IFC
1.BIM/GIS - IFC(Industry Foundation Classes)

BIM > BIM(Building Information Modeling, 빌딩 정보 모델링)은 건축, 엔지니어링, 시공(AEC) 산업에서 3D 모델 기반의 데이터 중심 설계를 수행하는 기술 및 프로세스이다. 단순한 3D 모델이 아니라, 각 요소(벽, 창문, 기둥 등)에
2.BIM/GIS - IFC 구조

IFC파일은 객체지향 기법을 적용하여 객체 구성요소인 건물, 지붕, 벽, 문 등의 객체와 그 객체들 간의 관계를 express 언어 기반의 구조화된 스키마로 정의되어있다. 이전 게시글에서 얘기했던 것과 같이 IFC 파일은 벽, 문, 창문 등의 객체들로 구성되어있다.
3.BIM/GIS - IFC Georeferencing(1)

IFC는 설계를 위한 목적의 형식이기 때문에 벽, 창문, 계단, 재질 등과 같이 건물을 이루는 객체에 대한 정보뿐만 아니라 이기 때문에 좌표 정보도 갖고있다. 벽이나 창문의 크기를 임의로 마음대로 설계할 수는 없지 않는가? BIM은 설계 목적이 무엇이냐에 따라 달라진
4.[1] CAD/PDF 도면 텍스트 추출 기술, 어디까지 와 있을까?
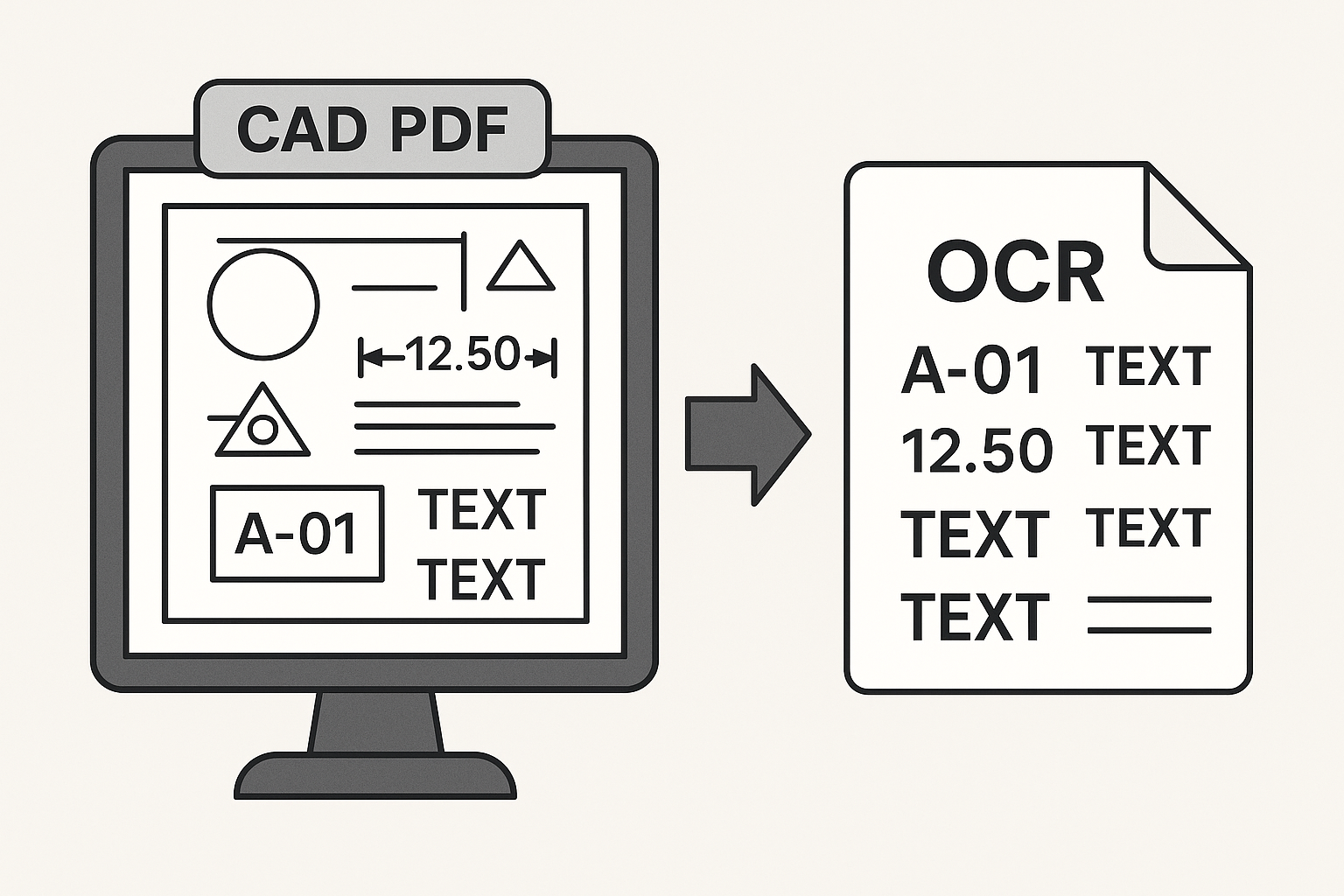
CAD 데이터에서 가장 원초적이면서도 가장 난도가 높은 작업이 바로 텍스트를 읽어내는 일이다.CAD PDF를 열어보면 텍스트가 잘 보인다. 폰트도 있고, 치수도 잘 보이고, 주석도 있다.그런데 막상 이걸 프로그램으로 읽어보려고 하면 금세 현실을 맞닥뜨린다.도면 속 텍스
5.[1] CAD/PDF 도면 텍스트 추출 기술, 어디까지 와 있을까? - 2
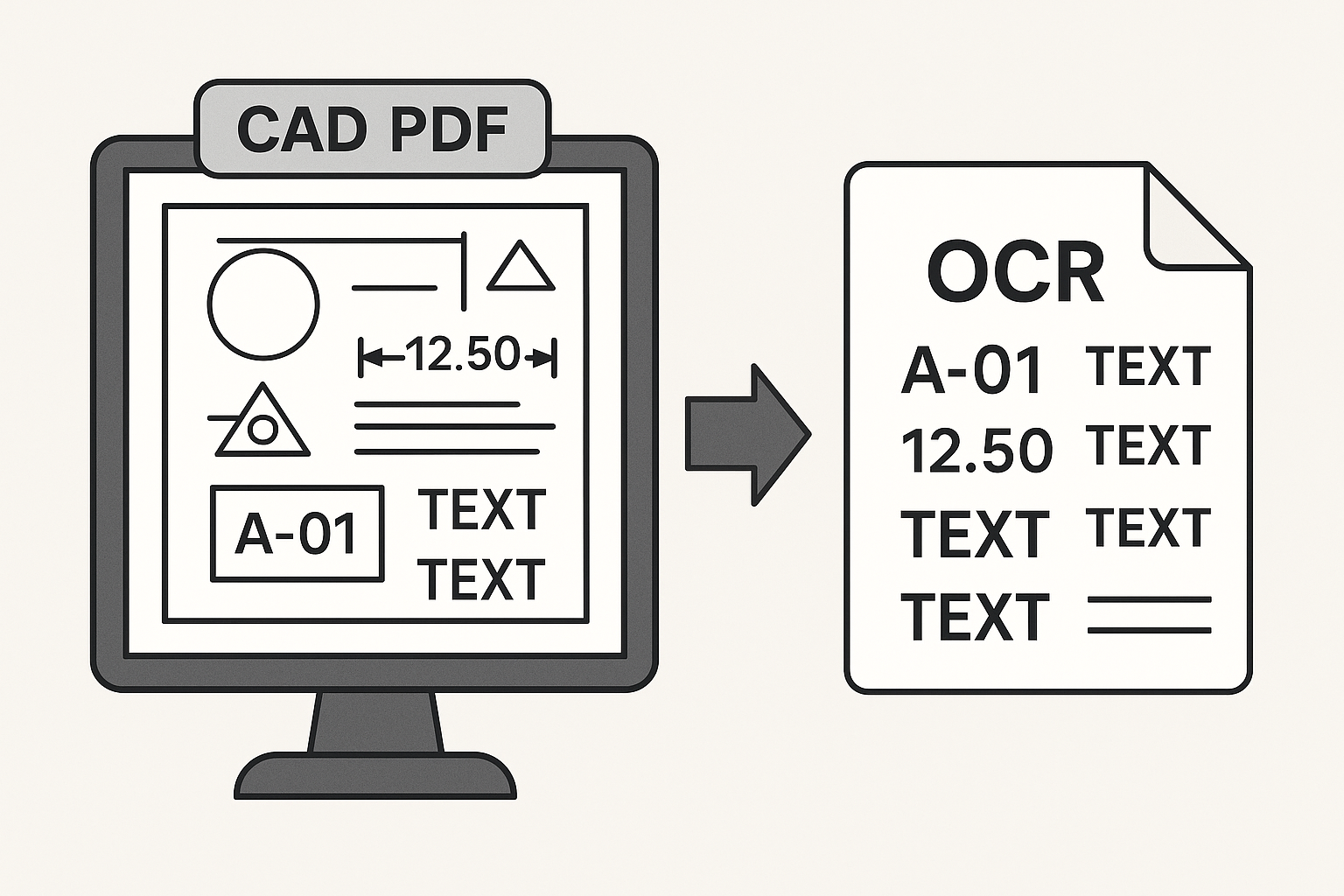
CAD·BIM 연계를 위해 OCR 기술을 조사하기 시작했을 때, 처음 마주한 인상은 “생각보다 훨씬 넓고 깊은 분야구나”였다.텍스트를 읽는 일은 너무 기본적인 문제처럼 보이지만, 실제로는 컴퓨터 비전과 NLP가 동시에 얽혀 있는 복합적인 영역이다.그 복잡한 판을 가장
6.[2] 엔지니어링 도면 OCR 연구들은 무엇을 하고 있을까?
