이번에 리뷰할 논문은 지난 VoVNet V1에 이는 VovNet V2 입니다. VoVNet은 한국의 ETRI에서 낸 논문이자 CVPR 2020에 등재된 논문인데요! 두 논문 모두 CVPR에 등재됐다니 멋있습니다. 😍
그리고 Abstract의 마지막 문장에 "We hope that CenterMask and VoVNetV2 can serve as a solid baseline of real-time instance segmentation and backbone network for various vision tasks, respectively"라고 쓰셨는데, 저도 응원합니다!
https://arxiv.org/pdf/1911.06667v6.pdf
https://github.com/youngwanLEE/CenterMask.
Abstract
- CenterMask 제안
- VoVNet V2 + SAG-Mask
- Mask RCNN 처럼 achor-free one stage object detector에 새로운 spatial attention-guided mask (SAG-Mask) branch를 더 하는 방법.
- SAG-Mask: detect된 박스안에서 spatial attention map을 통해 segmentation mask를 추측하는 방법
- VoVNet V2 제안
- residual connection으로 VoVNet V1의 최적화 문제를 해결
- original SE Module보다 좋은 effective Squeeze-Excitation(eSE) 제안
- ResNet-101-FPN + CenterMask로 SOTA등극 (38.3%)
- 35 fps (Titan XP기준)
Introduction
Object detection의 발전과 함께 instance segmentation도 박스를 추측하고, 그 박스 안의 pixel을 predict하는 MaskRCNN과 이것을 개선하는 CenterNet 등의 많은 방법론들이 나왔습니다. 하지만, 이 방법들은 real-time에서는 불가능했고, 첫번째로 real-time이 가능하게 했던 모델인 YOLACT는 정확도가 부족했습니다. Accuracy와 speed 모두 만족하기는 힘들었는데, 저자들은 이 두마리 토끼를 다 잡고자 합니다.
저자들은 Mask R-CNN과 비슷한 방법인 새로운 spatial attention guided mask를 도입함으로 one-stage anchor-free detector의 새롭고 효과적인 CenterMask를 만들어냅니다.
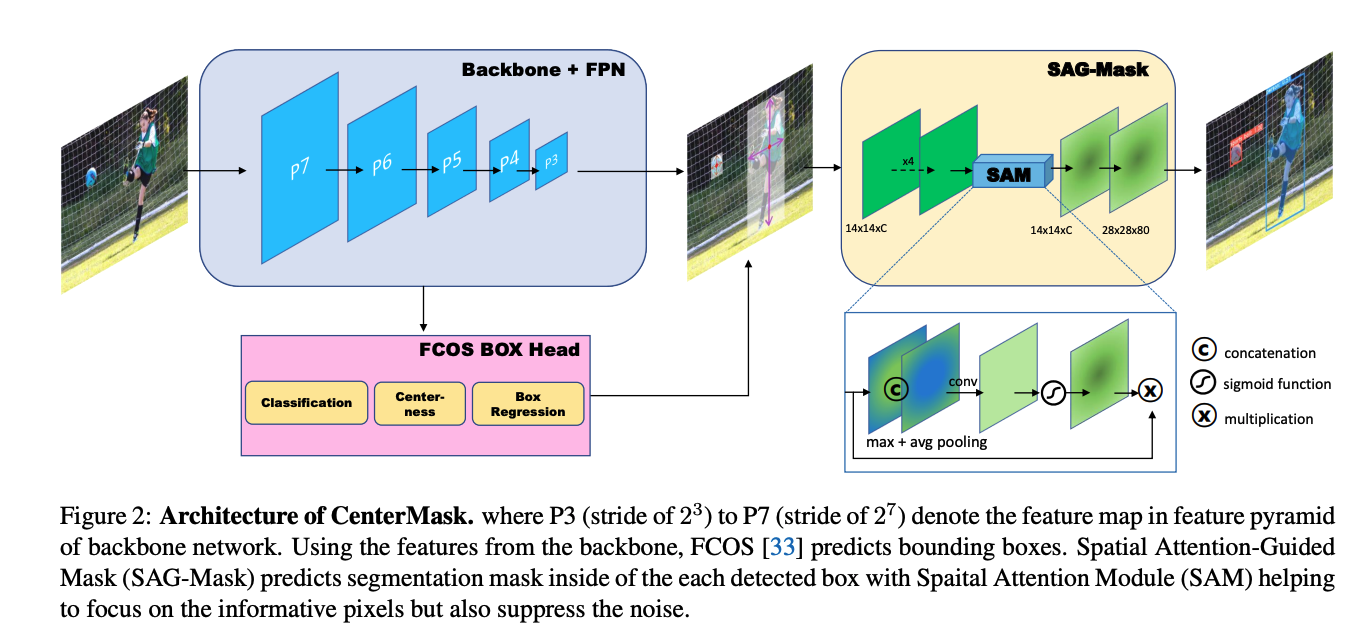
위의 그림처럼 CenterMask는 FCOS object detector에 끼워지면서, Spatial attention guided mask(SAG-Mask)가 FCOS로 부터 predict된 box들로 각각릐 ROI에 segmentation mask를 추측해냅니다. SAG-Mask의 SAG Module이 mask branch를 도와 유의미한 pixel들에 집중하게 하고, 필요없는 픽셀들을 최소화하죠. (더 깔끔하게 segmentation한다는 의미입니다.)
