[논문] An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Backbone
요즘 관심이 생기는 분야 성능이 보장된 빠른 Inference 속도와, CPU와 GPU에서 최적화된 backbone들입니다. 왜냐하면, 딥러닝 모델을 서비스로 출시할때는 적용될 모델이 어느환경에서 빠르게 잘되는지가 중요하기 때문입니다. CPU환경에서 돌릴것인데 GPU에서 최적화된 모델을 마냥 학습해놓으면 그것만큼 시간 아까운게 없지 않습니까 😇
오늘 리뷰할 논문은 ETRI(한국전자통신연구원)의 연구원분들이 연구하신 내용이며 CVPR2019에 등재되었습니다.
OSA Module을 도입하셨는데, 내용이 아주 논리적이고 베이스가 탄탄합니다. 근래에 읽은 논문들은 대부분이 "우리 것이 좋다"를 증명하는 과정이 다소 공감적이지 못한 부분들이 있거나 또는 베이스가 부족한 느낌이 약간 있었는데, 이 논문은 속 시원하게 읽혔습니다. 🤩
그리고 내용도 거창하지 않고 방법도 너무 간단한데, 개선 효과까지 좋다니...
그리고, CVPR 2020에 등재된 VoVNet v2도 있더라구요.(TODO+1)
그럼 리뷰를 시작하겠습니다.
https://arxiv.org/pdf/1904.09730.pdf
https://github.com/youngwanLEE/VoVNet-RefineDet
Abstract
DesnseNet은 feature들을 dense connection으로 합쳐, intermediate feature들을 유지함으로 object detection에서 높은 성능을 보여줬습니다. 하지만 적은 모델 파라미터로 feature를 유의미하게 만들었다는 장점에 비해 느린 속도와 낮은 에너지 효율성이 아쉬운 점이였죠. 또한 저자들은 input channel이 늘어날 수 록, dense connection이 높은 memory cost로 computation overheaddhk 높은 에너지 소비를 발생시킨다는 것을 찾아냈습니다. 그래서 그보다 2배 빠르고, 에너지도 1.6-4.1배 적게 소모하는 One-Shot Aggregation (OSA)로 만들어진 VoVNet을 만들게 됩니다. 또한 small object detection부분에서 DenseNet과 ResNet의 성능도 뛰어넘습니다.
Introduction
우선, DenseNet을 살펴봅니다.
ResNet과 비교해보면,
- ResNet: shallower부터 feature들을 summation
- DenseNet: feature들을 concatenation
- summation하면 초기 feature들이 갈수록 사라짐(washed out)
그렇지만, 단점도 생깁니다.
적은 FLOPs와 작은 모델 사이즈임에도 다른 요소들 때문에 ResNet보다 많은 에너지와 시간을 소모하게 됩니다.
- intermediate feature들 때문에 MAC(memory access cost)에 accessing memory가 훨씬 더 필요
- GPU 병렬 연산관점에서 연산 병목의 한계가 존재
- input dimension과 FLOPs를 줄이기 위해 생긴 conv가 병목
저자들은 위의 두 관점에서 concatenative agrreagating의 장점을 살리면서 더 효율적인 개선을 목표로 삼습니다. 그리고, 메인 아이디어는 OSA입니다.
- input dimension과 FLOPs를 줄이기 위해 생긴 conv가 병목
Factors of Efficient Network Design
efficeint neteork(MobileNets, ShuffleNets, Pelee)는 주로 depthwise와 conv 병목 구조로 FLOPs와 모델 사이즈를 줄입니다. 그러나 그런 방법들이 GPU inference time과 실제 에너지 소모까지 줄여주진 못합니다. Shufflenet V2는 MobileNet V2와 비슷한 FLOPs를 가지지만 GPU에서 더 빠릅니다. 그리고, SqueezeNet은 AlexNet보다 50배적은 파라미터지만 더 많은 에너지를 소모하죠. 이런 부분들을 보면 FLOPs와 파라미터가 실용성과 완전 직결되는 지표가 아니라고 볼 수 있죠.
