VanillaNet을 시작으로 GhostNet에 관심을 갖게 되었습니다. 읽다보니 세번째 GhostNet 논문까지 왔습니다. 사실 이번 논문은 CVPR 2020 GhostNet의 확장판입니다. 타이틀에서 볼 수 있듯이 Device에 초점을 둔 것인데요! ML 엔지니어로 일을 하다보니, 요즘 트렌드는 모델 자체를 개발하는 것보다는 모델을 잘 활용할 줄 아는 것에 더 초점을 두는 것 같습니다. 특히, ML 모델을 서비스에 제공하려면 최악의 조건에서도 빠른 속도로 inference를 하는 것이 아주 중요합니다. 물론 후처리 부분에서 가속화 및 최적화를 하는 것도 좋겠지만, 모델 자체가 빠른 것도 큰 이점이 되겠죠. 그 부분에 있어서 이 논문은 도움이 된다고 생각해서 리뷰하게 되었습니다.
https://arxiv.org/pdf/2201.03297.pdf
https://github.com/huawei-noah/Efficient-AI-Backbones
일단 앞 부부은 GhostNet의 Module에 대해서 이야기합니다. 이부분은 지난 리뷰들에서 다루었기 때문에 스킵하겠습니다.
CPU-Efficient GhostNet
Building Lightweight C-Ghost
우선, 이부분은 GhostNet V1에서 제안한 방법과 동일합니다. 제 추측이지만, GhostNet을 GPU에서 돌려봤을때, 가속되는 비율이 이상적이지 않아 분석을 하면서 GhostNet 확장판을 만든 것 같습니다.
하지만, 이 부분은 GPU 버전과 비교하는데 큰 틀이 되기 때문에 리마인드 해보겠습니다.
C-Ghost Bottlenecks

C-Ghost Bottleneck은 ResNet에서 제안한 residual block과 비슷하게, 여러 conv layer들이 shortcut과 통합됩니다. 저자가 제안한 방법은 두개의 Ghost Module을 쌓았습니다. 첫번째 Module은 expansion layer로 channel수를 증가시킵니다. 그리고, 두번째 Module은 shortcut path에 맞게 channel 수를 줄입니다. 그리고 MobileNet V2 처럼, shortcut은 input과 이 두 모듈의 output으로 연결되죠.
추가로, 각 레이어에는 Batch Normalization과 ReLU가 붙습니다.(두번째에는 ReLU가 안 붙습니다.) 위에서 말하는 C-GhostNet은 stride=1이고, stride가 2인 곳에서는, shortcut path가 downsampling layer로 실행되고, stride=2인 depth-wise conv가 2개의 C-GhostNet module사이에 낍니다. 실제로 C-Ghost Module 앞 부분의 conv은 효율성을 위해 pointwise를 사용합니다.
C-GhostNet
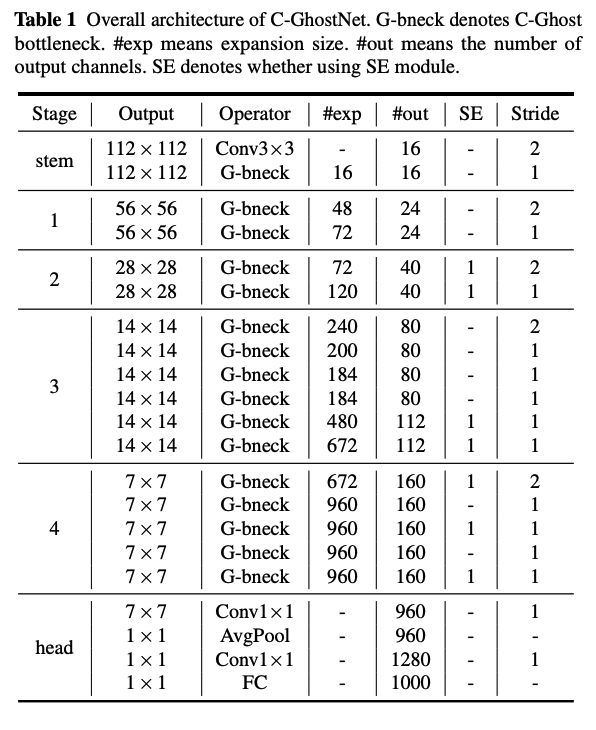
위의 표에서 보이시다시피, 완성된 C-GhostNet은 MobileNet V3 구조를 따랐음을 알 수 있습니다.
첫번째 layer에는 16 필터의 conv가 있고, 그 뒤를 C-Ghost bottleneck들이 각각 input feature map의 사이즈에 따라 다른 stage들로 묶여있습니다. 그리고, 그 stage들의 첫번째 G-bneck에만 stride가 2고, 나머지는 다 1입니다. 마지막은 global pooling과 하나의 conv layer가 feature map을 1280 차원의 feature vector로 마지막 classification을 위해 변환해줍니다. 추가로, 중간 중간의 squeeze와 excite(SE)가 residual block에 적용되었습니다.
