosaic등의 데이터 생성을 통해 데이터 증강을 실현하여 선택적 조건으로 실험하였다.
2.2.3 기타 실험 조건
성능 향상을 위해 다양한 이미지 사이즈(1024, 512, 256), Optimizer(SGD, Adam, AdamW), LR_scheduler(Step, Cosine_Annealing, Cosine_Restart)등을 달리하면서 실험했다.
2.3 앙상블
다양한 조건에서 모델들을 조합하여 Weighted Box Fusion을 바탕으로 앙상블하였고, 성능 향상의 효과를 얻었다.
3. 총평
3.1 프로젝트 결과
3.1.1 개별 모델 성능
: 아래 표는 데이터 증강없이 (1024,1024)사이즈의 이미지로 실험한 경우의 결과이다.
| YOLO_v5.6 | Swin_T | FasterRCNN | DetectoRS | EfficientDet | |
|---|---|---|---|---|---|
| LB Score(mAP_50) | 0.616 | 0.530 | 0.532 | 0.497 | 0.350 |
3.1.2 최종모델 성능
LB score 상위 3개의 모델 Yolov5, SwinT, FasterRcnn을 앙상블하여 가장 좋은 모델을 완성하였다. 최종 제출 결과는 다음과 같다.
| Private LB mAP_50 | Public LB mAP_50 | |
|---|---|---|
| Ensemble | 0.636 | 0.648 |
3.1.3 재활용 품목 Object Detection결과

: 앙상블 결과를 시각화하여 관찰했다. localization은 우수한 반면, classification에서 오류가 다소 있었다. 특히 General trash를 잘 구분하지 못하는 경우가 가장 많았다.
3.2 회고
모든 팀원들이 저번 이미지 분류대회를 포함하여 최소 한번의 대회 참여한 경험이 있었기 때문에 이번 대회는 좀 더 체계적으로 진행될 수 있었다. 첫 주는 EDA와 다양한 모델들을 다루는 시간이 되었다. 한정된 시간과 gpu를 보다 효율적으로 활용하기 위해서 계획적인 면모를 보였다. 또, 피어세션을 적극 활용하여 의견을 공유하고 방향성을 토의했다.
아쉬운 부분도 있었다. 첫째, 이번대회의 평가 지표는 mAP_50이였다. Inference에서 confidence score의 하한선을 작게 주면 상대적으로 좋은 수치가 나온다는 사실이다. 이 부분에서 과연 이 기준이 실제 현업에서도 본 프로젝트와 같은 모델을 개발할 때 적용되는 것이 옳은 것인가라는 의문이 조금 들기도 했다.
또, Pseudo labeling을 올바르게 활용하지 못한 부분도 있었다. 다음부터 주의할 점은 다음과 같다. 높은 mAP_50을 보인 inference 결과를 pseudo labeling에 활용한다. 이때, inference data를 만드는 모델과 pseudo labeling을 적용하는 모델은 동일하도록 한다.
저번 대회보다 발전된 모습이 있었지만 아쉬운 부분도 있었던 대회였다. 하지만, 이런 시행착오들이 다음 대회에서는 보다 나은 과정과 결과를 만들 수 있을 것이라 확신한다. P_stage는 멘탈 싸움같다. 대회를 거듭하며 자존감을 잃지 않고 꾸준하게 목표로 향하는 페이스가 가장 중요하다. 이처럼 꾸준한 내모습이 어떤 미래를 만들지 매우 기대된다.