Memory Access Cost
CNN에서 에너지를 더 많이 소모하는 것은 연산보다 memory access입니다. 특히, 연산을 위해 DRAM에서 memory에 접근하는 것은 연산 자체보다 더 많은 에너지를 소모합니다. 게다가, 메모리에 접근하는 것은 time budget에 많은 부분을 차지하고, GPU process에 병목이 될 수 있습니다. 즉, 같은 수의 연산이라도 메모리에 접근이 다르면 에너지 소비도 다르다는 거죠.
모델사이즈가 메모리 접근 횟수와 다른 이유는 intermediate activation meomory footprint 때문인데요. 참조 논문(A spatial architecture for energy-efficient dataflow for convolutional neural networks)에 따르면, intermediate activation meomory는 필터 파라미터와 intermediate feature map과 상관이 있습니다. intermediate feature map이 크면, 메모리 접근량이 많아집니다.
conv의 MAC을 계산하는 방법은 다음과 같습니다.
GPU-Computation Efficiency
속도를 위해서 FLOPs를 줄이는 것은 모든 floating point 연산이 한 디바이스에서 같은 속도로 진행된다는 가정에 따른 것인데요. GPU에서는 병렬 프로세스 메커니즘때문에 다릅니다.
GPU 병렬 연산 능력은 계산되는 데이터 텐서가 클수록 더 좋습니다. 큰 conv 연산을 작은 연산들로 나누는 것은 병렬 연산 수가 줄기 때문에 비효율적입니다. 즉, 같은 연산이 이루어지는 거라면, 적은 레이어로 구성된 네트워크가 더 좋다는 뜻이고, 더 나아가, 다른 레이어들이 추가되는 것은 kernel launching과 synchronization때문에 time-overhead를 발생시킬 수 있다는 의미입니다.
그래서 conv가 추가되는 것은 GPU 연산에는 치명적인거죠. 따라서 모델 구조의 효율성을 검증하기 위해서는 FLOPs를 실제 GPU inference time로 나눈 FLOP/s(Flops per Second)가 필요합니다. (높을 수 록 좋음!)
Proposed Method
Rethinking Dense Connection
DenseNet은 레이어를 지날 수 록, 각 레이어의 input channel 수가 선형적으로 증가하기 째문에 비효율성은 당연할 수 밖에 없습니다. aggregation 때문에 dense block은 제한된 FLOPs와 파라미터를 가진 적은 feature를 만드는데, 이는 양보다 질을 선택한 방법이죠. 그러나, 질을 선택하면서 생기는 에너지와 시간이 대가로 따르게 되는겁니다.
첫째로, dense connection은 에너지와 시간을 소모하는 MAC을 가지게 됩니다. conv layer의 작은 MAC boundary나 memory access operation은 연산량 가 일때, 로 표현할 수 있습니다. 이런 부등식의 최소값에 맞추려면 같은 channel 수, 고정된 연산량 또는 같은 모델사이즈가 필요함을 식에서 알 수 있죠. dense connection은 output channel을 고정시키고 input size를 증가시키기 때문에, input과 output의 channel의 밸런스가 맞지 않습니다. 따라서 MAC이 아주 클 수 밖에 없습니다.
두번째로, input size가 커질 수 록, 총 연산량은 depth에 제곱으로 커지고, 모델 사이즈가 커지면 아주 치명적이기 때문에, conv를 넣는 bottleneck 구조가 있습니다. 이 방법은 FLOPs와 파라미터를 줄여주지만, GPU 병렬 구조에서는 그렇지 못하죠. 좀 더 자세히 보자면, conv bottleck은 두개의 작은 레이어로 나뉘고 더 많은 연속적인 연산이 되어 더 많은 inference시간을 요구하게 되는 겁니다.