MobileNet V3와 비교했을때, 다른 점은 latency가 큰 hard-swish를 사용하지 않았음을 알 수 있습니다.
GPU-Efficient GhostNet
여기서부터가 이 논문의 메인이라고 봐도 좋습니다.
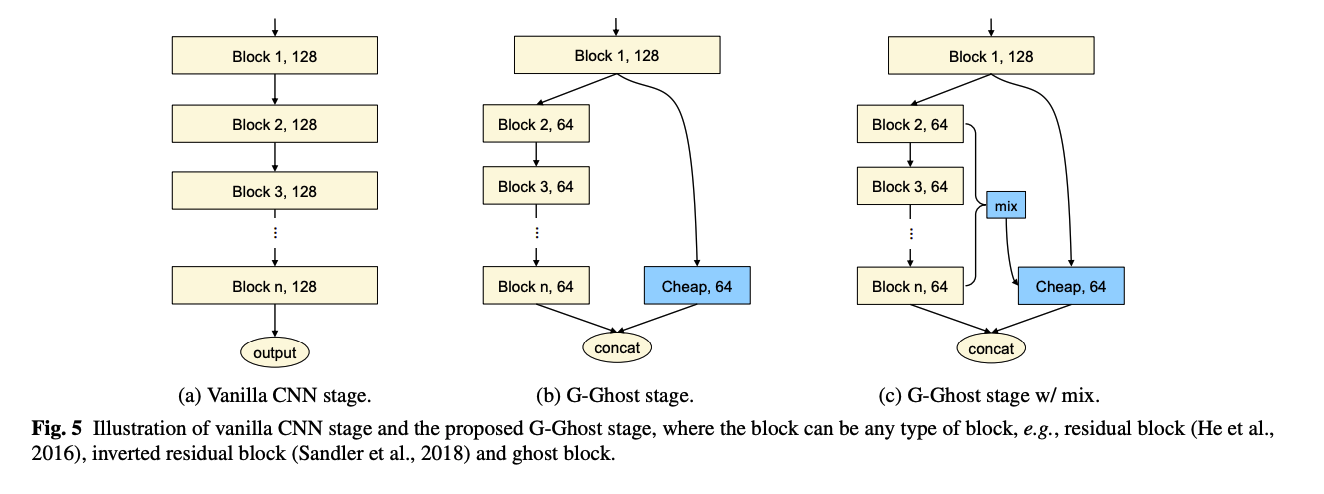
G-Ghost Stage
비록, C-GhostNet이 높은 성능을 유지하며 FLOPs를 줄였지만, 그 역할을 하는데 공헌한 cheap operation이 GPU에서는 또 그렇게 cheap하지 못했다고 합니다. 특히, depthwise conv가 memory operation을 연산하는 비율인 arithmetic intesity(산술 강도, 총 상술 연산 수 / 총 메모리 접근 수)가 낮은데, 이는 병렬 연산 능력을 충분히 사용할 수 없습니다
FLOPs와 파라미터 수 이외에, Radosavovic이 도입한 모든 conv layer의 output tensor 사이즈로 표현하여 network의 complexity를 표현하는 activations라는 것도 있습니다. activations은 FLOPs보다 더 GPU에서의 latency와 연관이 있습니다. 즉, 우리가 feature map의 일부를 없애서 activations을 줄이면, GPU에서의 latency를 낮출 수 있을 확률이 높다는 의미입니다.
저자는 CNN의 main body에는 resolution을 줄여주는 여러 점진적 stage를 줄이는 방법 보다는, stage-wise redundancy를 줄여서 중간 feature들을 줄여 연관된 연산량과 메모리 사용을 줄입니다.
보통 CNN들은 (stem, body, head)로 이루어져있는데, stem과 head은 대부분은 lightweight이고, 연산량과 파라미터들은 모두 body에 뭉쳐있죠. 따라서, 건드려야할 부분은 body이기 때문에, 저자들은 body를 타겟으로 잡습니다. n개의 레이어 또는 block을 이라 하고, input feature를 X라고 하면, 각각의 output 는 다음과 같이 표현할 수 있죠.
을 얻기 위해서는 연속된 block들을 통과하면서 합쳐지고, 이 과정에서 연산적인 cost가 많이 필요합니다.
저자는 여기서 마지막 block의 모든 feature 을 얻기 위해서 이렇게 많은 block들까지 필요없을 것이라고 생각했습니다. 그 이유로는, 아래 그림처럼, ResNet 첫번째 layer에서의 feature map이나 세번째 stage의 마지막 레이어에서의 feature map이 그닥 차이가 없다고 본 것입니다. 그래서 차라리 간단한 변환으로 대체할 수 있을 것이라고 여겼습니다.
