[Day4] 2021/09/30
강의 리뷰
Object Det 5강 - 1 stage Detectors
-
localization과 classification을 순차적으로 수행하는 2 stage detecotr는 속도가 느리다는 점에서 real world에서 응요하기 어렵기 때문에 1 stage detector가 등장했다. 따로 rpn없이 feature map에서 객체를 뽑아낸다. ex) YOLO,SSD,RetinaNet...
-
YOLO v1
- region proposal 없이 전체적인 맥락적 이해.
- Pipeline
- GoogLeNet 변형: 24개의 conv(특징 추출), 2개의 fully connected layer(box의 좌푝밧과 확률계산)
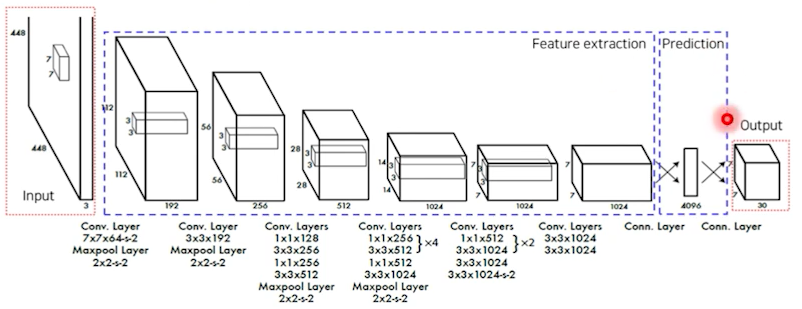
- SS그리드 영역으로 나누고, 각 그리드마다 B개의 bbox와 confidence score계산. confidence = Pr(object) IOU(truth,pred)
- 각 그리드 영역마다 C개의 class에 대한 확률을 계산
- output: 7730, 한 그리의 채널 30개 => 5개 첫bbox의 정보(x,y,w,h,c), 5개의 두번째 bbox의 정보, 20개의 class.
- loss = localization loss + confidence loss + classification loss - 빠르고 정확한 성능.
-
SSD
- yolo는 그리드보다 작은 객체를 검출할 수 업고 마지막 feature만 사용해서 정확도가 하락.
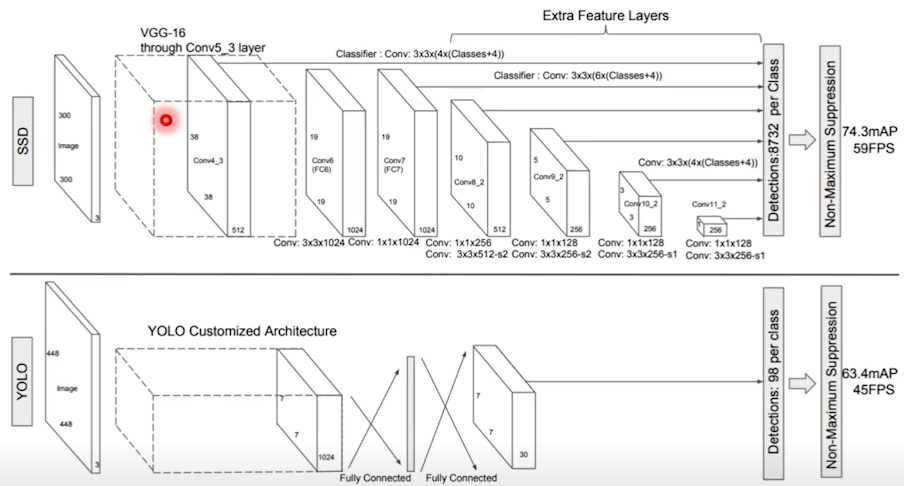
- Extra conv들의 feature map을 모두 detection 수행: 6개의 서로 다른 scale의 feature map(큰 것은 작은 물체 탐지, 작은 것은 큰 물체 탐지)
- Fully connected layer대신 conv만 써서 속도 향상.
- Default box사용(Anchor box)
- Pipeline
- VGG-16 + Extra conv(6개), input: 300300
- Multi-scale feature maps: C = N(bbox) (offsets +N(c)), 정보 4개 + 클래스(배경포함) 21개.
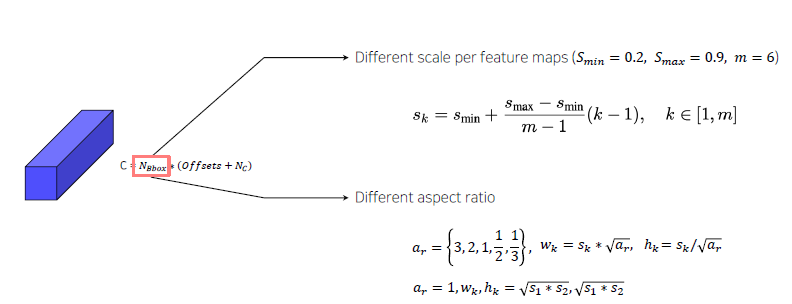
- output: n * n * (#default_box * (offset + #class) ) - Training
- Hard negative mining 수행
- Non maximum suppression 수행
- loss = localization loss(smooth L1) + classification loss(softmax)
- yolo는 그리드보다 작은 객체를 검출할 수 업고 마지막 feature만 사용해서 정확도가 하락.
-
Yolo v2
- 더 정확하고 빠르며 더 많은 예측.
- batch normalization추가
- high resolution classifier: 224224->448448
- convolution with anchor boxes: fully connected layer제거, K means cluster on COCO datasets(5개의 anchor box)
- Fine-grained features: 크기가 작은 feature map은 low level이 부족하기 때문에 Early stage feature map을 합쳐주는 passthrough layer도입
- Multi-scale training: {320.352,...,608}
- Darknet-19: fully connected layer제거, 3*3conv추가
- WordTree 구성.
- ImageNet(detection) : COCO(classification) = 4:1
-
YOLO v3
- Darknet-53
- Max pooling제거, conv stride 2
- Multi-scale feature map: 5252, 2626, 13*13
-
RetinaNet
- 1 stage detector는 RPN이 없이 그리드를 나누기 때문에 background를 포함할 수 있음.
- facal loss: cross entropy loss + scaling factor, 쉬운 예제에 작은 가중치, 어려운 예제에 큰 가중치.

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)