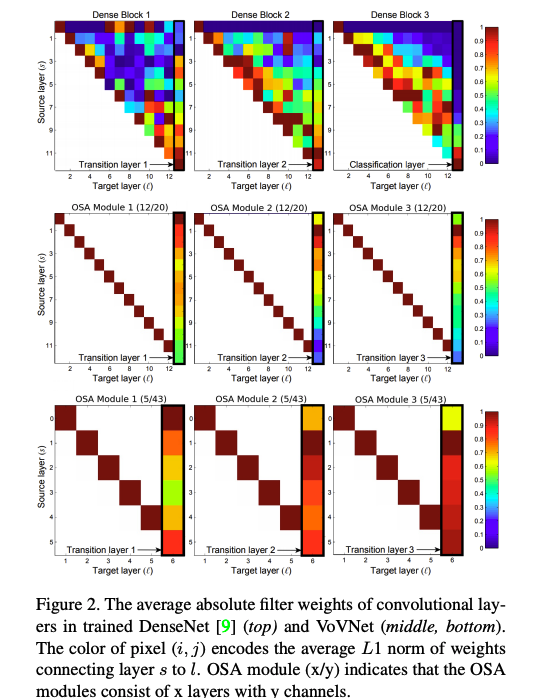
위의 그림중 가장 윈 단은 denseNet의 각 레이어의 input weights를 L1 norm을 적용하여 가시화한 것입니다. Dense Block 3을 보면, 대각선의 빨간 박스들은 intermediate layer에서 aggregation이 활성화된 것을 의미합니다. 그런데, classaification layer를 보면 intermediate feature의 아주 적은 부분들만 사용되는 것도 볼 수 있죠. 반대로 Dense Block 1의 transition layer가 대부분의 input feature들을 잘 합쳐주지만 intermediate layer는 그렇지 못합니다.
이런 관찰로, 저자들은 aggregation의 강도가 중간 레이어와 마지막 레이어와는 반대 관계를 가짐을 알 수 있었다고 합니다. 즉, 중간 레이어들 사이에서의 dense connection은 각 레이어들의 feature들의 상관관계가 있다는 것을 의미합니다. 다시한번 정리해자면, dense connection은 이후의 중간 레이어들이 더 좋은 feature들을 만들 뿐만 아니라, 이전 레이저와 비슷한 feature를 만들어 내는 거죠. 이런 경우, 마지막 레이어는 redundant 정보를 만드는 것이기 때문에, 이런 피쳐 둘다 합할 필요는 없는것입니다. 결과적으로, 이전 중간 레이어가 마지막까지 영향을 주는 정도가 아주 작은 겁니다.
그래서, 저자들은 중간 feature들이 서로 도움이 되면서, 비슷하지 않게 하여, cost 측면에서 효율적인 신경망을 만들고자 합니다.