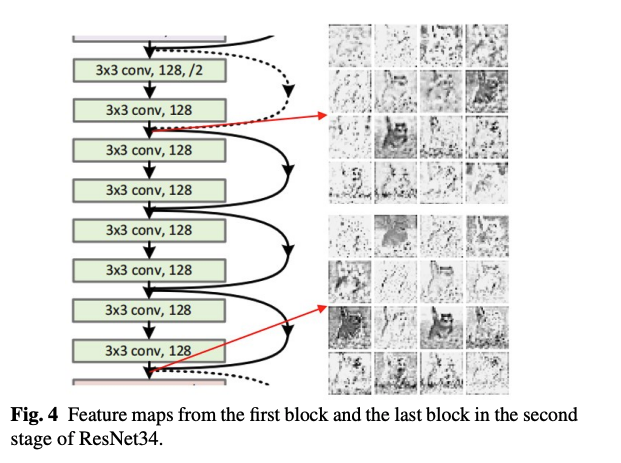
저자들은 위와 같은 이슈로, 복잡한 부분과 ghost 부분으로 deep feature를 나눠 일부에서는 그대로 complicated conv연산 ()을 하고 다른 부분을 cheap operationd으로 이루어진 ghost layer() 대체하여 둘을 conca합니다.
식으로 표현을 해보자면, 아래와 같습니다.
- 는 ghost feature의 비율, block 은
위에서의 C는 conv가 될 수 있습니다.
그리고 G-Ghost에서는 를 사용합니다.
Intrinsic Feature Aggregation
윗 부분에서 설명된 것은 첫 블록과 마지막 블록의 사이의 redundancy를 이용하는 것으로, 기본 CNN보다 연산량을 대폭 줄였습니다만, deep information이 cheap operation때문에 줄었을 것은 당연합니다. 그래서 이러한 부족한 정보들을 채워주기 위해서, complicated path의 중간(intermediate) feature들을 이용하는 방법을 제안합니다.
이들이 제안한 것은, complicated path에서의 중간 feature (를 channel의 수 총합)를 tranformation 로 도메인을 맞춰 cheap operation에 보충하는 방법입니다. 식으로 표현하면 아래와 같죠.
이때, 연산량을 많이 늘리지 않도록 transformation은 간단해야하는데, 저자는 global pooling을 사용하여 합쳐진 feature 를 적용했습니다.
이렇게 적용하는 방법을 해당 논문에서는 mix라고 표현하고, 아래 그림과 같습니다.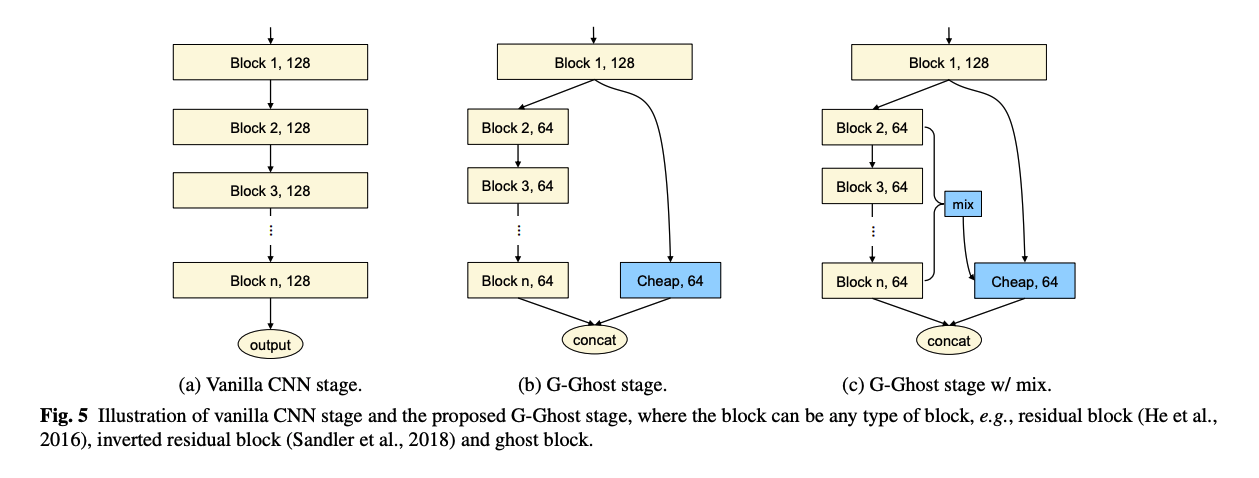
Complexity Analysis
이렇게 G-Ghost Stage로 업그레이드 해주면, 연산량과 메모리량이 더 줍니다. 감소 비율은 원래 stage 구조, ghost ratio, chaep operation과 mix operation이랑 연관이 있습니다. 한 stage에 n block이 있다고 할때, i번째 블록의 FLOP를 , 파라미터 수를 라고 가정해봅니다. 그럼 G-Ghost stage는 n개의 블록에서의 FLOPs를 이 됩니다. 그리고 추가된 cheap operation은 FLOPs와 개의 파라미터를 가집니다. 그랬을때, FLOPs와 파라미터의 감소 비율은 아래와 같이 정리할 수 있습니다.