SAG-Mask 방법 이외에도, scale-Adaptive ROI assignment function, VoVNet V2, eSE Module로 성능을 극대화하여 기존 모델들과 YOLACT를 속도와 정확도면에서 뛰어 넘습니다.
CenterMask
FCOS
FCOS는 FCN과 같은 픽셀마다 prediction하는 anchor-free & proposal-free 의 object detection입니다. Faster R-CNN, YOLO, RetinaNet과 같은 대부분의 object detector들은 pre-defined anchor box를 필요로 하고, 그러려면 파라미터 튜닝과 IoU계산등 복잡해지는 경우가 많습니다. 그와 달리 FCOS는 anchor-box 없이 바로 한 레벨의 feature map들에서 각 spatial 위치에서 4D vector와 class label을 예측합니다. 추가로, center를 찾고 bounding box 정보를 찾는 방식이 성능을 많이 올려줬습니다.(CenterNet방식)
Architecture
(Figure 1 참고)
1. backbone for feature extraction
2. FCOS detection head
3. Mask head
Adaptive RoI Assignment Function
FCOS에서 object proposal을 해주면 다음은 segmenatation mask를 찾아줘야합니다. RoI들이 FPN에서 각각 다른 레벨의 feature map에서 나온 것들이 때문에, feature들을 뽑아주는 RoI Align은 RoI scale에 따라 feature map들의 각각 다른 scale로 지정해줘야합니다. Mask R-CNN을 기반으로 한 two-stage detector는 FPN에서 다음과 같은 식으로 어떤 feature map 가 지정될 것인지 결정됩니다.
그러나, 저자는 이 식이 두가지 이유에서 CenterMask에는 적합하지 못하다고 명시했습니다.
첫번째, 위의 식은 two-stage detector에만 적합하고, one-stage에는 그렇지 못합니다. 특히, two-stage에서는 P2(stride of )부터 P5()의 feature level을 사용하지만, one-stage detector들은 작은 resolution의 더 큰 receptive field인 P3()부터 P7()을 사용하기 때문입니다. 게다가, 224로 학습된 정식 ImageNet은 위의 식을 hard-coding하였고 다양한 feature scale에 맞추지 못합니다. 예를 들어, input이 고 RoI 영역이 라면, RoI는 작은 영역에도 불구하고 input 차원에 맞춰 상대적으로 큰 feature인 P4에 해당하게 됩니다. 그럼 작은 물체에 대한 AP가 떨어질 수 밖에 없죠. 따라서! 저자들은 CenterMask기반의 one-stage detector에 맞는 새로운 RoI assignment function을 도입합니다.
위의 식에서 는 backbone feature map의 마지막 레벨(7)이고, 과 는 각각 input image와 RoI의 영역(Area)입니다. 이 공식은 input과 RoI에 따른 RoI pooling scale이 정해지죠. 그럼 첫번째식이 이였다면, 두번째 식에서는 로 input size보다 20배 작게 되어서 RoI의 최소 feature level에 대한 영역이 되는 것 입니다. 즉, 기존보다 작은 물체를 찾는데 개선될 수 있다는 점이 생기죠.

Spatial Attention-Guided Mask
Attention method는 중요한 feature에 더 집중하고, 그렇지 않은 것에는 덜 집중할 수 있도록 해주는 방법으로 익히 다른 데에서도 많이 사용하고 있습니다. 특히, channel attention은 feture map channel중에서 어떤 것에 집중할지를 강조하고, spatial attention은 중요한 정보가 있는 region이 어디인지에 집중합니다. 저자들은 의미있는 픽셀에 집중하고 그렇지 않은 부분에는 줄이려고 spatial attention을 사용합니다.