One-Shot Aggregation
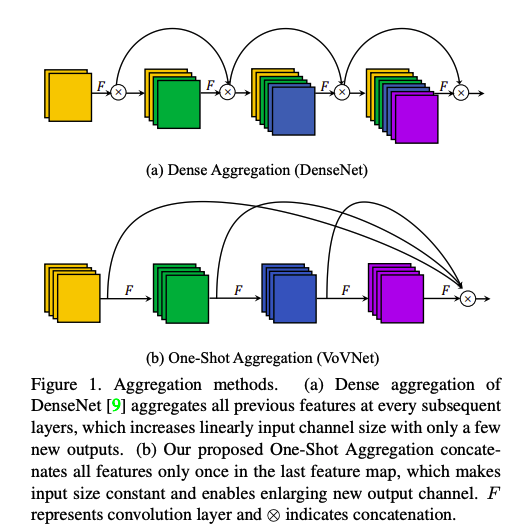
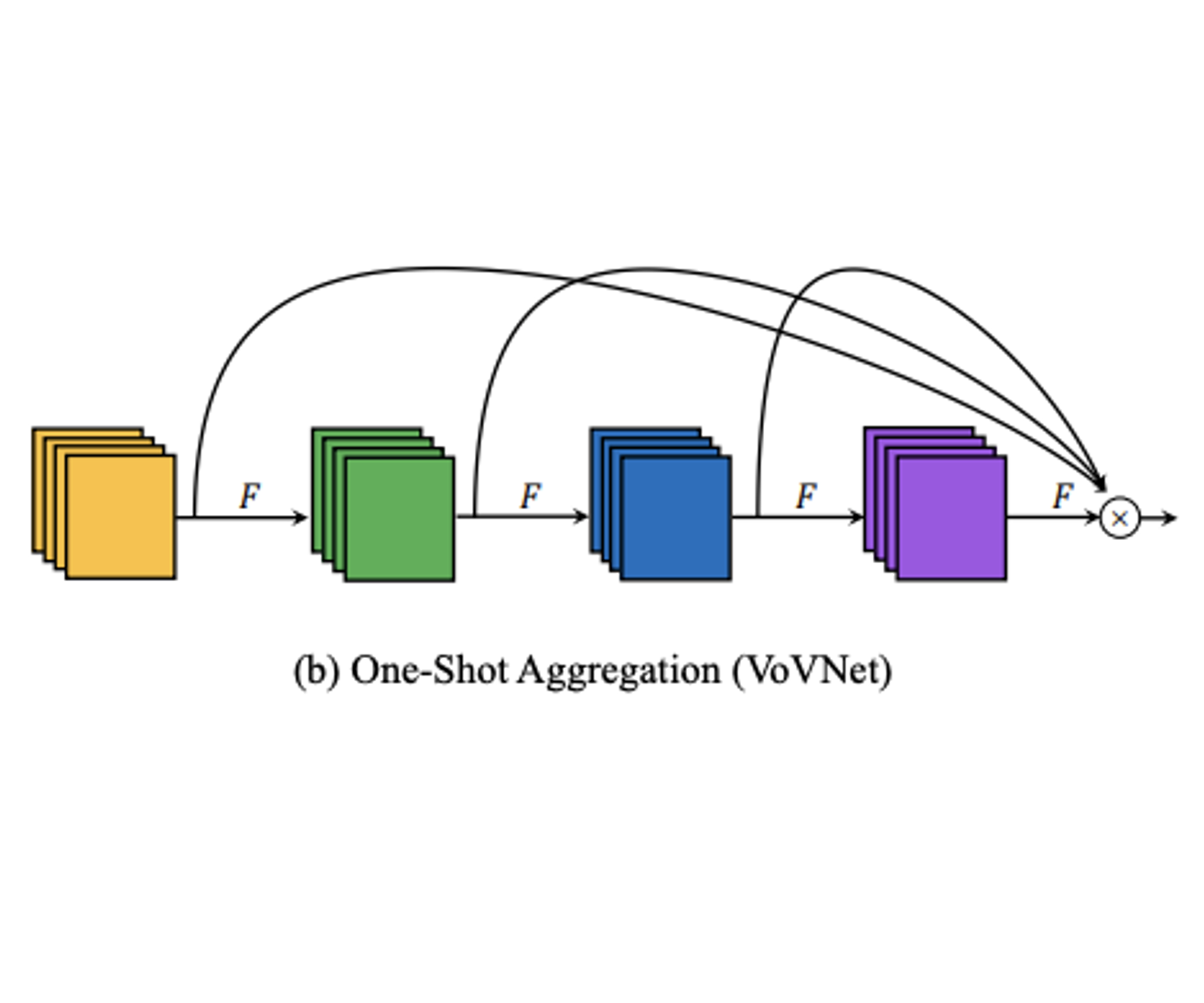
위에 열심히 지적한 점들을 보완하기 위해서, 저자들은 One-Shot Aggregation을 도입하였습니다. One-shot Aggregation의 방법은 Figure 1 (b)에서 그림으로 확실하게 볼 수 있습니다.