이 3보다 커지면, G-Ghost stage가 더 이득임을 알 수 있고, 가 클수록 감소비율이 더 커질 수 있지만, 너무 크면 신경망의 표현능력이 줄게 되죠.
Building Lightweight G-GhostNet
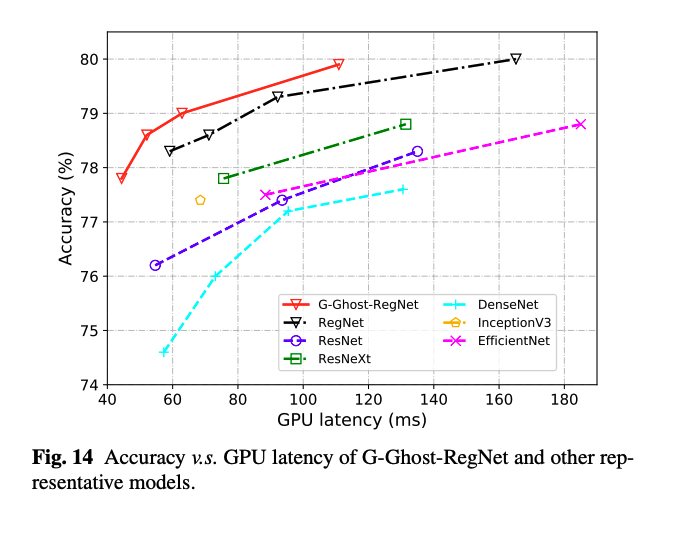
G-GhostNet은 일반 CNN의 일반 stage를 Ghost stage 변경했지만, 정확도와 GPU latency의 trade off 관계를 맞딱뜨렸습니다.
그래서 추가 된것이 depth-wise conv를 대체할 수 있는 mix operation이였습니다.
이런 operation이 추가된 G-GhostNet은 아래 그림처럼 C-GhostNet를 토대로 만들어졌습니다. conv를 cheap operation으로 사용했고 ghost ratio , expansion ratio를 3으로 설정했으며, SE module을 사용했다고 합니다.

C-GhostNet은 MobileNet V3를 기반으로 만들었다고 나와있고 실제로 모델도 MobileNet V3를 기반으로 만들었음을 알 수 있습니다. 그와 달리 G-GhostNet은 MobileNet V3의 형태와는 약간 다름을 확인할 수 있습니다.
https://github.com/huawei-noah/Efficient-AI-Backbones/issues/4
그 이유는 위의 이슈 글에서 확인하실 수 있습니다. 하드웨어에 최적화를 하면서 많은 변화들이 있었고, input 사이즈가 커질 수 록 latency가 늘어나서 이렇게 만들게 되었다고 해요.
그리고, 또 당황스러운 점은 실험과 변경을 하면서 RegNet 베이스로 바뀝니다. 이 부분은 뒤에서 나옵니다. 그럼 솔직히 이 논문을 읽는 사람 입장으로는 저자가 처음부터 RegNet 베이스라고 해주거나 아니면 이 내용을 충분히 알려줬어야하지 않나...싶습니다.😓
input사이즈는 작아졌지만 그래도 성능이 보장된다는 점을 보여주고 싶으셨던거 같습니다.
