지난 논문 리뷰 VanillaNet, GhostNetV2에서 궁금증을 유발한 논문 GhostNet 입니다. CVPR 2020에 등재된 논문입니다. 이걸 먼저 리뷰했어야하는데 순서가 조금 그렇게 됐네요. 😅
https://arxiv.org/pdf/1911.11907.pdf
https://github.com/huawei-noah/Efficient-AI-Backbones
GhostNet도 아주 설명이 명료하게 잘 나와있어서 읽기 편했어요. 이미 속도와 정확도에서 보장된 성능을 보이는 MobileNet V3을 부분부분 Ghost Module으로 교체하면서 더 높은 성능을 낸 점에서 굉장히 인상 깊었습니다. 저도 연구를 하면서, 네트워크의 피쳐맵이 100% 유용한 정보만 있을거라고 생각하진 않았는데, 그 부분을 딱 건드려주시니 속도 조금 시원하기도 했습니다ㅋㅋㅋㅋ 감사합니다 😊
아 그리고 2022버전의 GhosNets라고 해서 CPU에 맞춘 C-GhostNet, GPU에 최적화된 G-GhostNet을 연구했는데, 다음번에 시리즈 느낌으로 또 리뷰를 해볼 예정입니다.
Introduction
CNN의 개발을 시작으로, 그 네트워크들을 compact하게 만드는 방법(pruning, quantization, knowledge distillation, ...)의 발전을 이야기합니다. 하지만 이런 방법들은 pretrained된 네트워크가 기반이 되어야하는 점을 꼬집습니다. 또는 automatic하게 만들어진 MobileNet이라던가 ShuffleNet도 언급합니다.

그러면서, 얘기하고 싶은 바를 지금부터 드러냅니다. 잘 학습된 NN feature map의 풍부(Abundant)하기도 하면서 때로는 불필요(redundant)한 정보들이 input 데이터를 포괄적으로 표현하죠. 그런데, Figure 1에서 보이는 것처럼 ResNet-50에 input image를 넣었을때, 비슷한 feature map들이 있는 것을 볼 수 있고 마치 서로가 서로간의 ghost 같죠. feature map의 Redundancy는 중요한 특징될 수 도 있기 때문에, 저자들은 이런 점들을 cost가 적게 효율적으로 살리기를 원합니다.
그래서, 해당 논문에서는 Ghost Module을 이용해서 적은 parameter로 더 많은 피쳐를 찾는 방법을 연구했습니다. 특히, 일반적인 conv를 두 파트로 나누는 방법을 씁니다. 첫 파트에서는 일반적인 conv이지만, parameter 수를 아주 엄격하게 통제합니다. 이렇게 첫번째에서 나온 feature map을 연속된 간단한 linear 연산들을 통해 더 많은 feature map들을 만들어 냅니다. 이 모듈은 필요한 parameter와 연산 복잡도가 줄어들게 해주고, 이 모듈을 모아서 GhostNet을 완성했습니다.
Approach
Ghost Module for More Features
기존의 CNN들은 conv 수가 너무 많고, MobileNet과 ShuffleNet같은 최근의 NN들은 상당한 memory와 FLOPs가 필요로 하죠. 그리고 앞서 언급된 것처럼, 중간 feature map들에는 redundancy가 존재합니다. input 가 있고 conv filter 가 있을때 일반적으로 아래식으로 표현되죠.
그럼 이때의 FLOPs는 임으로 보통 channel 수가 256, 512면 그 수가 수십만이 되는건 당연합니다.

Figure 2(a)에서 표현된 일반적인 conv는 그 많은 FLOPS을 가지고 redundant feature map을 만들어 내죠. (비효율적!!)
output feature들을 몇몇의 cheap한 연산들의 내부 feature map들을 "ghosts"라고 가정해봅니다. 이런 intrinsic feature map들은 일반적인 conv에 의해 만들어지며, 사이즈가 작죠. 특히 m개의 intrinsic feature map 는 다음과 같이 표현됩니다.
그리고, 이후 n개의 feature map을 얻기 위해서, 저자들은 의 intrinsic feature 각각에 대해 연속적인 cheap linear 연산들을 적요하여 아래 식처럼 ghost feature를 만들기로 하죠.