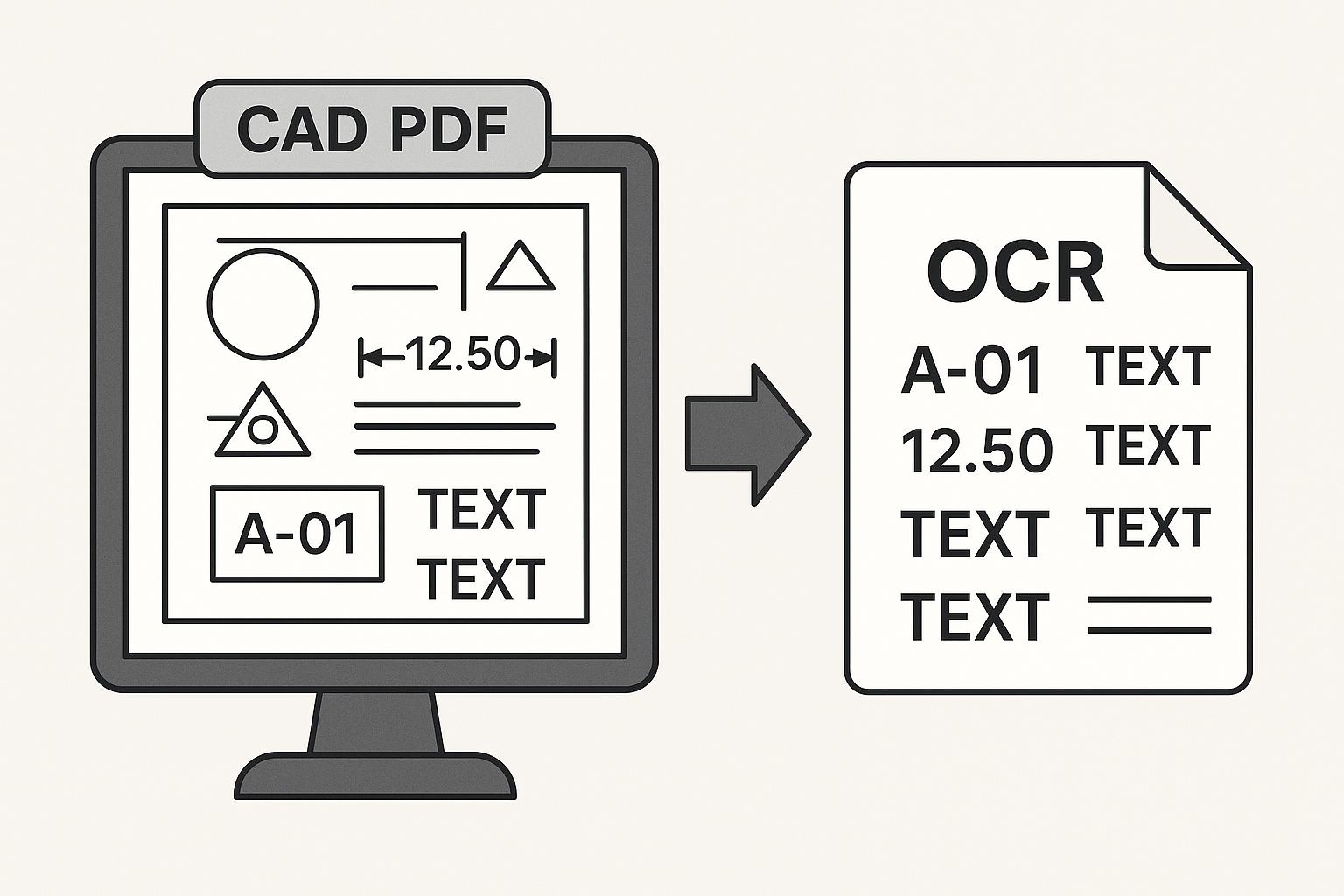
앞선 글에서는 CAD/PDF 도면에서 OCR이 왜 어려운 문제인지,그리고 문서 OCR과 도면 OCR이 근본적으로 다른 문제라는 점을 살펴봤다.이번 글에서는 그 다음 단계로 이 문제를 직접 다뤄온 엔지니어링 도면 OCR 연구들이 어떤 방향으로 접근해왔는지를 정리해보려 한