Experiments
Datasets and Experimental Settings
- datasets: CIFAR-10, ImageNet ILSVRC 2012, MSCOCO
- task: image classification, Object Detection
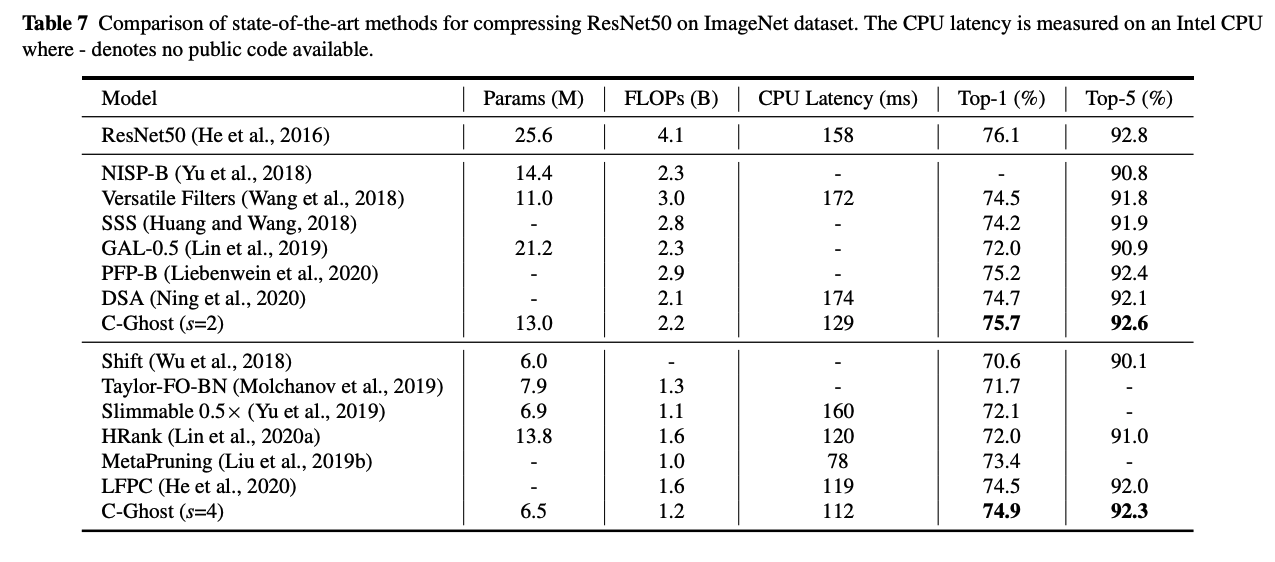
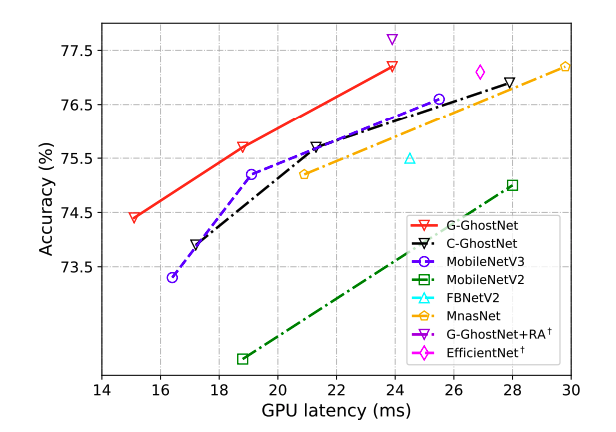
CPU-Efficient C-GhostNet
Toy Experiments

아래는 conv filter 에 따른 residual block의 일부 feature들에 있는 각 pair(red, green blue)의 MSE error 비교입니다. pair는 위 이미지에서 볼 수 있는 ghost들입니다.
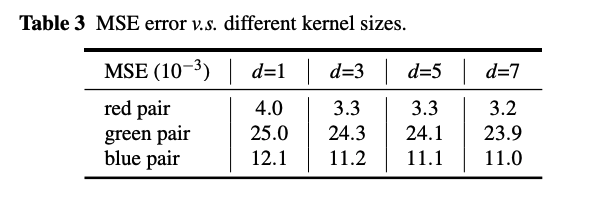
표에서 볼 수 있듯이 MSE 값이 아주 작습니다. 즉, 신경망의 feature map과 이런 redundant feature map들은 높은 연관성이 많은 intrinsic feature map에서 생겨난다는 의미입니다. 비슷한 현상들을 https://bit.ly/38jJtR6 에서도 볼 수 있습니다. 그리고, 위의 표는 conv를 사용한 것이고, 그외에도 C-Ghost 실험을 위해서 affine transformation이나 wavelet transformation등의 low-cost의 다양한 연산들을 사용해봤는데, 이미 현재의 하드웨어들이 conv에 충분히 효율적이고, 그 정도가 smoothing, bluring, motion같은 연산들하고 비슷한 정도라서 그냥 depthwise conv를 쓴다고 합니다.
(이 부분은 개인적으로 조금 아쉽고, 논문을 파악할 때 헷갈리는 점이였습니다. 왜냐하면, 앞부분에서는 정말 간단한 operation인 것처럼 얘기하고, 이제와서 다시 depthwise?라고...흠... )
그리고 아래는 depthwise의 filter d에 따른 결과 입니다.
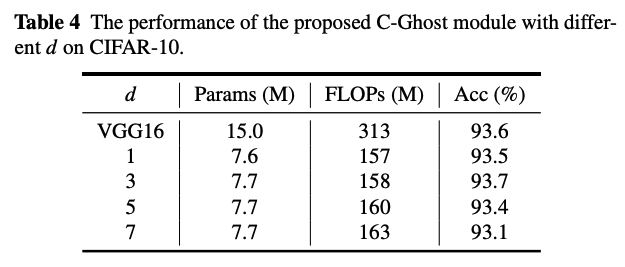
CIFAR-10 Experiments
저자들은 C-Ghost Module을 VGG16rhk ResNet 56구조에 맞춰서 실험해봤습니다. 그중 하이퍼 파라미터 d와 s를 변경해가며 분석했습니다.