- : i번째 intrinsic feature map
- : j번째 ghost feature map 마지막을 제외한 j 번째 linear연산
- 즉, 는 한개 이상의 ghost feature map를 가질 수 있습니다.
- 마지막, 마지막 figure 2(b)에서 보여지는 intrinsic feature map을 만드는 identity mapping 입니다.
위의 식에 따르면, ghost module의 output data인 ()개의 feature map 을 얻을 수 있죠. 게다가, 가 일반 conv보다 훨씬 적은 연산량이 들죠.
Difference from Existing Methods
- 1 x 1 pointwise 사용하는 MobileNets, ShiffleNets과 다르게, 커스텀 kernel size를 사용합니다.
- pointwise후 depthwise를 쓰는 것이 아니고, 첫번째의 적은 intrinsic feature map을 만들기 위해 일반적인 conv를 쓰고, 그 후에는 여러 cheap linear 연산들로 feature를 보충하고 channel을 증가시킵니다.
- feature을 제한하기 위해서 depthwise나 shift연산을 하는 것이 아니고, linear 연산들이 큰 diversity를 가지게 합니다.
- 추가로, indentity mapping은 ghost module의 linear transformations들로 intrinsic feature map을 보존합니다.
Analysis on Complexities
하나의 identity mapping과 개의 linear operation들이 있고, 각 linear연산의 평균 kernel size를 라고 하면, 개의 linear 연산들은 각각 다른 shape과 parameter를 가지지만, CPU와 GPU도 생각을 해줘야하긴 하죠.
이상적으로 계산을 해보면 이론적인 speed-up 비율은 아래와 같이 계산할 수 있습니다.
Building Efficient CNNs
Ghost Bottlenecks

Ghost Module의 이점을 가져가기 위해 작은 CNN모델을 위한 Ghost Bottleneck(G-neck)을 도입했다고 합니다. Figure 3에서 보이듯이, Ghost bottleneck은 resnet의 residual block과 비슷합니다. 제안한 Ghost Bottleneck은 두개의 ghost module로 이루어져 있고, 첫번째는 channel 수를 늘리는 expension layer 역할을 하며, 위에서 언급된 비율 만큼 output channel을 늘립니다. 두번째 모듈은 shortcut에 맞춰서 채널 수를 줄여줍니다. 그리고 BN과 ReLU도 그림처럼 넣어줍니다. 그리고 stride에 따라 조금은 다른데, 1은 앞서 언급한 방식이지만 stride=2일때는, downsampling과 depthwise conv가 중간에 들어가죠. 실제로, 첫번째 conv는 효율성을 위해 pointwise conv를 씁니다.
GhostNet
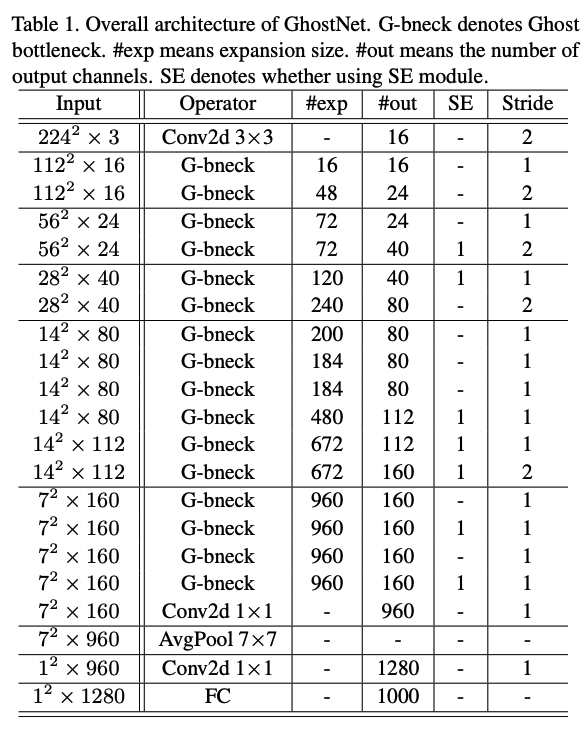
위의 표를 GhostNet의 전체 구조라고 보시면 됩니다. 보실때, 위의 내용들을 참고하면서, 어떤 부분들이 MobileNet V3에서 대체됐는지 보시면 좋습니다.
