[week17] 2021/11/24
모델 경량화 1강 - 모델 경량화 기법 101 - CV
어떤 경량화를 적용해야하는가?
- 주어진 환경에 따라 방향성이 달라진다
- Deploy 환경(CPU/GPU)
- 주된 문제 상황(latency를 줄여한다/ Edge device여서 Model size를 줄여야한다)
- 경량화 요구 정도(성능 drop을 감수할것인가)
- HW리소스(From scratch로 재학습이 가능한가?)
경량화의 종류
- 효율적인 archituecture
- *Pruning
- *knowledge distillation
- weight factorization(Truck decomposition)
- Quantization
Pruning
- 중요도가 낮은 파라미터를 제거하는것.
- 어떤 단위로?
: Structured(group) / Unstructured(fine grained) - 어떤 기준으로?
: 중요도 정하기(Magnitude(L2,L1), BN scaling factor, Energy-based, Feature map...) - 기준은 어떻게 적용?
: Network 전체를 줄 세워서 (global), Layer마다 동일 비율로 기준(local) - 어떤 phase에?
: 학습된 모델에 / Initialze시점에
Structured
- 파라미터를 group단위로 pruning(그룹: channel/filter/layer level)
- Masked(0으로 pruning된) filter제거시 실질적 연산횟수 감소로 직접적인 속도 향상
- (논문 1) Learning Efficient Convolutional Neteorks through Network sliming
: Sturctured(group), BN scaling factor, Global, trained model. -> VGG11, 50% proning, FLOPs 30.4%, 파라미터 82.5% 감소- Scaling factor
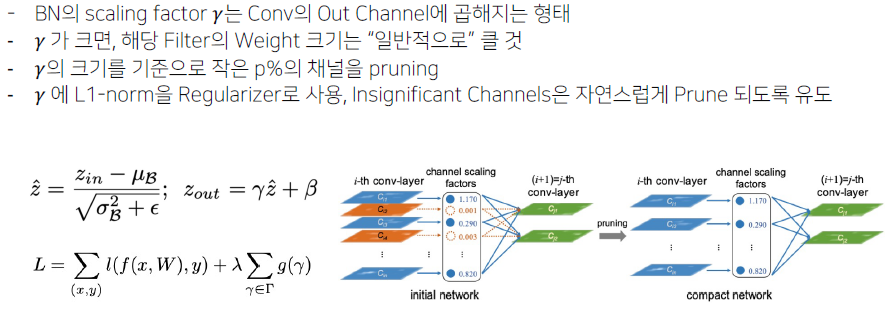
- Scaling factor
- (논문 2) HRank: Filter Pruning using High-Rank Feature Map
: Structured, Feature map의 Rank(SVD), Local, 학습된 모델에. ResNet50, FLOPs 44%감소 1.17%성능 하락.- 이미지에 따라 Feature map output은 당연히 달라지므로, 그때마다 SVD rank개수가 달라지는것아닌가? => 각 다른 batch(이미지들)로 계산한결과 차이가 없음을 실험적으로 증명.
- Rank 계산과정:

Unstructured
- 파라미터 각각을 독립적으로 Pruning
- 수행할수록 네트워크 내부의 행렬이 점점 희소(sparse)해짐
- Sturctured Pruning과 달리 Sparse Computation에 최적화된 소프트웨어 또는 하드웨어에 적합한 기법
- (논문 1) The Lottery Ticket Hypothesis: Finding Sparse, Trianable Neural Networks
: Unstructured, L1norm, Global, 학습된 모델에, 아주 약간 prune하고, 재학습, 아주 약간 prune하고 재학습 을 반복(iterative pruning). 보통 pruned된 sparse한 모델들은 일반적으로 초기치로부터 학습이 어렵지만, 잘되는 방법을 제시.- Lottery Ticket Hypothesis
: Dense, randomly-initialized, feed-forward net은 기존의 original network와 필적하는 성능을 갖는 sub networks(winning tickets)를 갖는다 - 10-20%의 weight만으로, 원 network와 동일한 성능을 냄.
- Identifying winning tickets

- Lottery Ticket Hypothesis
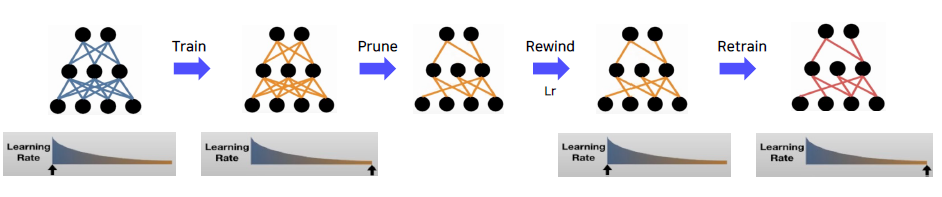
- (논문 2) Stabilizing the Lottery Ticket Hypothesis; Weight Rewing
- LTH의 경우 데이터셋 또는 네트워크의 크기가 커졌을때 불안정
- k번째 epoch에서 학습한 파라미터로 네트워크를 초기화하면 학습이 안정화된다.