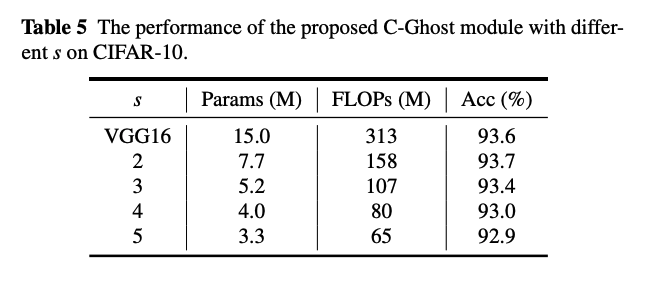
실험 결과에 따라 를 선택했고, 아래와 같은 결과를 얻었습니다.
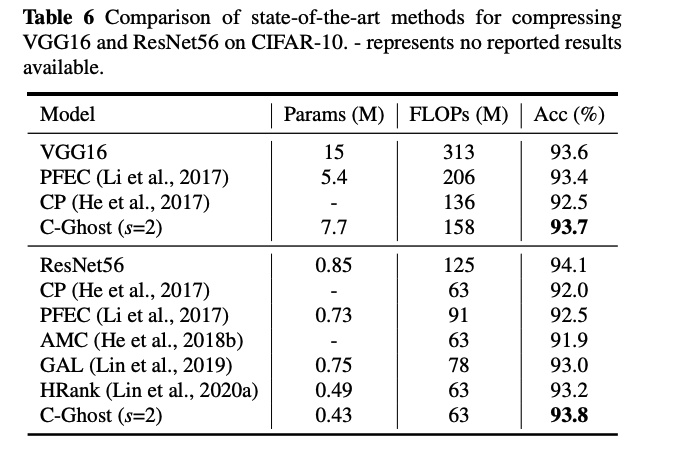
FLOPs가 작은데 성능이 다른 모델들에게 뒤쳐지지 않는 것을 볼 수 있죠.
위의 실험 중간에도 아래 그림처럼 일반 VGG16와 C-GhostNet-VGG16의 feature map들이 굉장히 비슷한 것을 볼 수 있습니다.

그 외에도 다음 Table에서 볼 수 있듯이 많은 실험에서도 효율적인 면을 보여줍니다.
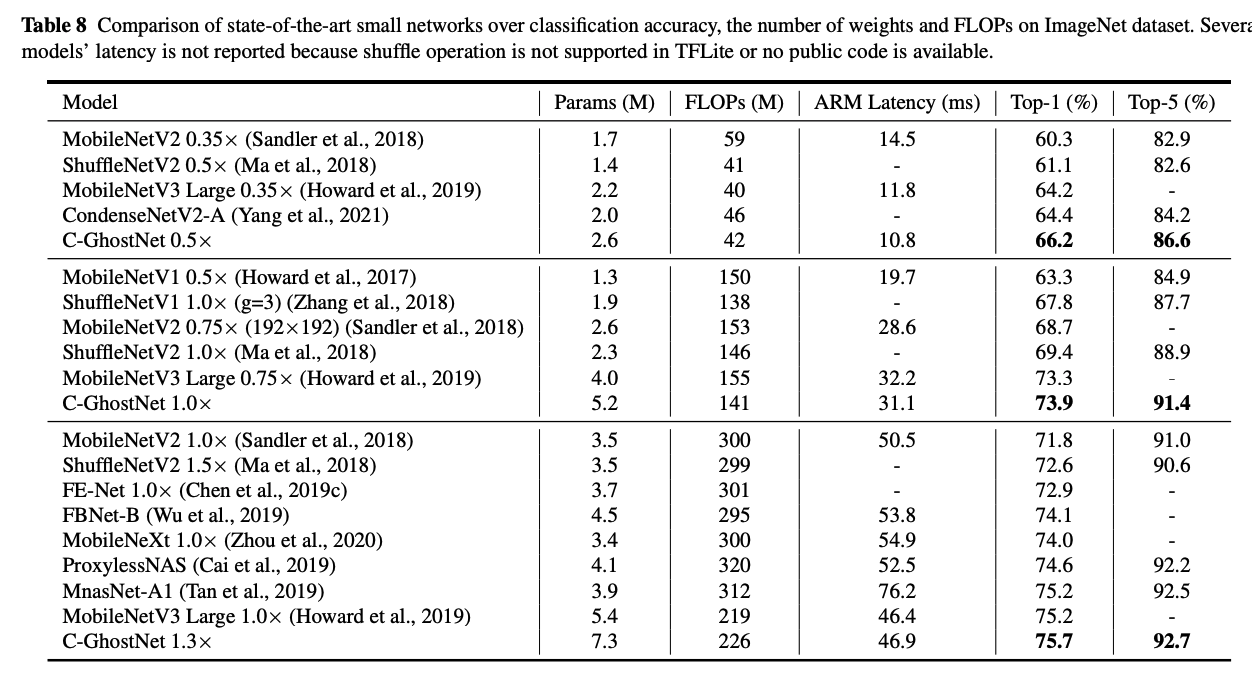
Actual Inference Speed

C-GhostNet이 Mobile에 맞게 설계되었고, 그에 맞는 실험을 위해서 ARM-based mobile환경에서 TFLite tool을 셋팅해서 관찰해보았는데요. 이미지 한장을 처리하는데 MobileNet V3보다 6ms빠른 40ms가 걸린다고 합니다.