Figure 2에서 나온 과정처럼, 추론된 RoI안에 feature가 RoI Align으로 추출되면, 이 feture들은 차례로 conv layer와 spatial attention Module (SAM)에 들어가게 됩니다. input feature에 대해 spatial Attention map 을 사용하기 위해서, SAM은 먼저 channel axis에 따라 각각 max pooling과 avg pooling된 feature 를 만들고, concatenate합니다. 그리고 conv와 sigmoid를 거칩니다.
그런 후, attention guided feature map 아래 식 처럼 element-wise multiplication으로 만들어집니다. 그리고 deconv upsampling으로 resolution을 만들어, 마지막으로 conv를 통해 class-specific mask가 나오게 됩니다.

VoVNetV2 backbone
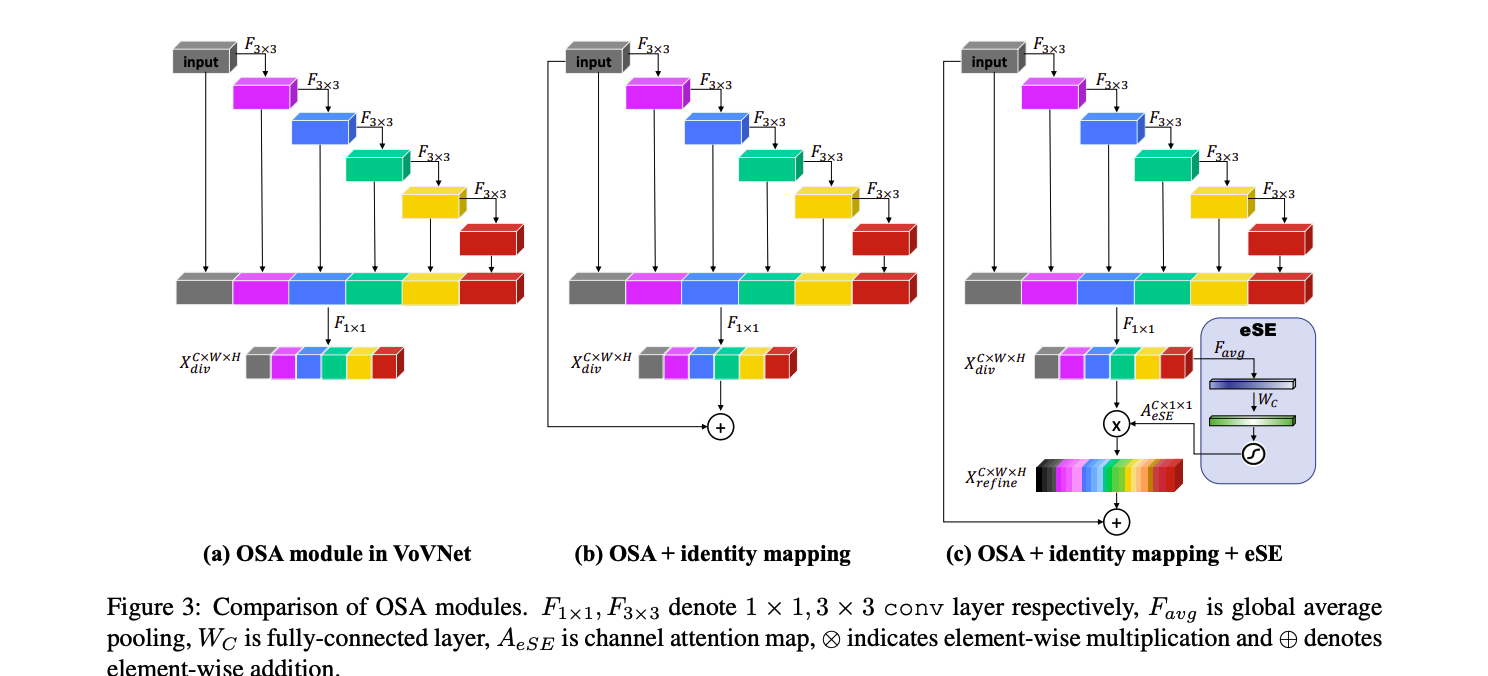
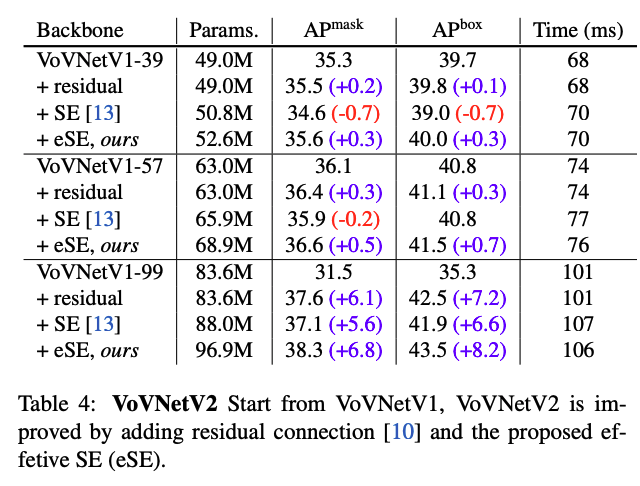
VoVNet V2는 VoVNet에 residual connection과 effective Squeeze_and_Excitation attention module을 추가해 성능 개선을 이뤘습니다.