- (논문 3) Comparing Rewinding And Fine-tuning In Neural Network Pruning; Learning Rate Rewinding
- Weight rewinding대신, weight는 유지하고, 학습했던 learning rate scheduling을 특정 시점(k)로 rewinding하는 전략을 제안.
- 어느 시점의 weight를 rewind할지에 대한 파라미터 고민 없이, learining rate at 0으로하여 재학습. 대체로 좋은 성능을 보임
- (논문 4) Linear Mode Connectivity and the Lottery Ticket Hypothesis
- 네트워크의 학습 및 수렴 관련된 실험
- 특정 학습 시점(epoch at 0,k)에서 seed를 변경하여 두개의 Net을 학습 -> SGD를 통한 결과가 다르므로, 다른곳으로 수렴
- 둘간의 weight를 linear interpolation하여, 성능을 비교
- 두 weight공간 사이의 interpolated net들의 성능을 확인
- (논문 5) Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
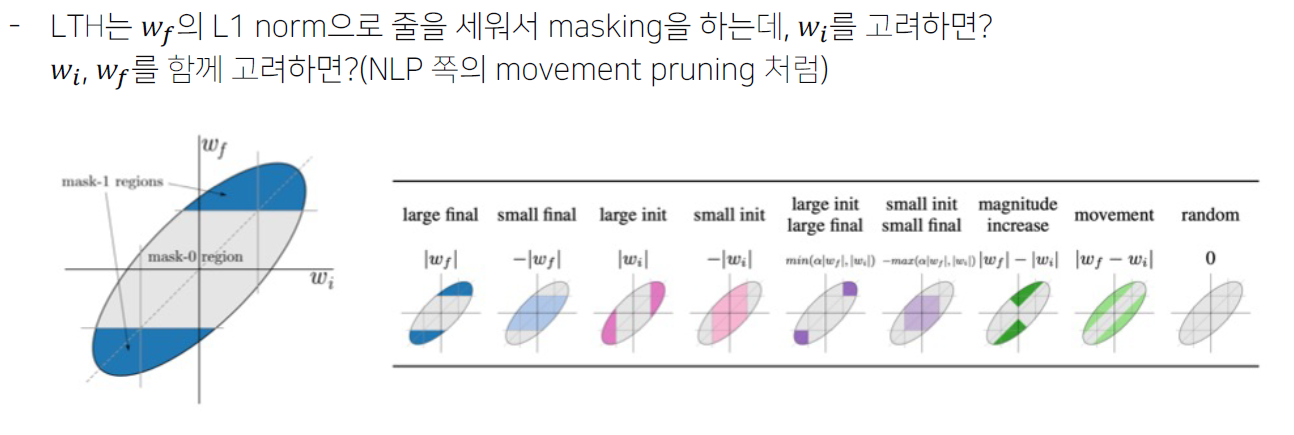
Pruning at initialization(unstructured)
- Train 이전에 "중요도"(떡잎)을 보고 Pruning을 수행하자 그후 train하면, 시간이 훨씬 절약된다.
- 중요도 계산

Knowledge Distillation
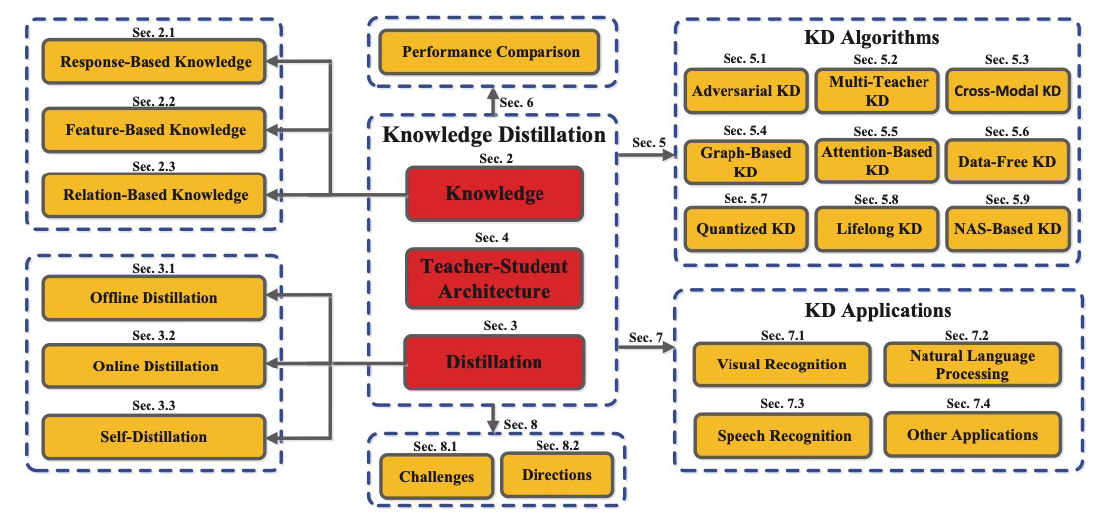
- Response-Based knowledge Distillation
- Teacher model의 last output layer를 활용하는 기법, 즉 직접적인 final prediction을 활용
- 대표적으로 hinton loss
- Feature-Based Knowledge Distillation

- 논문들의 주된 방향은,GFeatureGdistillation 과정에서 유용한 정보는 가져오고, 중요하지 않은 정보는
가져오지 않도록 Transformation function과 distance, 위치 등을 조정하는 것 - Relation-Based Knowledge Distillation
- 다른 레이어나, Sample”들”G간의 관계를 정의하여 knowledge distillation을 수행
- Relation among examples represented by teacher to student

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)