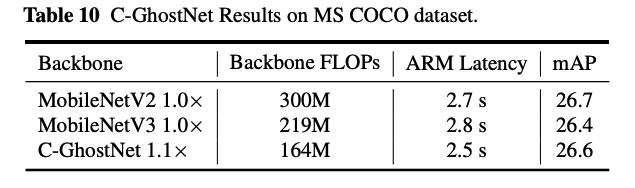
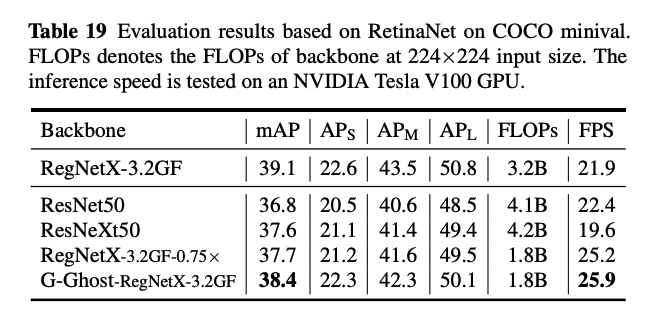
Generalization to Object Detection
GPU-Efficient G-Ghost Structure

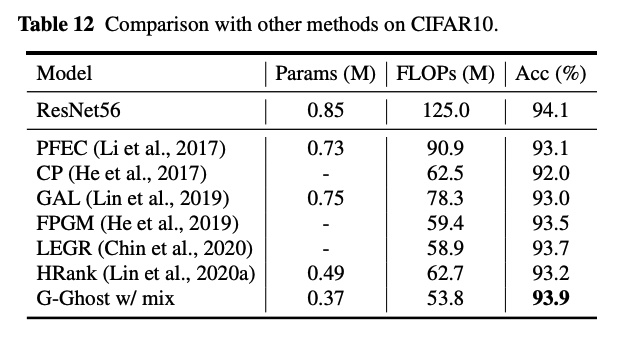
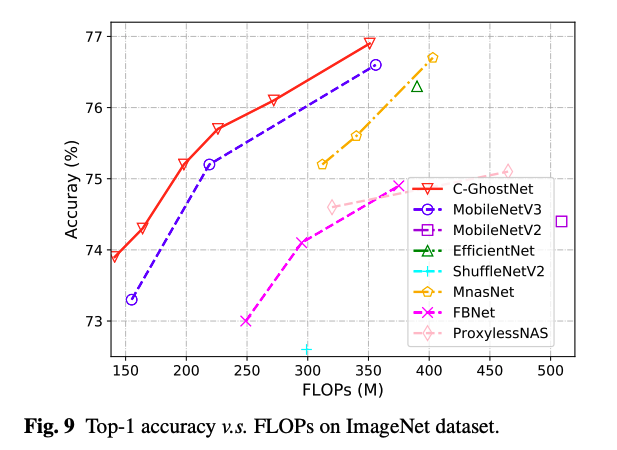
위의 성능적인 면은 빠르게 지나가고, 논문의 메인 아이디어인 cheap operation의 중요성을 보겠습니다.
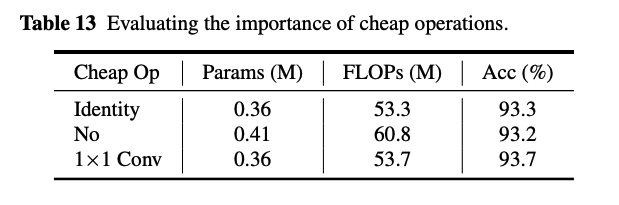
Identity mapping, 없는 경우, 을 넣은 경우인데요. 가 가장 좋습니다.

그리고, 필터 사이즈에 따른 결과로는 3일때가 가장 좋죠.

conv에서의 cheap operation 비율에 따른 실험경과로는 0.5가 연산량과 성능의 trade-off관계에서 가장 좋은 것을 보여줍니다.