residual connection
모델이 깊어질 수 록, OSA module이 정확도가 감소하게 되는 현상을 보입니다. 저자들은 이 문제를 OSA Module이 쌓이면서 conv같은 transformation이 많아져 gradient backpropagation이 어려워진 것이라고 추측했습니다. 따라서, Figure 3(b)처럼, identity mapping을 추가하여서 큰 모델에서도 성능 개선이 잘 될 수 있도록 하였습니다.
Effective Squeeze-Excitation (eSE)
SE Module은,대표적인 channel attention method로, global average pooling으로 spatial dependency를 squeeze하여 spatial chennel descriptor를 학습할 수 있게하고, 두개의 FC layer와 sigmoid는 유의미한 chaanel만 강조할 수 있도록, input feature map을 rescale합니다. 식으로 정리하면 아래와 같습니다.
위 식에서, 로 chnnel-wise pooling을 뜻하고, 와 는 FC layer의 가중치를 의미하여, 는 ReLU, 는 sigmoid를 뜻합니다.
하지만, 일반 SE는 dimension reduction으로 channel information을 잃는 단점이 있습니다. 모델의 높은 복잡도를 피하디 위해서, 첫번째 FC는 channel을 C에서 C/r로, 두번째 FC는 원래 channel C로 확장시키는데, 이 과정에서 channel information이 손실되게 됩니다.
따라서, 저자들이 제안한 eSE는 C channel의 FC layer를 한개만 사용해서 channel information을 유지하고 성능을 개선합니다.
위 식에서, 는 OSA Module에서 으로 계산된 다양해진 feature map입니다. channel attentive feature descriptor로서, 은 diversified feature를 더 informative하도록 를 적용합니다. 마지막으로, residual connection을 이용할때, input feature map은 을 element-wise하게 더해줍니다. (Figure 3(c)참고)
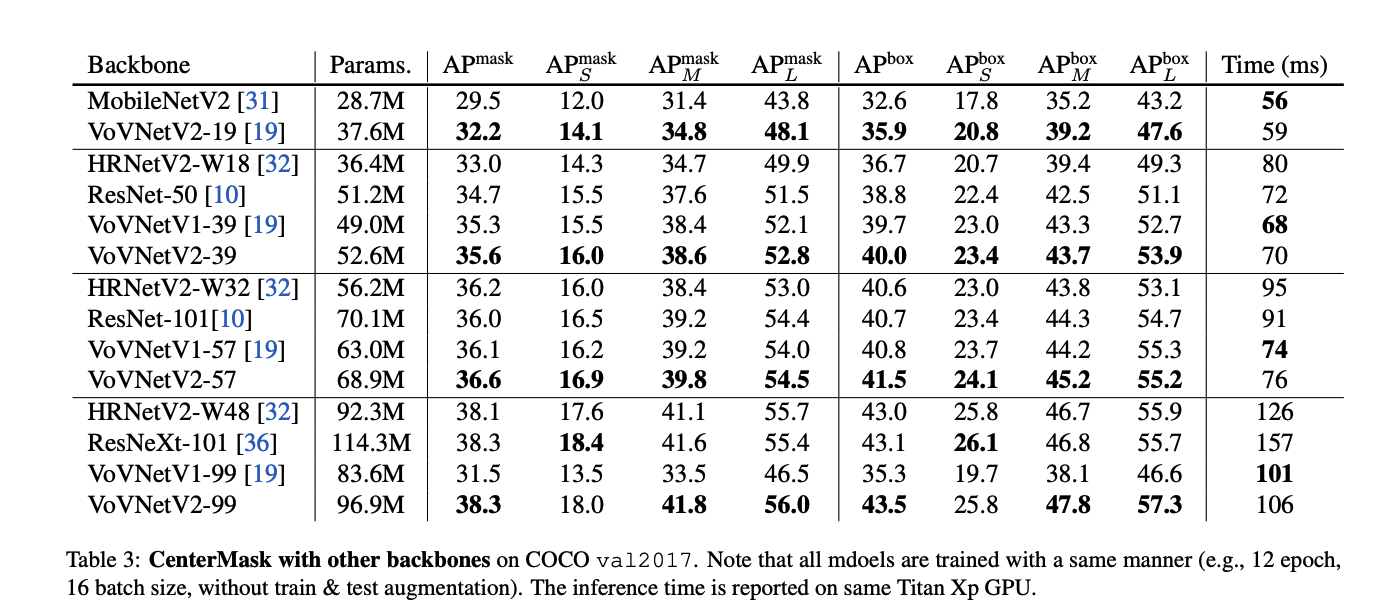
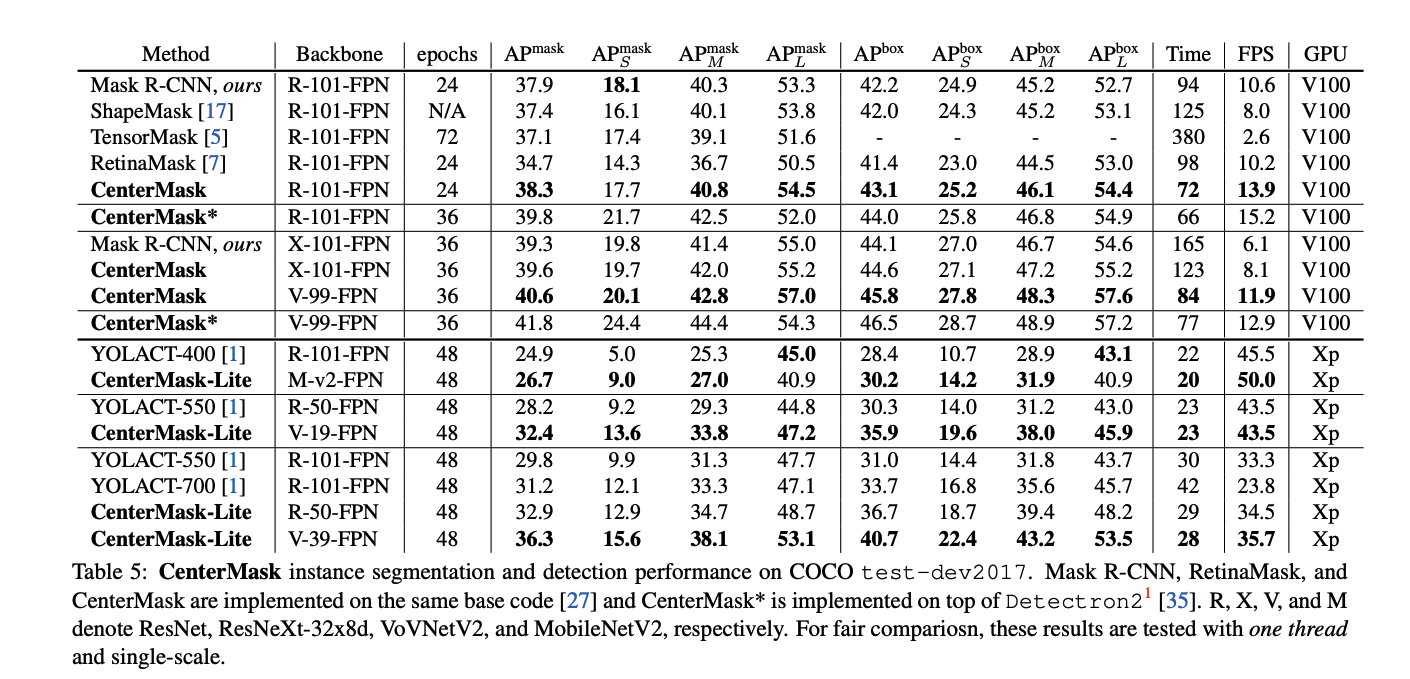
performance