Width Multiplier
위의 모델이 이미 빠른 속도와 보장된 정확도를 보이긴 하지만, 더 작은 모델이나 어느정도 조절이 필요할때 width multiplier 를 channel에 가볍게 곱해주는 형식으로 하면 됩니다. 그리고 그 GhostNet의 이름은 GhostNet-라고 붙여주면 되구요.
Experiments
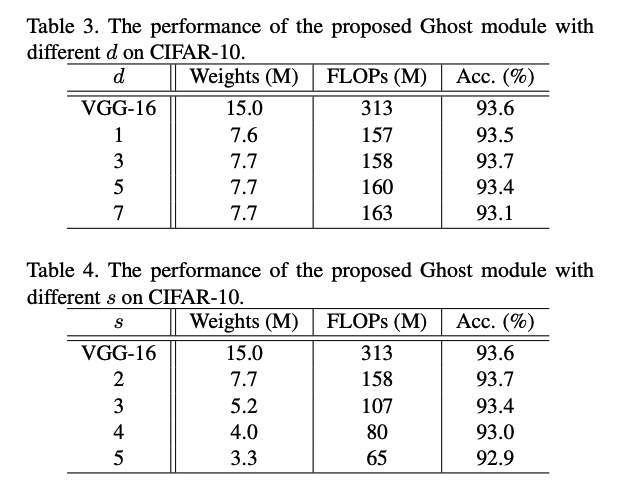
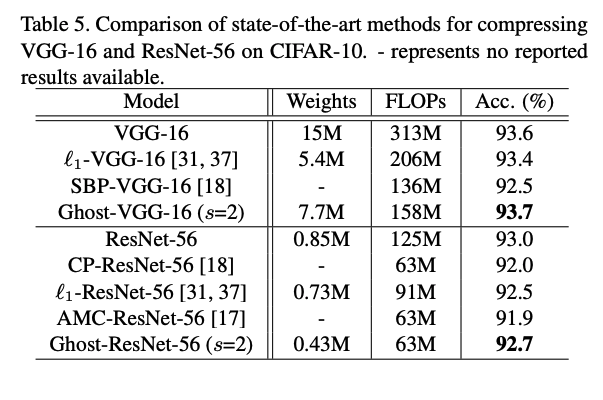
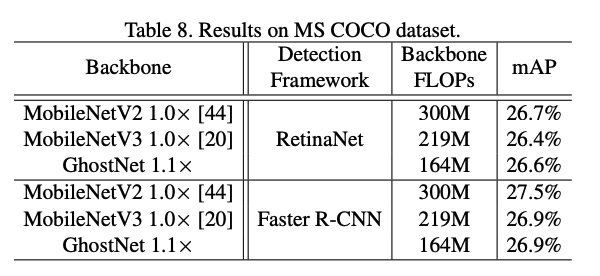
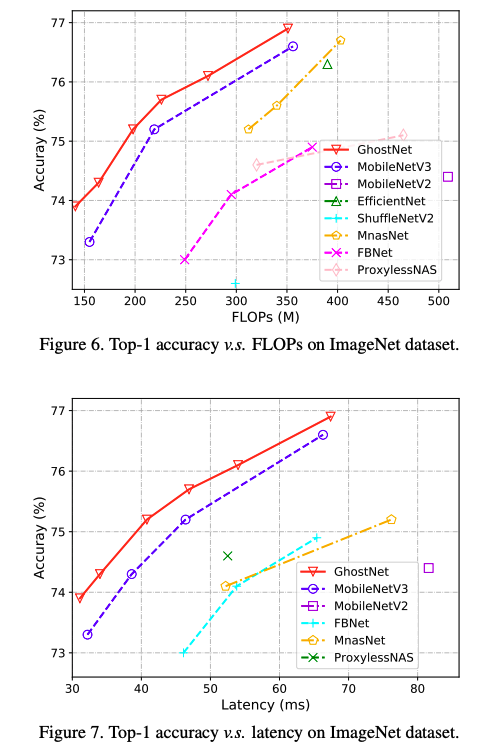
다음은 GhostNet의 실험과 성능 지표들입니다.