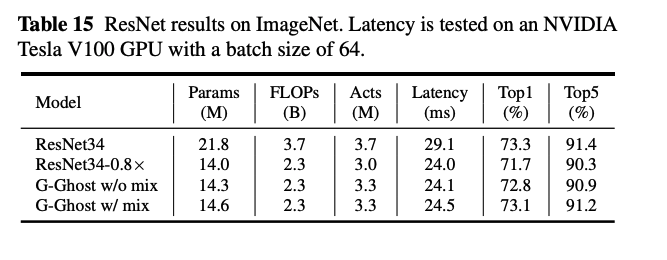
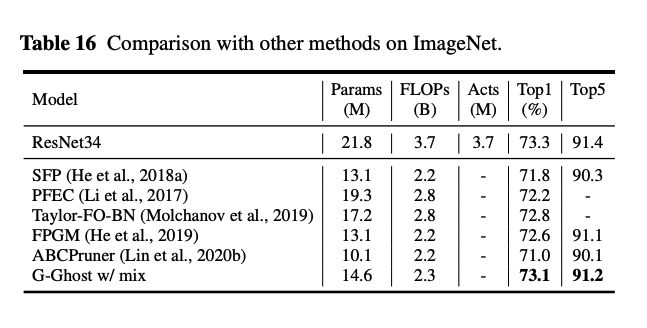
RegNet 😰😓😅
제가 타이틀에 이모티콘을 붙인 이유는 처음부터 논문에서 메인은 언급해줬으면 좋았을 걸 이제 마지막 부분에 특히 Experiments 부분에 넣은 것이 살짝 당황스럽기 때문입니다...
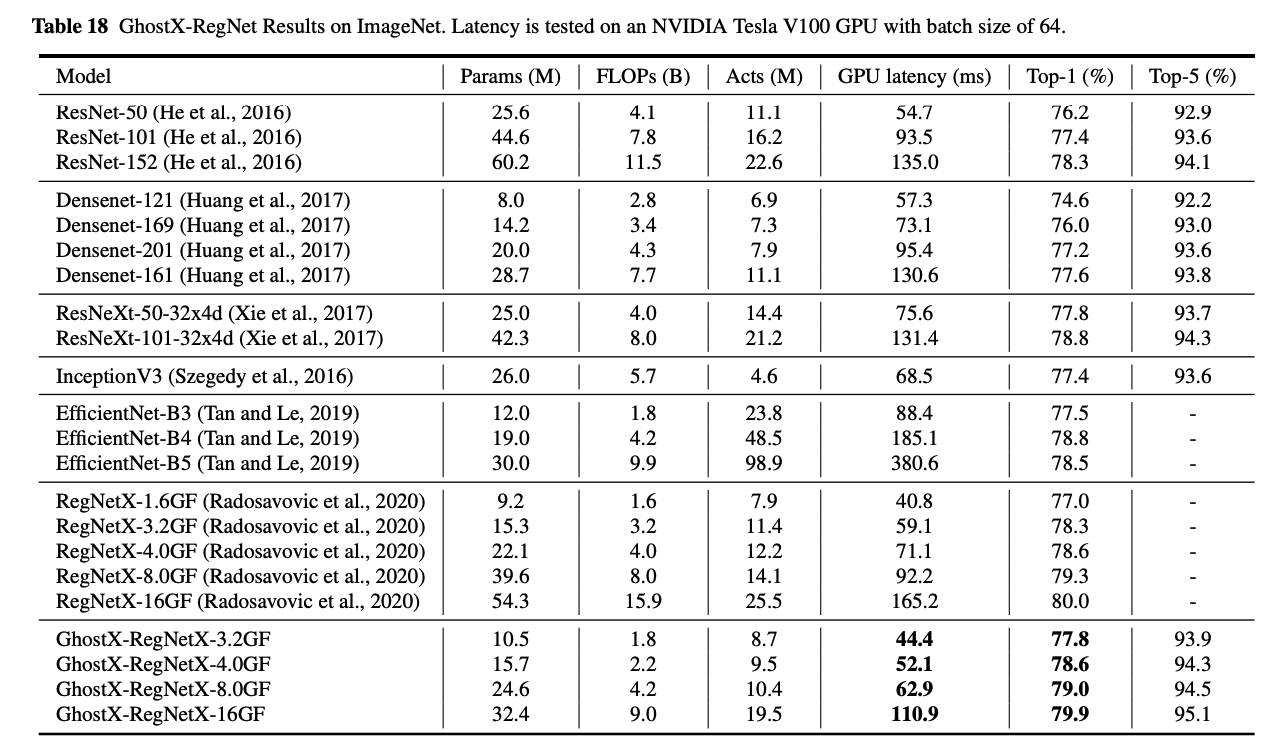
RegNet은 2020에 나온 network design의 구조 관점을 탐구하며 나오게 된 network들입니다. 완성된 G-GhostNet도 결국에는 이 신경망을 메인으로 채택해서 github에 가보면 이 구조로 만들어진 G-GhostNet밖에 없습니다.


많은 도움이 되었습니다, 감사합니다.