[논문] Object pop-up: Can we infer 3D objects and their poses from human interactions alone?

오늘은 발상의 전환에서 정말 흥미롭다고 생각한 논문을 리뷰해보려고 합니다. Human Object Interaction(HOI) 분야에서 많은 사람들이 가장 흔하게 초점을 두는 것은 Object인데요. 예를 들어서, 의자가 있으면 앉아야하고, 컵이 있으면 손으로 쥐어야하는 것처럼 대부분 Object에 따라서 사람의 포즈를 매칭시키려고 합니다. 그런데, 오늘 리뷰할 튀빙겐(Tubingen) 대학의 Real Virtual Human 연구소에서는, 기존의 관점과 다르게, 사람의 포즈에 초점을 두고, 그에 맞게 Object를 배치하거나, 필요에 따라, 특정 Object를 추정하는 방법을 제안합니다. 이런 생각을 한다는 것 자체가 너무 놀랍지 않나요?
그리고, 또 하나, 얘기해보고 싶은 건, 최근 Human pose의 연구 분야가 HOI로도 많이 확장되었다는 것이외에도, Point Cloud를 많이 활용 한다는 점 입니다. 이전에는 하드웨어 기술이 부족하거나, 또는 데이터 취득의 어려움등으로 Point Cloud관련 연구가 많지 않았습니다. 하지만, 요즘은 이러한 문제들이 많이 보완되어서, RGB 단일 이미지보다 3D 좌표를 얻기 용이하고, 객체간의 상대적인 위치 관계를 좀 더 쉽게 알 수 있죠. 아직 아쉬운 점은, 일반인들에게 아직까지는 친숙하지 않다는 점입니다. 그래서 이러한 선행연구들이 나중에는 우리 삶에 스며들지 않을까 생각합니다.
https://virtualhumans.mpi-inf.mpg.de/object_popup/
https://arxiv.org/pdf/2306.00777.pdf
Introduction

저자는 Object 중심이 아닌, 사람의 포즈 중심의 Human Object Interaction을 연구하고자 합니다. 그 이유는 사람의 행동에서도 충분히 어떤 물건인지, 또는 물이 어떻게 위치해야하는지를 우리가 유추할 수 있는 것처럼, 모델도 그렇게 추정할 수 있을 것이기 때문이죠.