저자들의 실험에 따르면, 우선 Dense block에 맞춰서 12 layer를 OSA 구조로 구성한 경우 (Figure 2, middle), CIFAR-10 classification에서 DenseNet보다 1.2%낮지만 ResNet보단 작은 모델로 높은 93.6%의 성능을 보였습니다. 적어도, OSA가 효과가 있다는 거죠. 그리고, 윗 section에서 애기한 dense connection과 달리, 다른 패터들을 보여주고 있어 shallow depth들이 더 잘 합쳐지고 있는 것을 알 수 있습니다.
deep layer의 feature들이 transition layer에 영향을 적게 주기 때문에 layer를 줄여도 상관없다는 의미가 확실해지면서, 저자들은 layer를 43개의 채널을 가진 5개 layer로 줄이고, 실험해봤습니다. 놀랍게도!! DenseNet-40(5.24%)과 비슷한 error rate 5.44%을 보였습니다. 이 실험은 dense connection의 deep한 중간 레이어가 기대보단 별 효과가 없다는 의미를 주는 것이였습니다.
이 실험이 의미 있는 것은 성능 하락이 매우 작은데도 두번째 실험에서 MAC이 2.7M까지 줄었다 입니다.(DenseNet-40 MAC = 3.7M)
결론 적으로, dense connection보다 OSA가 GPU 연산에서 훨씬 좋고, 추가적인 도 필요 없을 뿐만 아니라, OSA가 더 적은 레이어로 shallow feature까지 커버한다는 의미입니다.
Configuration of VoVNet
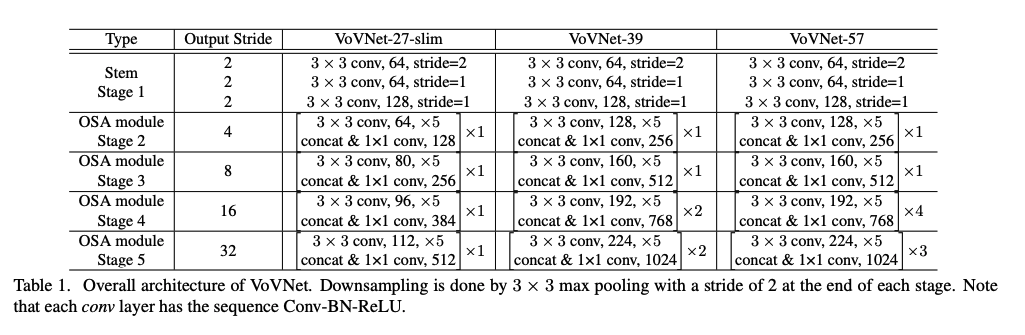
위에서 설명한 OSA Module을 활용하여 만든 신경망이 VoVNet입니다.
- lightweight: VoVNet-27-sli
- stem: a block of 3 conv layers
- body: 4 OSA stage (output stride 32)
- OSA Module: 5 conv layer(같은 input, output channel size)
- stage를 지날때마다 map pooling(stride 2)로 downsampling
- large scale: VoVNet-39/57
Experiments
Experimental setup
DSOD
VoVNet을 적용한 DSOD를 다른 모델들과 VOC2007+2012에서 비교한 결과 입니다. 심지어 MobileNet보다 10배 빠릅니다.