Fig 1.에서 Ref.이미지들을 보면, 첫번째는 아마도 망원경을 쓰고 있는 것 같고, 세번째는 컵 같은 것을 들고 마시는 것이겠다 싶죠. 그리고 더 나아가서, 그런 물체들의 어떤 부분이 사람의 어느 부분에 접촉되어 있을 것인가도 어느정도 가늠이 되죠. 이런 점에서 생각해보면, 최근 많이 연구되고 있는 VR/AR 분야에서 이러한 접근법이 더 맞지 않을까요? VR기기를 쓰고, 우리가 가상의 망치를 잡는데, 그 망치에 우리가 딱 맞춰서 잡을 수 없자나요. 그러니까 우리가 잡는 시늉을 하면, 망치가 알아서 "뿅"(Pop-Up)하고손에 잘 쥐어져 있어야죠.
저자들이 위와 같은 목표를 달성하기위해 한 연구를 다음 main contribution으로 정리할 수 있습니다.
- 기존 연구와는 다른 관점의 연구 진행
- human point cloud에서 object의 추정
- human-object 관계의 다른 요소 분석: hand / body / time sequence측면에서의 interaction, input points의 point-wiae saliency와, 비슷한 기능들을 하는 object들간의 혼동
Method
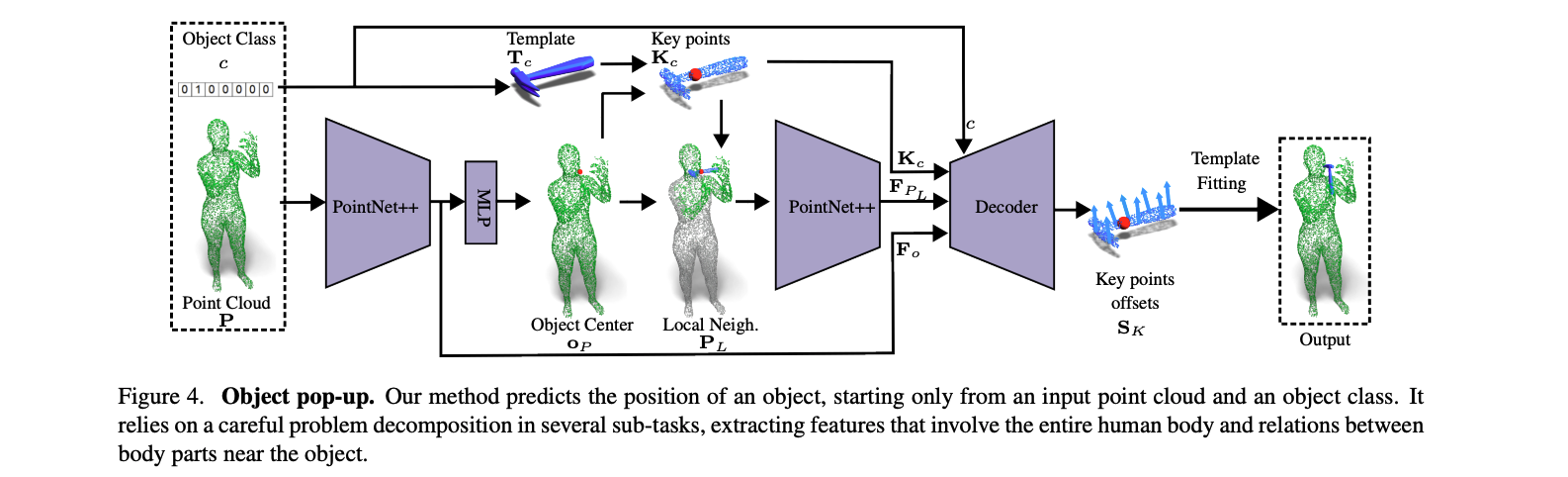
Object Pop-Up
Input
- a single human point cloud
- from 3D/4D scan, IMUs template fitting or other shape-from-X
- hot encoded object class
- class에 따른 템플릿 mesh에서 1500개의 point 로 object 표현
Object Center
human point cloud에서 object pose를 추정하는 것은 쉽지 않습니다. 이런 task는 각각 다른 신체 부분과 그들의 관계를 이해하고 spatial한 관계를 인지하는 network가 필요합니다. 저자들의 경험에 따르면, 이러한 관계들을 하나 하나의 process로 분해하여 진행하는 것이 가장 좋았다고 합니다.
첫번째로, pointNet++를 학습하여 에서 object center 르 추정하도록 학습합니다. 이때, 사용된 loss는 L2 lossd입니다.
물체의 중심 이외에도, 추출된 feature 는 사람의 whole body에 대한 정보를 encode하는 역할을 합니다.
Local NeighborHood
위 단계에서 추정된 center는 사람의 가까운 영역에서 contact정보나 물체에는 닿지 않지만 영향이 있는 body part를 고려해야됩니다. (예를 들면, 망원경을 사용하고 있을때, 직접닿는 손 이외에도, 머리의 각도나 위치도 중요하겠죠.) 이러한 정보를 잘 파악하기 위해, 가장 가까운 3000개의 point로 이루어진 point cloud 를 KNN을 이용하여 구합니다. 그리고 이 point들을 PointNet++에 입력하여 새로운 point feature 를 추출합니다.
Object displacement
이제 마지막으로, 물체의 최종 위치를 추정해야하는데, 저자들은 단순하게 rotation이나 translation을 구하는 것이 좋지 않다는 것을 발격했습니다. 대신에, 이들은 point-wise offset을 구하는 방법을 제안하였습니다. 즉, 의 꼭지점을 target pose에 맞도록 정렬할 수 있는 point-wise shift 를 구하는거죠. 이때 사용된 방법은 이전에 추출한 와 과 물체에 관한 와 를 입력으로 받아 decoder에 입력하는 것입니다. 학습시에는 아래와 같은 loss를 이용합니다.
전체 network의 end-ro-end의 loss 관계는 아래와 같고, 실험시 설절된 weight 상수 입니다.
Templete fitting
Procrutes alignment
point-wise offset은 keypoint 구조를 왜곡할 수 있는데, 이 문제를 보완하기 위해서 Procrutes alignment를 사용하였습니다. 이 과정은 두 point cloud를 입력으로 받아 rotation 과 translation 를 반환하여, point들간의 L2 distance를 최소화합니다.
최종적으로, object의 pose를 복원할 수 있게 됩니다.
Time Smoothing
저자들이 제안한 방법 single point cloud를 입력으로 받기 때문에, 시간축에 따른 약점이 있을 수 있어, smoothing을 후처리로 해줍니다. 이때 사용하는 smoothing 기법은 Gaussian kernel을 이용합니다.
Experiments
Datasets
- BEHAVE, GRAB
Implementation details
- Pytorch
- Nvidia RTX3090 GPU
- Adam optimizer for 60 epochs
Object classification
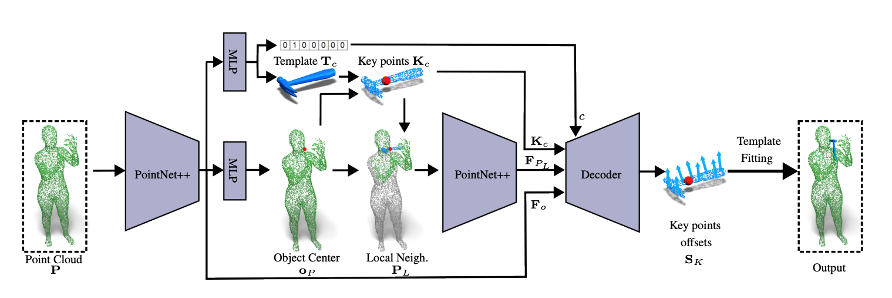
저자들은 또하나의 기능이 추가하였는데, 와 을 통하여, object class까지 추정하도록 하였습니다. 예를 들면, 두 손을 각각 말아 눈에 갖다 대면, 모델이 알아서 망원경이라고 인식하는 거죠.
Metrics
Vertex-to-vertex
추정된 object와 GT의 꼭지점 개수가 같으므로, 두 에러를 사용합니다.
Chamber distance
추정한 물체와 target object의 class가 다를 때, vertice의 개수가 다르므로, 아래 방식을 사용합니다.
Object Pose Evaluation