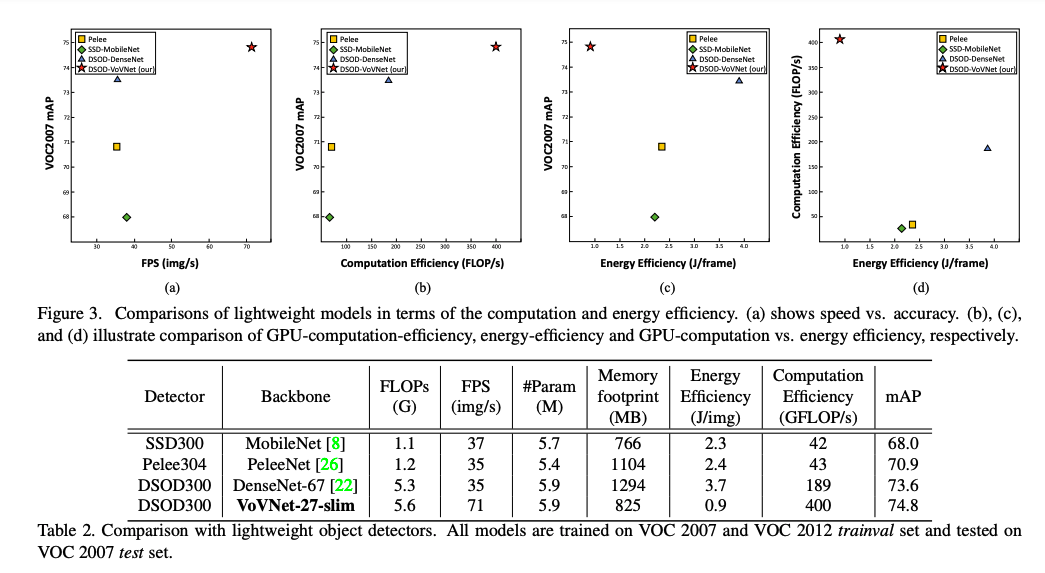
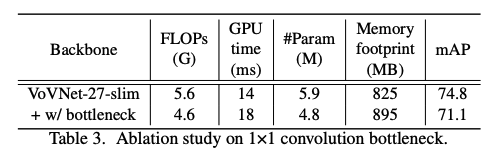
아래는 병목이 GPU에선 느려질 뿐만 아니라, VovNet에서는 성능하락까지 발생시킨다는 자료입니다.
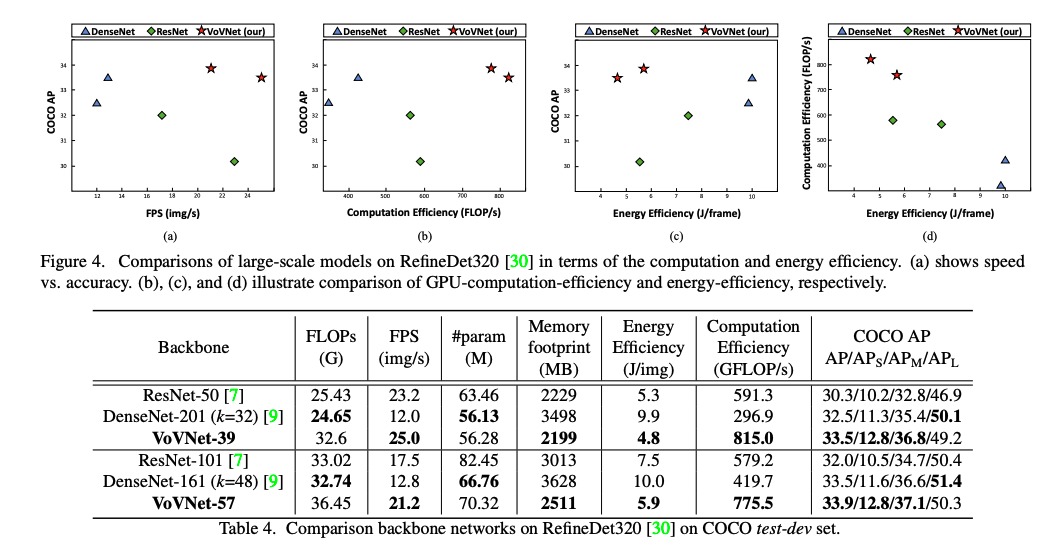
RefineDet
one stage object detectior에 적용한 large scale VovNet 결과 입니다.
Mask R-CNN from scratch

